













面試官:說說看 Redis 底層數(shù)據(jù)類型有哪些?Redis為什么這么快?Redis 為什么引入多線程?Redis 多線程實現(xiàn)機(jī)制是怎樣?
面試題概覽:
- 說說看Redis底層數(shù)據(jù)類型有哪些?Redis的5種基本數(shù)據(jù)類型是用哪幾種底層數(shù)據(jù)類型組成的?
- 能否具體說說Redis的哈希表如何實現(xiàn),以及如何擴(kuò)容?
- Redis為什么這么快呢?Redis單機(jī)QPS能達(dá)到多少?
- Redis真的是一個單線程應(yīng)用嗎?如果是請說說看為什么使用單線程模型?
- 說說看Redis 6.0為什么引入了多線程?Redis的哪些地方用到了多線程?Redis多線程的實現(xiàn)機(jī)制是怎樣的?
- Redis 6.0是默認(rèn)開啟多線程的嗎,如果開啟多線程該設(shè)置Redis的線程數(shù)為多少?
面試官:說說看Redis底層數(shù)據(jù)類型有哪些?Redis的5種基本數(shù)據(jù)類型是用哪幾種底層數(shù)據(jù)類型組成的?
Redis的底層數(shù)據(jù)類型主要包括以下幾種,它們用于實現(xiàn)和支撐Redis提供的五種主要數(shù)據(jù)類型(String、Hash、List、Set、Zset):
一、簡單動態(tài)字符串(SDS,Simple Dynamic String)
用途:主要用于存儲String類型的值。
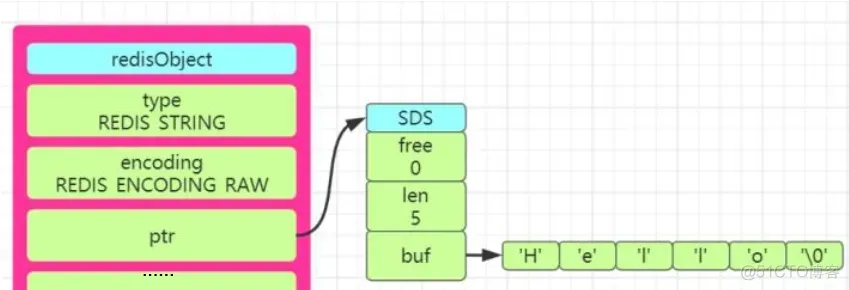
特點SDS是Redis自己構(gòu)建的一種字符串?dāng)?shù)據(jù)結(jié)構(gòu),相比C語言的傳統(tǒng)字符串(以空字符'\0'結(jié)尾),SDS具備自動擴(kuò)展、長度緩存、二進(jìn)制安全等優(yōu)點。SDS通過結(jié)構(gòu)體來記錄字符串的長度和已分配空間大小等信息,從而提高了字符串操作的性能。
二、壓縮列表(ZipList)
用途用于存儲Hash、List、Zset等類型的數(shù)據(jù),當(dāng)這些類型的數(shù)據(jù)量較少且元素較小時。
特點壓縮列表是一組連續(xù)的內(nèi)存塊,能夠節(jié)省空間。它內(nèi)部包含多個entry節(jié)點,每個節(jié)點包含前一個節(jié)點的長度、節(jié)點內(nèi)容等信息。當(dāng)數(shù)據(jù)量增多或元素變大時,壓縮列表可能會轉(zhuǎn)換為其他數(shù)據(jù)結(jié)構(gòu)(如哈希表、雙向鏈表等)。


