MySQL 高效插入數據的優秀實踐
在當今數據驅動的時代,高效的數據處理尤其是數據插入操作對于各類應用系統的性能表現至關重要。當我們聚焦到 MyBatis 這個強大的框架時,探索其高效插入數據的方法就成為了提升系統效率的關鍵一環。
隨著業務的不斷發展和數據量的持續增長,我們常常面臨著如何在保證數據準確性的前提下,盡可能快速地將大量數據插入到數據庫中的挑戰。MyBatis 作為一款廣泛應用的持久層框架,提供了多種途徑和策略來實現高效的插入操作。在接下來的文章中,我們將深入剖析 MyBatis 在高效插入數據方面的獨特之處,從基本原理到實際應用技巧,逐一揭開其神秘面紗。無論是新手開發者還是經驗豐富的技術人員,都能從這里獲得對 MyBatis 高效插入數據更深入的理解和實用的指引,從而為構建更高效、更穩定的系統奠定堅實的基礎。

一、關于MySQL批量插入的一些問題
MySQL一直是我們互聯網行業比較常用的數據,當我們使用半ORM框架進行MySQL大批量插入操作時,你是否考慮過這些問題:
- 進行大數據量插入時,是否需要進行分批次插入,一次插入多少合適?有什么判斷依據?
- 使用foreach進行大數據量的插入存在什么問題?
- 如果插入批量插入過程中,因為服務器宕機等原因導致插入失敗要怎么辦?
基于此類問題,筆者以自己日常的開發手段作為依據演示一下MySQL批量插入的技巧。
二、常見的三種插入方式演示
1. 實驗樣本數據
為了演示,這里給出一張示例表,除了id以外,有10個varchar字段,也就是說全字段寫滿的話一條數據差不多1k左右:
CREATE TABLE `batch_insert_test` (
`id` int NOT NULL AUTO_INCREMENT,
`fileid_1` varchar(100) DEFAULT NULL,
`fileid_2` varchar(100) DEFAULT NULL,
`fileid_3` varchar(100) DEFAULT NULL,
`fileid_4` varchar(100) DEFAULT NULL,
`fileid_5` varchar(100) DEFAULT NULL,
`fileid_6` varchar(100) DEFAULT NULL,
`fileid_7` varchar(100) DEFAULT NULL,
`fileid_8` varchar(100) DEFAULT NULL,
`fileid_9` varchar(100) DEFAULT NULL,
`fileid_10` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 COMMENT='測試批量插入,一行數據1k左右';
2. 使用逐行插入
我們首先采用逐行插入方式分別插入3000、10w條的數據,這里為了保證實驗的準確性,提前進行代碼預熱,先插入5條數據,然后在進行大批量的插入:
/**
* 逐行插入
*/
@Test
void rowByRowInsert() {
//預熱先插入5條數據
performCodeWarmUp(5);
//生成10w條數據
List<BatchInsertTest> testList = generateBatchInsertTestData();
long start = System.currentTimeMillis();
for (BatchInsertTest test : testList) {
batchInsertTestMapper.insert(test);
}
long end = System.currentTimeMillis();
log.info("逐行插入{}條數據耗時:{}", BATCH_INSERT_SIZE, end - start);
}輸出結果如下,可以看到當進行3000條數據的逐條插入時耗時在3s左右:
逐行插入3000條數據耗時:3492而逐行插入10w條的耗時將其2min,插入表現可以說是非常差勁:
05.988 INFO c.s.w.WebTemplateApplicationTests:55 main 逐行插入100000條數據耗時:1196783. 使用foreach語法實現批量插入
Mybatis為我們提供了foreach語法實現數據批量插入,從語法上不難看出,它會遍歷我們傳入的集合,生成一條批量插入語句,其語法格式大抵如下所示:
