













從零開始構建 DINO:自監督視覺 Transformer

DINO模型輸出的狗沖刺
無標簽自蒸餾(DINO)
《從幾個“補丁”中重建完整圖像 | 構建可擴展學習器的掩模自編碼器》這邊文章講了如何構建可擴展學習器,這是我對視覺變換器系列的繼續,其中我解釋了最重要的架構及其從零開始的實現。
自監督學習
自監督學習(SSL)是一種機器學習類型,模型通過無需手動標記的示例來學習理解數據。相反,它從數據本身生成其監督信號。當標記數據有限且獲取成本高昂時,這種方法非常有益。在SSL中,學習過程涉及創建任務,其中輸入數據可以用來預測數據本身的某些部分。常見的技術包括:
- 對比學習:模型通過區分相似和不相似的數據對來學習。
- 預測任務:模型從其他部分預測輸入數據的一部分,例如預測句子中的下一個詞或從其周圍環境中預測詞的上下文。
DINO模型
DINO(無標簽蒸餾)模型是一種應用于視覺變換器(ViTs)的尖端自監督學習方法。它代表了計算機視覺領域的一個重大進步,使模型能夠在不需要任何標記數據的情況下學習有效的圖像表示。由Facebook AI Research(FAIR)的研究人員開發,DINO利用學生-教師框架和創新的訓練技術,在各種視覺任務上取得了卓越的性能。
學生-教師網絡
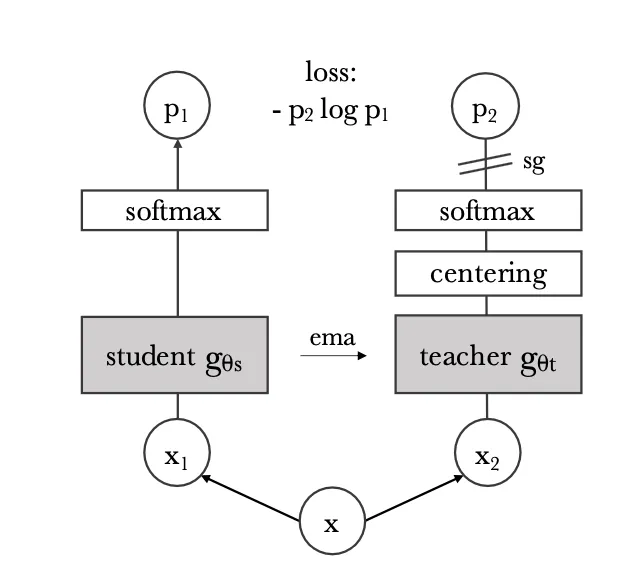
在DINO模型中,學生-教師網絡是實現無需標記數據的自監督學習的核心機制。這個框架涉及兩個網絡:學生網絡和教師網絡。兩個網絡都是視覺變換器,它們被設計用來通過將圖像處理為序列塊來處理圖像,類似于變換器處理文本序列的方式。
學生網絡的任務是從輸入圖像中學習生成有意義的表示。另一方面,教師網絡提供目標表示,學生網絡旨在匹配這些表示。教師網絡不是一個靜態實體;它通過逐漸整合學生網絡的參數隨時間演變。這是通過一種稱為指數移動平均的技術完成的,其中教師的參數被更新為其當前參數和學生參數的加權平均值。
目標是最小化學生表示和教師表示之間的差異,這些表示是針對相同增強圖像視圖的。這通常是通過使用一個損失函數來實現的,該函數鼓勵學生和教師輸出之間的對齊,同時確保不同圖像的表示保持不同。
通過根據學生網絡的學習進度不斷更新教師網絡,并訓練學生網絡以匹配教師的輸出,DINO有效地利用了兩個網絡的優勢。教師網絡為學生提供了穩定和一致的目標,而學生網絡推動了學習過程。這種協作設置允許模型在無需手動標簽的情況下從數據中學習強大和不變的特征,從而實現有效的自監督學習。
學生和教師的增強輸入
在DINO模型中,X1和X2(見上圖)指的是同一原始圖像X的不同增強視圖。這些視圖分別用作學生和教師網絡的輸入。目標是讓學生網絡學習在這些增強下產生一致的表示。學生和教師模型根據以下策略接收不同的增強:
- 全局裁剪:從原始圖像創建兩個全局裁剪。這些是覆蓋圖像大部分的較大裁剪,通常與原始圖像有很高的重疊。除了其他增強(如顏色抖動、高斯模糊、翻轉等)之外。
- 局部裁剪:除了全局裁剪外,教師網絡還接收幾個局部裁剪。這些是關注圖像不同部分的較小裁剪,捕捉更多局部細節。
我們將如何為參數圖像定義這些增強,這些圖像包含我們在訓練期間想要轉換的一批圖像。
# These augmentations are defined exactly as proposed in the paper
def global_augment(images):
global_transform = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.4, 1.0)), # Larger crops
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1), # Color jittering
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=23, sigma=(0.1, 2.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
return torch.stack([global_transform(img) for img in images])
def multiple_local_augments(images, num_crops=6):
size = 96 # Smaller crops for local
local_transform = transforms.Compose([
transforms.RandomResizedCrop(size, scale=(0.05, 0.4)), # Smaller, more concentrated crops
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1), # Same level of jittering
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=23, sigma=(0.1, 2.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# Apply the transformation multiple times to the same image
return torch.stack([local_transform(img) for img in images])蒸餾損失
在這里,我們希望使用某種距離度量來計算學生輸出和教師輸出之間的損失。我們這樣做:
- 獲取教師預測輸出的中心化Softmax,然后應用銳化。
- 獲取學生的Softmax預測,然后應用銳化。
def distillation_loss(student_output, teacher_output, center, tau_s, tau_t):
"""
Calculates distillation loss with centering and sharpening (function H in pseudocode).