三、哈希表(Hashtable)
用途主要用于存儲Hash、Set、Zset等類型的數(shù)據(jù),當(dāng)這些類型的數(shù)據(jù)量較多或元素較大時。
特點哈希表內(nèi)部維護(hù)了一個數(shù)組結(jié)構(gòu),通過計算key的哈希值來確定元素在數(shù)組中的位置。哈希表支持快速的查找、插入和刪除操作。
四、雙向鏈表(LinkedList)及快速列表(QuickList)
用途雙向鏈表用于存儲List類型的數(shù)據(jù),在Redis 3.2之前,List的底層實現(xiàn)是雙向鏈表或壓縮列表。Redis 3.2之后引入了快速列表(QuickList),它是雙向鏈表和壓縮列表的結(jié)合體,用于優(yōu)化List類型的性能。
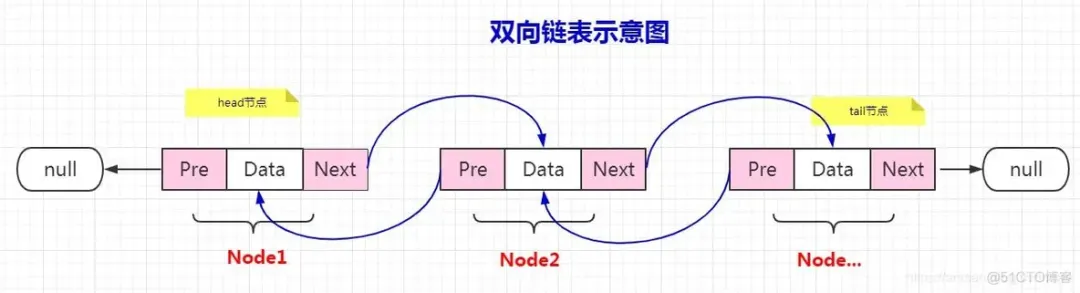

特點雙向鏈表中的每個節(jié)點持有對前一個和后一個節(jié)點的引用,支持在兩端進(jìn)行操作。快速列表則通過多個壓縮列表的組合來實現(xiàn),既保留了壓縮列表的空間優(yōu)勢,又具備了雙向鏈表的操作靈活性。
五、整數(shù)集合(IntSet)
用途用于存儲Set類型的數(shù)據(jù),當(dāng)Set中的所有元素都是整數(shù)且數(shù)量較少時。
特點整數(shù)集合內(nèi)部使用數(shù)組來存儲元素,并根據(jù)元素的類型(如16位整數(shù)、32位整數(shù)、64位整數(shù))來選擇不同的編碼方式。整數(shù)集合在添加新元素時,如果超出了當(dāng)前數(shù)組的容量或類型范圍,會進(jìn)行擴(kuò)容或升級。
六、跳表(SkipList)
用途主要用于存儲Zset類型的數(shù)據(jù),以實現(xiàn)有序性。
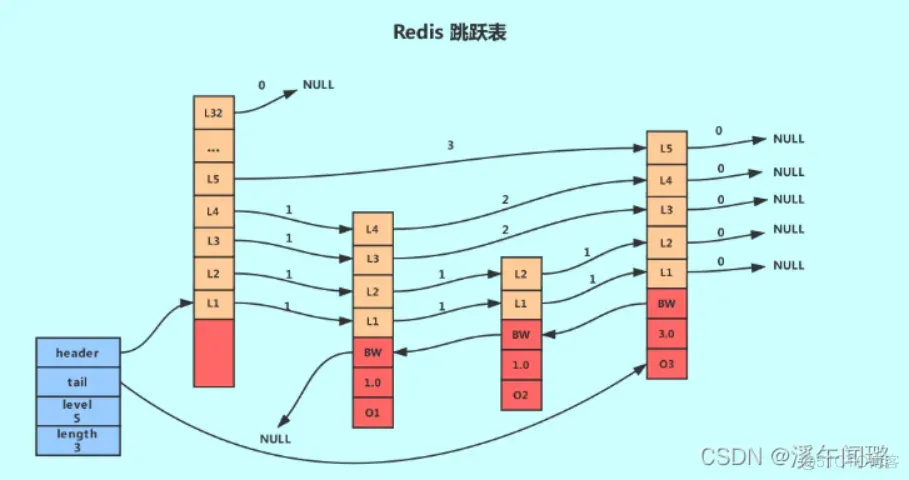
特點跳表是一種具有層次結(jié)構(gòu)的鏈表,每一層都是一個有序的鏈表。通過多層鏈表的組合,跳表能夠在O(log N)時間內(nèi)完成查找、插入和刪除操作。同時,跳表還使用哈希表來存儲成員和分?jǐn)?shù)的對應(yīng)關(guān)系,以提供快速的成員查找。
Redis的5種基本數(shù)據(jù)類型(String、List、Set、Hash、Zset)是由多種底層數(shù)據(jù)結(jié)構(gòu)組成的,以滿足不同場景下的數(shù)據(jù)存儲和操作需求。