insert into batch_insert_test (id, fileid_1, fileid_2, fileid_3, fileid_4, fileid_5, fileid_6, fileid_7, fileid_8, fileid_9, fileid_10)
values (1, '1', '2', '3', '4', '5', '6', '7', '8', '9', '10'),
(2, '1', '2', '3', '4', '5', '6', '7', '8', '9', '10'),
(3, '1', '2', '3', '4', '5', '6', '7', '8', '9', '10');批量插入代碼如下所示:
/**
* foreach插入
*/
@Test
void forEachInsert() {
/**
* 代碼預熱
*/
performCodeWarmUp(5);
List<BatchInsertTest> testList = generateBatchInsertTestData();
long start = System.currentTimeMillis();
batchInsertTestMapper.batchInsertTest(testList);
long end = System.currentTimeMillis();
log.info("foreach{}條數據耗時:{}", BATCH_INSERT_SIZE, end - start);
}對應xml配置如下:
<!-- 插入數據 -->
<insert id="batchInsertTest" parameterType="java.util.List">
INSERT INTO batch_insert_test (fileid_1, fileid_2, fileid_3, fileid_4, fileid_5, fileid_6, fileid_7, fileid_8, fileid_9, fileid_10)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.fileid1}, #{item.fileid2}, #{item.fileid3}, #{item.fileid4}, #{item.fileid5},
#{item.fileid6}, #{item.fileid7}, #{item.fileid8}, #{item.fileid9}, #{item.fileid10})
</foreach>
</insert>實驗結果如下,使用foreach進行插入3000條的數據耗時不到1s:
10.496 INFO c.s.w.WebTemplateApplicationTests:79 main foreach3000條數據耗時:403當我們進行10w條的數據插入時,受限于max_allowed_packet配置的大小,max_allowed_packet定義了服務器和客戶端之間傳輸的最大數據包大小。該參數用于限制單個查詢或語句可以傳輸的最大數據量,我們通過show VARIABLES like '%max_allowed_packet%';默認情況下為67108864大約6M左右,所以這也最終導致了這10w條數據的插入直接失敗了。
Error updating database. Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (106,100,142 > 4,194,304). You can change this value on the server by setting the 'max_allowed_packet' variable.4. 使用批處理完成插入
再來看看筆者最推薦的一種插入方式——批處理插入,批處理的工作原理是在一次SQL連接通信提交多條SQL執行語句,通過減少網絡往返的開銷來提升SQL執行效率的一種手段,需要注意使用批處理的時候需要注意以下幾點:
- 批處理會以批次為單位提交SQL執行語句,如果涉及大批量的批處理大查詢操作,SQL服務器內存資源存在被這批次查詢耗盡的風險。
- 批處理提交或者查詢的數據過大時會導致傳輸包過大,也可能導致網絡傳輸耗時長的問題。
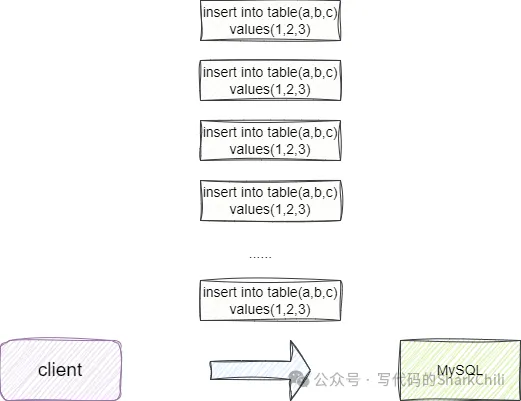
在正式介紹這種插入方式前,讀者先確認自己的鏈接配置是否添加了這條配置語句,只有在MySQL連接參數后面增加這一項配置才會使得MySQL5.1.13以上版本的驅動批量提交你的插入語句。