"""
# Detach teacher output to stop gradients.
teacher_output = teacher_output.detach()
# Center and sharpen teacher's outputs
teacher_probs = F.softmax((teacher_output - center) / tau_t, dim=1)
# Sharpen student's outputs
student_probs = F.log_softmax(student_output / tau_s, dim=1)
# Calculate cross-entropy loss between students' and teacher's probabilities.
loss = - (teacher_probs * student_probs).sum(dim=1).mean()
return loss- 中心化:中心化教師的輸出確保學生模型更多地關注教師輸出分布中最顯著的特征或區別。通過中心化分布,鼓勵學生更多地關注對準確預測至關重要的顯著特征,而不是受數據中的變化或偏差的影響。這有助于更有效的知識傳遞,并可能導致學生模型的性能提高。
- 銳化:銳化涉及放大數據分布中的特定特征,旨在強調教師模型突出的區分。這個過程使學生模型能夠專注于學習教師預測中存在的復雜細節,這對于在數據集上準確復制其輸出至關重要。
訓練DINO模型

闡明DINO偽代碼的圖像,取自官方論文
有3個重要的步驟需要強調:
(1) 獲取學生和教師架構的不同輸入(x1,x2)的增強。
(2) 我們之前討論的蒸餾損失函數,注意它是如何計算不同增強輸入的架構的蒸餾損失的,即gs({x1, x2})和gt({x1, x2})。
(3) 更新(a)學生參數(b)教師參數和(c)中心。這里的關鍵是我們對更新教師參數執行指數移動平均更新。
- 教師參數:EMA應用于教師模型的參數。而不是在每次訓練迭代中直接更新教師參數,EMA隨時間維護這些參數的移動平均值。這個移動平均值作為教師模型的更平滑、更穩定的表示,可以幫助指導學生模型的訓練。
- 中心:此外,在DINO的一些實現中,EMA也用于更新中心。中心代表教師輸出分布的平均值,用于歸一化目的。通過應用EMA更新中心,它在整個訓練過程中逐漸演變,為歸一化提供更穩定的參考點。
DINO模型
class DINO(nn.Module):
def __init__(self, student_arch: Callable, teacher_arch: Callable, device: torch.device):
"""
Args:
student_arch (nn.Module): ViT Network for student_arch
teacher_arch (nn.Module): ViT Network for teacher_arch
device: torch.device ('cuda' or 'cpu')
"""
super(DINO, self).__init__()
self.student = student_arch().to(device)
self.teacher = teacher_arch().to(device)
self.teacher.load_state_dict(self.student.state_dict())
# Initialize center as buffer to avoid backpropagation
self.register_buffer('center', torch.zeros(1, student_arch().output_dim))
# Ensure the teacher parameters do not get updated during backprop
for param in self.teacher.parameters():
param.requires_grad = False
@staticmethod
def distillation_loss(student_output, teacher_output, center, tau_s, tau_t):
"""
Calculates distillation loss with centering and sharpening (function H in pseudocode).