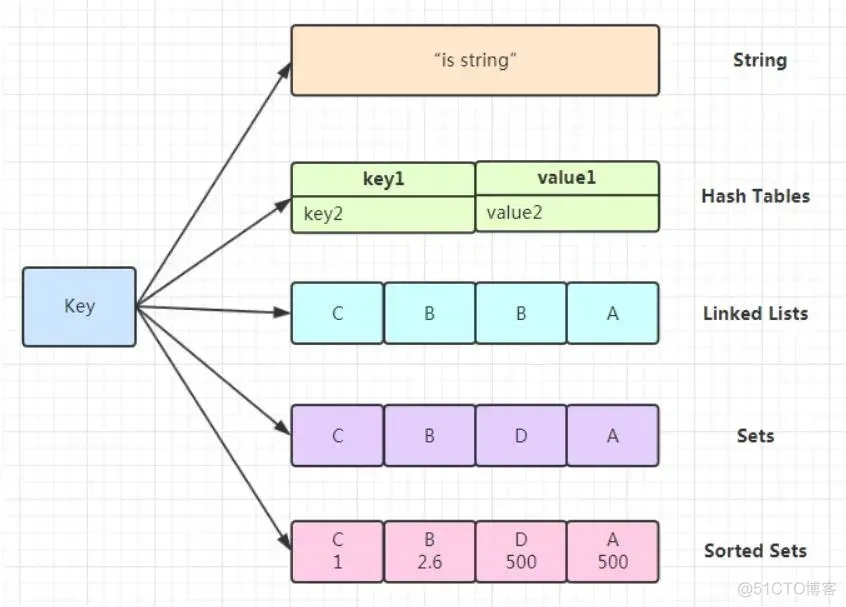
以下是這些基本數(shù)據(jù)類型與底層數(shù)據(jù)結(jié)構(gòu)之間的對應(yīng)關(guān)系:
(1) String(字符串)
底層數(shù)據(jù)結(jié)構(gòu):簡單動態(tài)字符串(SDS)
(2) List(列表)
底層數(shù)據(jù)結(jié)構(gòu):雙向鏈表、壓縮列表(ZipList)
說明:當(dāng)列表元素較少時,Redis使用壓縮列表來節(jié)省內(nèi)存。當(dāng)元素較多時,則使用雙向鏈表來支持快速的插入和刪除操作。
(3) Set(集合)
底層數(shù)據(jù)結(jié)構(gòu):哈希表(Hash Table)、整數(shù)集合(IntSet)
說明:當(dāng)集合中的元素都是整數(shù)且數(shù)量較少時,Redis使用整數(shù)集合來優(yōu)化內(nèi)存占用。當(dāng)元素數(shù)量較多或包含非整數(shù)元素時,則使用哈希表來實現(xiàn)快速的添加、刪除和查詢操作。
(4) Hash(散列)
底層數(shù)據(jù)結(jié)構(gòu):壓縮列表(ZipList)、哈希表(Hash Table)
說明:當(dāng)哈希對象保存的鍵值對較少且鍵和值的字符串長度都小于64字節(jié)時,采用壓縮列表作為底層實現(xiàn)以節(jié)省內(nèi)存。當(dāng)鍵值對較多或鍵和值的字符串長度較長時,則使用哈希表來實現(xiàn)快速的插入、查找和刪除操作。
(5) Zset(有序集合)
底層數(shù)據(jù)結(jié)構(gòu):跳躍表(SkipList)、哈希表(Hash Table)
說明:跳躍表是一種有序鏈表的數(shù)據(jù)結(jié)構(gòu),可以提供快速的插入、刪除和查找操作。通過使用跳躍表和哈希表的組合,有序集合在保持有序性的同時,還能快速地根據(jù)分?jǐn)?shù)進(jìn)行范圍查找和排名計算。哈希表用于存儲成員和分?jǐn)?shù)的對應(yīng)關(guān)系。
面試官:能否具體說說Redis的哈希表如何實現(xiàn),以及如何擴(kuò)容?
一、基本結(jié)構(gòu)
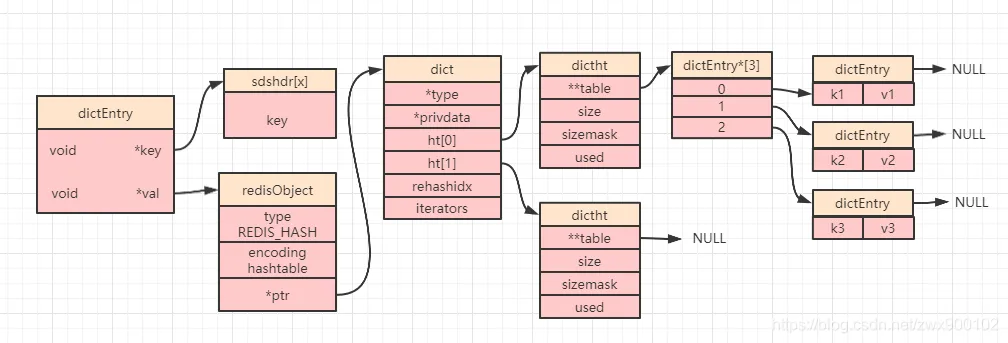
Redis中的哈希表由dict結(jié)構(gòu)體表示,該結(jié)構(gòu)體內(nèi)部嵌套了dictht(哈希表)對象。dictht結(jié)構(gòu)體包含以下關(guān)鍵字段:
- table:一個指針數(shù)組,每個元素都是一個dictEntry對象,用于存儲鍵值對。
- size:哈希表的大小,即table數(shù)組的長度。在Redis中,哈希表的大小總是2的n次方,這有助于優(yōu)化哈希沖突的處理。
- sizemask:掩碼值,用于計算索引值。它總是等于size-1,通過位運(yùn)算可以快速得到哈希值在數(shù)組中的索引位置。
- used:哈希表中已使用的節(jié)點數(shù),即存儲的鍵值對數(shù)量。
二、鍵值對存儲
每個dictEntry對象包含一個鍵值對以及指向下一個dictEntry的指針,形成鏈表結(jié)構(gòu)。當(dāng)發(fā)生哈希沖突時,新的鍵值對會被添加到?jīng)_突位置的鏈表末尾。這種設(shè)計使得Redis能夠高效地處理哈希沖突,而無需進(jìn)行復(fù)雜的重哈希操作。
當(dāng)創(chuàng)建一個哈希對象時,可以得到如下簡圖(部分屬性被省略):
三、哈希函數(shù)
Redis使用MurmurHash2算法作為哈希函數(shù)。該算法是一種非加密哈希函數(shù),以其高效和低碰撞率而聞名。通過MurmurHash2算法,Redis可以將任意長度的鍵映射為固定長度的哈希值,從而確定鍵在哈希表中的位置。
四、負(fù)載因子與rehash
負(fù)載因子是衡量哈希表使用程度的指標(biāo),計算公式為已使用節(jié)點數(shù) / 哈希表大小。當(dāng)負(fù)載因子超過預(yù)設(shè)的閾值(默認(rèn)為0.75)時,Redis會觸發(fā)rehash操作,以擴(kuò)展哈希表的大小并降低沖突概率。
Rehash操作涉及以下步驟:
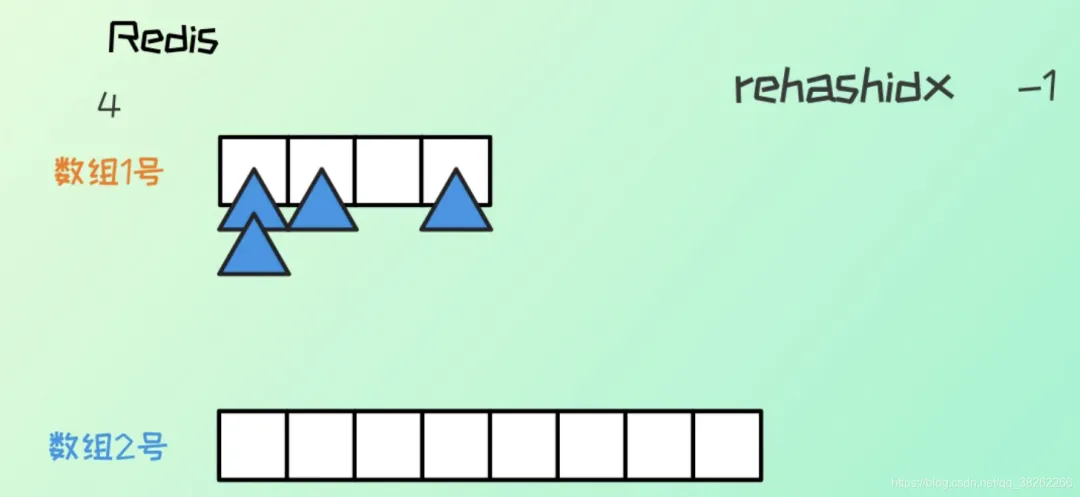
(1) 分配一個新的哈希表,其大小是當(dāng)前哈希表大小的2倍(或根據(jù)配置的其他倍數(shù))。
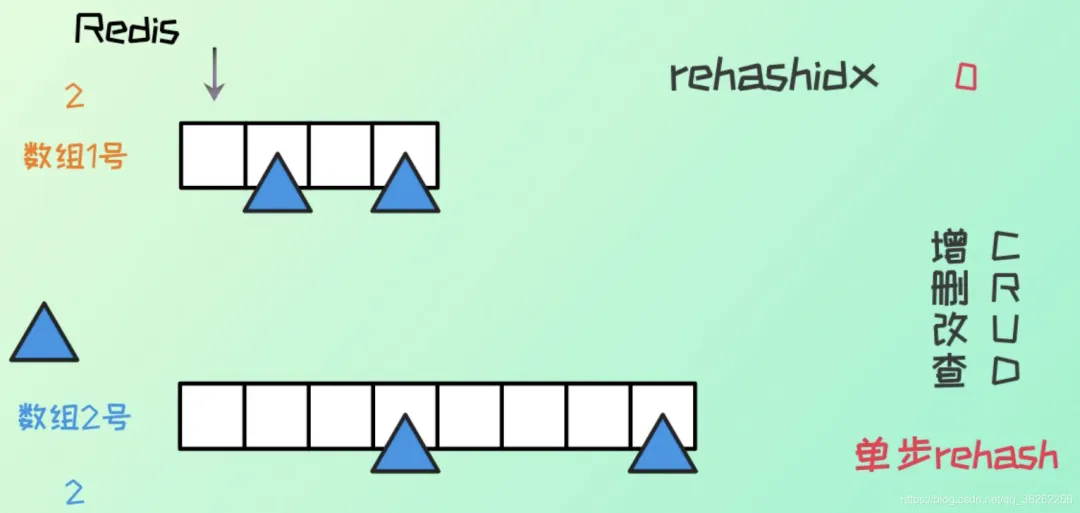
(2) 遍歷當(dāng)前哈希表中的所有鍵值對,并根據(jù)新的哈希表大小重新計算哈希值,然后將鍵值對插入到新的哈希表中。
(3) 替換舊的哈希表為新的哈希表,完成rehash操作。
值得注意的是,Redis采用漸進(jìn)式rehash策略來避免一次性處理大量數(shù)據(jù)導(dǎo)致的性能問題。在漸進(jìn)式rehash期間,每次對哈希表進(jìn)行增刪改查操作時,都會順帶將一部分?jǐn)?shù)據(jù)從舊表遷移到新表,直到遷移完成。