rewriteBatchedStatements=true完成連接配置后,我們還需要對于批量插入的編碼進行一定調整,Mybatis默認情況下執行器為Simple,這種執行器每次執行創建的都是一個全新的語句,也就是創建一個全新的PreparedStatement對象,這也就意味著每次提交的SQL語句的插入請求都無法緩存,每次調用時都需要重新解析SQL語句。 而我們的批處理則是將ExecutorType改為BATCH,執行時Mybatis會先將插入語句進行一次預編譯生成PreparedStatement對象,發送一個網絡請求進行數據解析和優化,因為ExecutorType改為BATCH,所以這次預編譯之后,后續的插入的SQL到DBMS時,就無需在進行預編譯,可直接一次網絡IO將批量插入的語句提交到MySQL上執行。
@Autowired
private SqlSessionFactory sqlSessionFactory;
/**
* session插入
*/
@Test
void batchInsert() {
/**
* 代碼預熱
*/
performCodeWarmUp(5);
List<BatchInsertTest> testList = generateBatchInsertTestData();
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
BatchInsertTestMapper sqlSessionMapper = sqlSession.getMapper(BatchInsertTestMapper.class);
long start = System.currentTimeMillis();
for (BatchInsertTest batchInsertTest : testList) {
sqlSessionMapper.insert(batchInsertTest);
}
sqlSession.commit();
long end = System.currentTimeMillis();
log.info("批處理插入{}條數據耗時:{}", BATCH_INSERT_SIZE, end - start);
}可以看到進行3000條數據插入時,耗時也只需只需179ms左右:
05.226 INFO c.s.w.WebTemplateApplicationTests:108 main 批處理插入3000條數據耗時:179而進行10w條數據批處理插入的時機只需4s左右,效率非常可觀。
04.771 INFO c.s.w.WebTemplateApplicationTests:108 main 批處理插入100000條數據耗時:4635三、更高效的插入方式
因為Mybatis對于原生批處理操作做了很多的封裝,其中涉及很多校驗檢查和解析等繁瑣的流程,所以通過使用原生JDBC Batch來避免這些繁瑣的解析、動態攔截等操作,對于MySQL批量插入也會有顯著的提升。感興趣的讀者可以自行嘗試,筆者這里就不多做演示了。
四、詳解批處理高效的原因
針對上述三種方式,筆者來解釋一下為什么在能夠確保不出錯的情況下,批處理插入的效率最高,我們都知道MySQL進行插入操作時整體的耗時比例如下:
鏈接耗時 (30%)
發送query到服務器 (20%)
解析query (20%)
插入操作 (10% * 詞條數目)
插入index (10% * Index的數目)
關閉鏈接 (10%)由此可知,進行SQL插入操作時,最耗時的操作是網絡連接,這也就是為什么在進行3000條數據插入時,foreach和批處理插入的性能的性能表現最出色。因為逐行插入提交時,每一條插入操作都會進行至少兩次的網絡返回(如果生成的是stament對象則是兩次,PreparedStatement則還要加上預編譯的網絡往返),在大量的插入情況下,所有的語句都需要經歷一次最耗時的鏈接操作,性能自然是下降了不少。

這里筆者給出逐條插入的時的執行調試日志,可以看到每條插入都會進行一次預編譯:

相比之下批處理和foreach一次預編譯加上一次網絡往返即可完成SQL執行,效率自然是上去的:
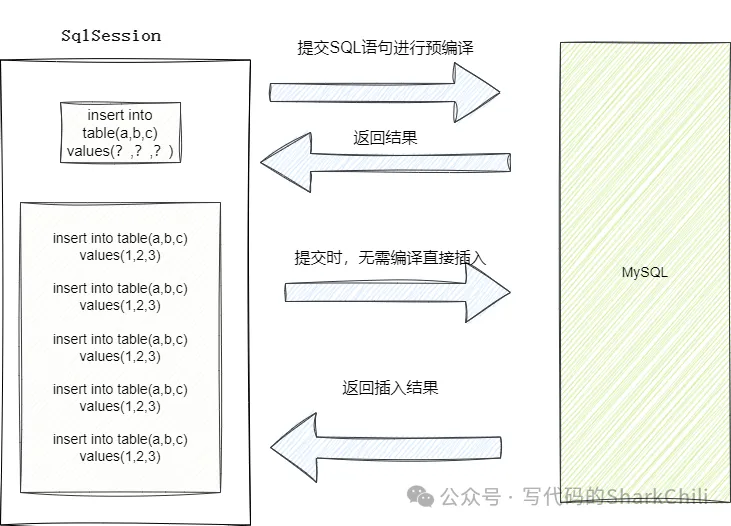
對應我們也給出批處理和foreach插入的執行日志印證這一點:

我們再來說說為什么批處理比foreach高效的原因,明明同樣是3000條語句的插入,foreach傳輸的數據包大小也小于批處理,為什么批處理的性能卻要好于foreach插入操作呢?