"""
# Detach teacher output to stop gradients.
teacher_output = teacher_output.detach()
# Center and sharpen teacher's outputs
teacher_probs = F.softmax((teacher_output - center) / tau_t, dim=1)
# Sharpen student's outputs
student_probs = F.log_softmax(student_output / tau_s, dim=1)
# Calculate cross-entropy loss between student's and teacher's probabilities.
loss = - (teacher_probs * student_probs).sum(dim=1).mean()
return loss
def teacher_update(self, beta: float):
for teacher_params, student_params in zip(self.teacher.parameters(), self.student.parameters()):
teacher_params.data.mul_(beta).add_(student_params.data, alpha=(1 - beta))為了更新教師的參數,我們使用論文中提出公式,即gt.param = gt.param*beta + gs.param*(1 — beta),其中beta是移動平均衰減,gt、gs分別是相應的教師和學生架構。
進一步,我們在__init__下看到,教師的參數已設置為“required_grads = False”,因為我們不希望在反向傳播期間更新它們,而是應用移動平均更新。
此外,在PyTorch中將變量初始化為bugger是一種常見方法,用于將其保持在梯度圖之外,并不參與反向傳播。
Dino模型進一步需要如下調用
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dino = DINO(ViT(), ViT(), device)在這里,我們傳遞學生和教師架構,這不過是標準的視覺變換器,即ViT-B/16或ViT-L/16,正如第一篇論文中提出的。
最終訓練
現在可以將整個實現放入訓練循環中,正如論文中提出的。
def train_dino(dino: DINO,
data_loader: DataLoader,
optimizer: Optimizer,
device: torch.device,
num_epochs,
tps=0.9,
tpt= 0.04,
beta= 0.9,
m= 0.9,
):
"""
Args:
dino: DINO Module
data_loader (nn.Module): Dataloader for training
optimizer (nn.optimizer): Optimizer for optimization (SGD etc.)
defice (torch.device): 'cuda', 'cpu'
num_epochs: Number of Epochs
tps (float): tau for sharpening student logits
tpt: for sharpening teacher logits
beta (float): moving average decay
m (float): center moveing average decay
"""
for epoch in range(num_epochs):
print(f"Epoch: {epoch+1}/{len(num_epochs)}")
for x in data_loader:
x1, x2 = global_augment(x), multiple_local_augments(x)
student_output1, student_output2 = dino.student(x1.to(device)), dino.student(x2.to(device))
with torch.no_grad():
teacher_output1, teacher_output2 = dino.teacher(x1.to(device)), dino.teacher(x2.to(device))
# Compute distillation loss
loss = (dino.distillation_loss(teacher_output1, student_output2, dino.center, tps, tpt) +
dino.distillation_loss(teacher_output2, student_output1, dino.center, tps, tpt)) / 2
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Update the teacher network parameters
dino.teacher_update(beta)
# Update the center
with torch.no_grad():
dino.center = m * dino.center + (1 - m) * torch.cat([teacher_output1, teacher_output2], dim=0).mean(dim=0)(1) 我們用不同的全局和局部增強計算x1和x2。
(2) 之后,我們根據論文中提出的,為學生和教師模型獲取輸出,回想上面的算法循環圖。
(3) 在這里,我們將torch設置為no_grad()函數,以確保教師的參數不會通過反向傳播更新。
(4) 最后,我們再次根據論文中提出的方法計算蒸餾損失。
(5) 在蒸餾損失中,我們首先中心化教師模型的輸出,這樣學生模型就不容易崩潰,也不會只學習不重要的特征,或者比另一個特征更多地學習一個特征,而是專注于從教師模型中學習最獨特和潛在的特征。
(6) 然后我們銳化特征,以便在計算損失時,我們現在能夠比較兩個特征(學生和教師的)具有非常不同的數據分布,這意味著銳化后,更重要的特征會被銳化,而不太重要的特征則不會,這將創建一個更獨特的特征圖,使學生更容易學習。
(7) 然后我們執行反向傳播并執行optimizer.step(),更新學生模型并通過之前實現的指數移動平均更新教師網絡。
(8) 作為最后一步,我們將再次將torch設置為no_grad()并通過移動平均更新中心。我們根據教師的輸出更新中心,因此它與訓練過程中輸出數據分布的變化保持一致。
就這樣,這就是如何從零開始訓練DINO模型。到目前為止,在視覺變換器系列中,我們已經實現了標準的ViT、Swin、CvT、Mae和DINO(自監督)。希望你喜歡閱讀這篇文章。
# Create your own CustomDataset and dataloader
dataloader = DataLoader(CustomDataset, batch_size=32, shuffle=True)
optimizer = torch.optim.AdamW(dino.parameters(), lr=1e-4)
train_dino(dino,
DataLoader=dataloader,
Optimizer=optimizer,
device=device,
num_epochs=300,
tps=0.9,
tpt= 0.04,
beta= 0.9,
m= 0.9)


