下面是rehash的具體過程:
- 當(dāng)Redis的哈希表的負(fù)載因子超過閾值時,系統(tǒng)會讓字典同時持有ht[0]和ht[1]兩個哈希表。
- Redis會設(shè)置一個變量rehashidx來記錄當(dāng)前rehash的進(jìn)度。rehashidx的初始值為0,表示從ht[0]的起始位置0開始遷移。
- 在rehash期間,每次對字典執(zhí)行增刪改查操作時會順帶將ht[0]哈希表在rehashindex位置上的所有鍵值對rehash到ht[1],當(dāng)rehash工作完成以后,rehashindex的值+1。
- 隨著字典操作的不斷執(zhí)行,最終會在某一時間段上ht[0]的所有鍵值對都會被rehash到ht[1],這時將rehashindex的值設(shè)置為-1,表示rehash操作結(jié)束。
漸進(jìn)式rehash采用的是一種分而治之的方式,將rehash的操作分?jǐn)傇诿恳粋€的訪問中,避免集中式rehash而帶來的龐大計算量。
需要注意的是在漸進(jìn)式rehash的過程,如果有增刪改查操作時,如果index大于rehashindex,訪問ht[0],否則訪問ht[1]。
漸進(jìn)式rehash的優(yōu)勢在于它能夠在不影響主線程服務(wù)請求的情況下逐漸完成哈希表的擴(kuò)容或縮容,極大地降低了對系統(tǒng)性能的影響。然而,它也會帶來一些額外的內(nèi)存空間開銷,因為在rehash過程中需要同時維護(hù)新舊兩個哈希表。
面試官:Redis為什么這么快呢?Redis單機(jī)QPS能達(dá)到多少?
Redis之所以速度非常快,主要歸因于以下幾個關(guān)鍵因素:
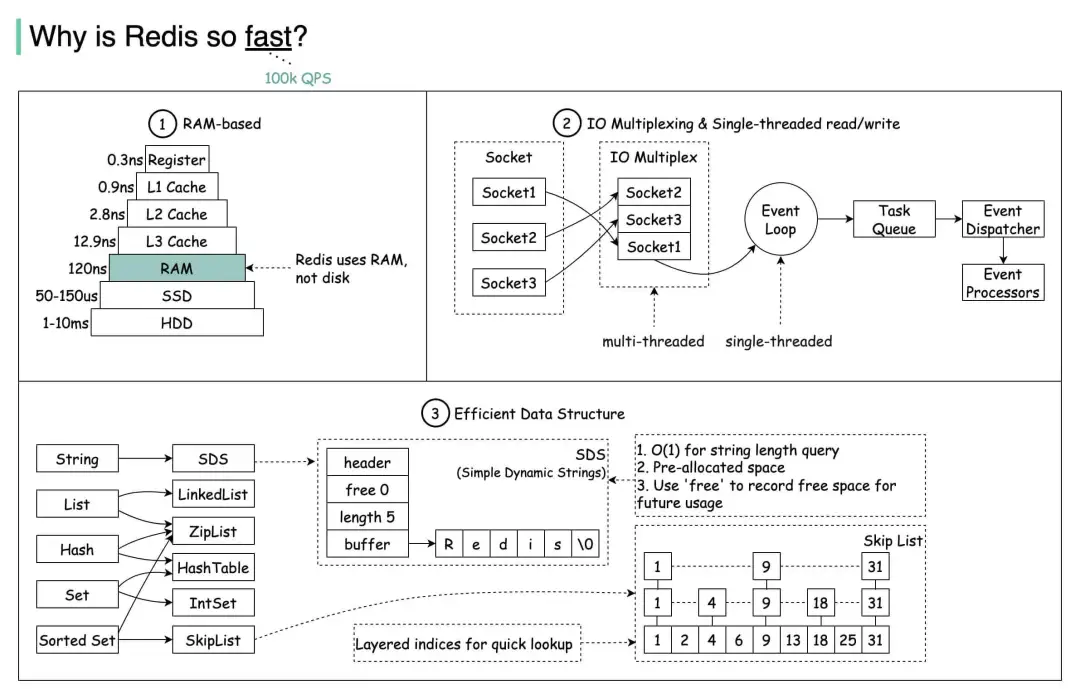
(1) 基于內(nèi)存的數(shù)據(jù)存儲:Redis將數(shù)據(jù)存儲在內(nèi)存中,這大大減少了磁盤I/O操作的開銷。相比傳統(tǒng)數(shù)據(jù)庫需要將數(shù)據(jù)從磁盤讀取和寫入磁盤,Redis可以非常快速地讀取和寫入數(shù)據(jù),從而實現(xiàn)了極高的操作速率。