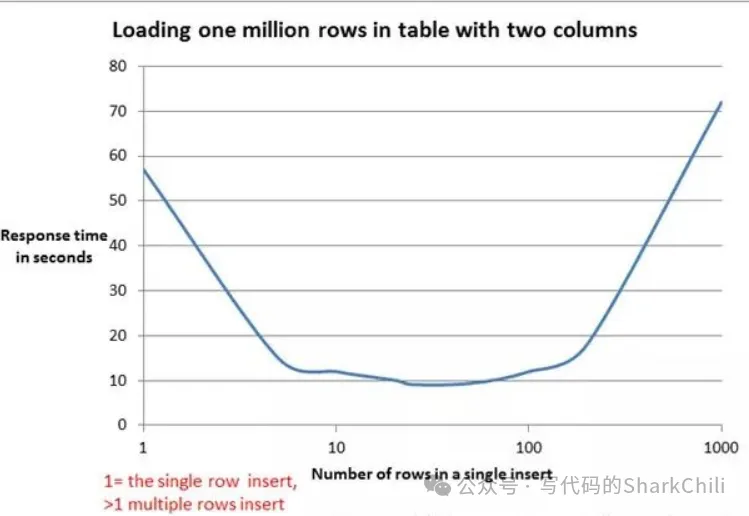
foreach插入進行預編譯之后,存在一個字符串解析拼接的操作,這就意味著如果本次插入的數據鍋大就會存在一個漫長的SQL拼接耗時,結合mybatis官網給出的壓測報告來看,在20~50行左右的插入性能表現最好,超過這個數字之后表現就會逐漸變差:
對此我們也給出mybatis的foreach語法底層的字符拼接的實現,即FilteredDynamicContext 下的appendSql方法:
private static class FilteredDynamicContext extends DynamicContext {
private DynamicContext delegate;
//對應集合項在集合的索引位置
private int index;
// item的索引
private String itemIndex;
// item的值
private String item;
//.............
// 解析 #{item}
@Override
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", new TokenHandler() {
@Override
public String handleToken(String content) {
// 把 #{itm} 轉換為 #{__frch_item_1} 之類的
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
// 把 #{itmIndex} 轉換為 #{__frch_itemIndex_1} 之類的
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
// 再返回 #{__frch_item_1} 或 #{__frch_itemIndex_1}
return new StringBuilder("#{").append(newContent).append("}").toString();
}
});
// 拼接SQL
delegate.appendSql(parser.parse(sql));
}
private static String itemizeItem(String item, int i) {
return new StringBuilder("__frch_").append(item).append("_").append(i).toString();
}
}五、一次插入多少數據量合適
明確要使用批處理進行批量插入之后,我們再來了解下一個問題,一次性批量插入多少條SQL語句比較合適?
對此我們基于100w的數據,分別按照每次10、500、1000、20000、80000條壓測,最終實驗結果如下:
80000的數據,每次插入10條,耗時:14555
80000的數據,每次插入500條,耗時:5001
80000的數據,每次插入1000條,耗時:3960
80000的數據,每次插入2000條,耗時:3788
80000的數據,每次插入3000條,耗時:3993
80000的數據,每次插入4000條,耗時:3847在經過筆者的壓測實驗時發現,在2000條差不多2M大小的情況下插入時的性能最出色。這一點筆者也在網上看到一篇文章提到MySQL的全局變量max_allowed_packet,它限制了每條SQL語句的大小,默認情況下為4M,而這位作者的實驗則是插入數據的大小在max_allowed_packet的一半情況下性能最佳。
show variables like 'max_allowed_packet%'; 當然并不一定只有上述條件影響批量插入的性能,影響批量插入的性能原因還有:
插入緩存:對于innodb存儲引擎來說,插入是需要耗費緩沖池內存的,如果在寫密集的情況下,插入緩存會占用過多的緩沖池內存,若插入操作占用大小超過緩沖池的一半,則會影響操其他的操作。
關于緩沖池的大小,可以通過下面這條SQL查看,默認情況下為134M:
show variables like 'innodb_buffer_pool_size';索引的維護:這點相信讀者比較熟悉,如果每次插入涉及大量無序且多個索引的維護,導致B+tree進行節點分裂合并等處理,則會消耗大量的計算資源,從而間接影響插入效率。
六、使用批處理的注意事項
批處理就是將一批操作提交至MySQL服務器一次性操作,但無法保證事務的原子性,所以讀者在使用批處理操作時,若需要保證操作原子性則需要考慮一下事務問題。
七、小結
整篇文章的篇幅不算很大,可以看到筆者針對此類問題常見的做法是:
- 明確問題和要解決的問題,以批量插入為例,首要問題就是現有方案中可以有幾種插入方式和如何提高這些插入技術的性能。
- 將問題切割成無數個子問題,筆者將批量插入按步驟分為:如何插入和插入多少的子問題。
- 搜索常見的解決方案,即筆者上述的的逐條插入、foreach、批處理3種插入方式。
- 基于現成方案采用不同量級的樣本進行求證,為避免偶然性,筆者將插入的量級設置為幾千甚至幾萬不等。
- 基于實驗樣本復盤總結,在明確批量插入技術之后,繼續查閱資料尋找插入量級,并繼續實驗從而得出最終研究成果。
- 進階,對于上述成果繼續加以求證了解工作原理,并對后續可能存在的問題查閱更多資料進行兜底。