(2) 高效的數(shù)據(jù)結(jié)構(gòu):Redis支持多種數(shù)據(jù)結(jié)構(gòu),如字符串、哈希、列表、集合和有序集合等。這些數(shù)據(jù)結(jié)構(gòu)都經(jīng)過了精心設(shè)計和優(yōu)化,使得數(shù)據(jù)存儲和訪問的時間復(fù)雜度降到最低。例如,Redis使用簡單動態(tài)字符串(SDS)來處理字符串,相比C語言中的傳統(tǒng)字符串處理方式,SDS在獲取字符串長度、修改字符串以及內(nèi)存分配等方面都更加高效。
(3) 合理的數(shù)據(jù)編碼:Redis能夠根據(jù)數(shù)據(jù)的類型和大小自動選擇最優(yōu)的編碼方式。例如,對于字符串類型的數(shù)據(jù),Redis會根據(jù)字符串的長度和內(nèi)容的數(shù)字性選擇int編碼或raw編碼。這種合理的編碼選擇使得Redis在處理不同類型和大小的數(shù)據(jù)時都能保持高性能。
(4) 單線程模型:Redis采用單線程模型來處理客戶端的請求。這種模型避免了多線程之間的上下文切換和鎖競爭等開銷,從而提高了處理請求的速度。同時,Redis通過I/O多路復(fù)用技術(shù)來同時處理多個客戶端的連接和請求,進(jìn)一步提高了并發(fā)性能。
(5) 異步非阻塞I/O:Redis使用異步非阻塞I/O模型來處理網(wǎng)絡(luò)請求。這意味著Redis可以在等待I/O操作完成時繼續(xù)執(zhí)行其他任務(wù),從而提高了整體的吞吐量和響應(yīng)速度。
Redis單機(jī)的QPS(每秒查詢率)性能取決于多個因素,包括Redis的版本、硬件配置、操作系統(tǒng)、網(wǎng)絡(luò)狀況以及業(yè)務(wù)操作的復(fù)雜性等。一般來說,Redis單機(jī)版可以支持上萬到幾萬的QPS。然而,要達(dá)到10萬以上的QPS,單機(jī)版Redis可能會面臨較大的壓力,這時通常需要考慮使用Redis集群或其他分布式架構(gòu)來分擔(dān)負(fù)載。
可以通過 redis-benchmark 命令進(jìn)行基準(zhǔn)測試:
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000- -h:指定 Redis 服務(wù)器的地址,默認(rèn)是 127.0.0.1。
- -p:指定 Redis 服務(wù)器的端口,默認(rèn)是 6379。
- -c:并發(fā)連接數(shù),即同時有多少個客戶端在進(jìn)行測試。
- -n:請求總數(shù),即測試過程中總共要執(zhí)行多少個請求。
面試官:你剛剛提到Redis使用單線程模型,Redis真的是一個單線程應(yīng)用嗎?如果是請說說看為什么使用單線程模型?
從核心操作的角度看,Redis在執(zhí)行命令時確實使用單個線程進(jìn)行操作,包括接收客戶端請求、解析請求、數(shù)據(jù)讀寫等操作,以及返回結(jié)果給客戶端,這些過程都是由一個主線程來完成的。這也是Redis被稱為單線程數(shù)據(jù)庫的原因。
然而,從整體功能和實現(xiàn)的角度看,Redis并不是嚴(yán)格意義上的單線程。在Redis 6.0之前的版本中,雖然大部分操作是由主線程完成的,但也有一些后臺線程或子進(jìn)程在處理任務(wù),如清理臟數(shù)據(jù)、生成快照、AOF重寫等。這些后臺任務(wù)的存在是為了避免阻塞主線程,提高Redis的整體性能。
在Redis 6.0及以后的版本中,Redis引入了多線程模型來處理網(wǎng)絡(luò)I/O的任務(wù)。這個多線程模型只用來處理網(wǎng)絡(luò)數(shù)據(jù)的讀寫和協(xié)議解析,而執(zhí)行讀寫命令的仍然是單線程。這種設(shè)計是為了充分利用服務(wù)器CPU的多核資源,提高Redis的網(wǎng)絡(luò)I/O性能。
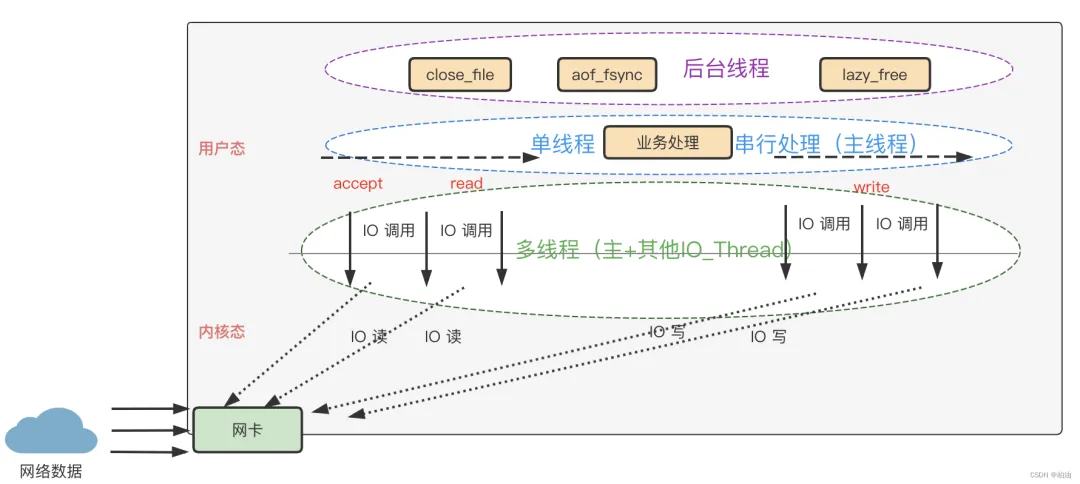
因此,可以說Redis在執(zhí)行命令時采用單線程模型,但從整體實現(xiàn)和功能角度來看,它并不是完全的單線程。
Redis通過結(jié)合單線程和多線程的優(yōu)勢,以及利用內(nèi)存和非阻塞I/O技術(shù),實現(xiàn)了高性能和高效率。
在執(zhí)行命令時采用單線程模型的原因如下:
1. 避免過多的上下文切換開銷
多線程調(diào)度過程中必然需要在 CPU 之間切換線程上下文 context,而上下文的切換又涉及程序計數(shù)器、堆棧指針和程序狀態(tài)字等一系列的寄存器置換、程序堆棧重置甚至是 CPU 高速緩存、TLB 快表的汰換,如果是進(jìn)程內(nèi)的多線程切換還好一些,因為單一進(jìn)程內(nèi)多線程共享進(jìn)程地址空間,因此線程上下文比之進(jìn)程上下文要小得多,如果是跨進(jìn)程調(diào)度,則需要切換掉整個進(jìn)程地址空間。
如果是單線程則可以規(guī)避進(jìn)程內(nèi)頻繁的線程切換開銷,因為程序始終運(yùn)行在進(jìn)程中單個線程內(nèi),沒有多線程切換的場景。
2.避免同步機(jī)制的開銷
如果 Redis 選擇多線程模型,又因為 Redis 是一個數(shù)據(jù)庫,那么勢必涉及到底層數(shù)據(jù)同步的問題,則必然會引入某些同步機(jī)制,比如鎖,而我們知道 Redis 不僅僅提供了簡單的 key-value 數(shù)據(jù)結(jié)構(gòu),還有 list、set 和 hash 等等其他豐富的數(shù)據(jù)結(jié)構(gòu),而不同的數(shù)據(jù)結(jié)構(gòu)對同步訪問的加鎖粒度又不盡相同,可能會導(dǎo)致在操作數(shù)據(jù)過程中帶來很多加鎖解鎖的開銷,增加程序復(fù)雜度的同時還會降低性能。
3. 簡單可維護(hù)
Redis 的作者對 Redis 的設(shè)計和代碼的初衷就是簡潔可維護(hù),而引入多線程必然會導(dǎo)致代碼的復(fù)雜度上升和可維護(hù)性下降。
首先多線程的引入會使得程序不再保持代碼邏輯上的串行性,代碼執(zhí)行的順序?qū)⒆兂刹豢深A(yù)測的,稍不注意就會導(dǎo)致程序出現(xiàn)各種并發(fā)編程的問題;其次,多線程模式也使得程序調(diào)試更加復(fù)雜和麻煩。
如果 Redis 使用多線程模式,那么所有的底層數(shù)據(jù)結(jié)構(gòu)都必須實現(xiàn)成線程安全的,這無疑又使得 Redis 的實現(xiàn)變得更加復(fù)雜。
總而言之,Redis 在執(zhí)行命令這種主場景下選擇單線程可以說是多方博弈之后的一種權(quán)衡:在保證足夠的性能表現(xiàn)之下,使用單線程保持代碼的簡單和可維護(hù)性。
面試官:能不能詳細(xì)說說看Redis 6.0為什么引入了多線程?Redis的哪些地方用到了多線程?Redis多線程的實現(xiàn)機(jī)制是怎樣的?
Redis 最初選擇單線程網(wǎng)絡(luò)模型的理由是:CPU 通常不會成為性能瓶頸,瓶頸往往是內(nèi)存和網(wǎng)絡(luò),因此單線程足夠了。現(xiàn)在 Redis 又要引入多線程是因為 Redis 的網(wǎng)絡(luò) I/O 瓶頸已經(jīng)越來越明顯了。
隨著互聯(lián)網(wǎng)的飛速發(fā)展,互聯(lián)網(wǎng)業(yè)務(wù)系統(tǒng)所要處理的線上流量越來越大,Redis 的單線程模式會導(dǎo)致系統(tǒng)消耗很多 CPU 時間在網(wǎng)絡(luò) I/O 上從而降低吞吐量,要提升 Redis 的性能有兩個方向:
- 優(yōu)化網(wǎng)絡(luò) I/O 模塊
- 提高機(jī)器內(nèi)存讀寫的速度
后者依賴于硬件的發(fā)展,暫時無解。所以只能從前者下手,網(wǎng)絡(luò) I/O 的優(yōu)化又可以分為兩個方向:
- 零拷貝技術(shù)或者 DPDK 技術(shù)
- 利用多核優(yōu)勢
零拷貝技術(shù)有其局限性,無法完全適配 Redis 這一類復(fù)雜的網(wǎng)絡(luò) I/O 場景。而 DPDK 技術(shù)通過旁路網(wǎng)卡 I/O 繞過內(nèi)核協(xié)議棧的方式又太過于復(fù)雜以及需要內(nèi)核甚至是硬件的支持。
因此,利用多核優(yōu)勢的多線程模型成為了優(yōu)化網(wǎng)絡(luò) I/O 性價比最高的方案。
在 Redis 6.0 中,多線程主要用來處理網(wǎng)絡(luò) IO 操作,命令解析和執(zhí)行仍然是單線程完成,這樣既可以發(fā)揮多核 CPU 的優(yōu)勢,又能避免鎖和上下文切換帶來的性能損耗。

接下來再說說看Redis的多線程實現(xiàn)機(jī)制:
(1) 主線程負(fù)責(zé)命令執(zhí)行:
Redis的主線程仍然負(fù)責(zé)處理客戶端命令的執(zhí)行,包括數(shù)據(jù)的讀寫操作。
(2) 多線程處理網(wǎng)絡(luò)I/O:
- 在多線程I/O模型中,客戶端請求的讀取以及響應(yīng)的寫入等網(wǎng)絡(luò)I/O操作被分發(fā)到多個工作線程中進(jìn)行處理。
- 這些工作線程只負(fù)責(zé)網(wǎng)絡(luò)I/O的讀寫和協(xié)議解析,不負(fù)責(zé)命令的具體執(zhí)行。
(3) 任務(wù)分發(fā)機(jī)制:
- Redis使用全局讀隊列(clients_pending_read)和全局寫隊列(clients_pending_write)來存儲待處理的網(wǎng)絡(luò)I/O任務(wù)。
- 主線程負(fù)責(zé)將任務(wù)從全局隊列分發(fā)到每個線程對應(yīng)的隊列中(io_threads_list)。
- 分發(fā)任務(wù)時,主線程采用輪詢(Round Robin)的方式,以確保任務(wù)能夠均勻分配到各個線程。
(4) 命令執(zhí)行流程:
- 當(dāng)客戶端發(fā)送請求時,主線程負(fù)責(zé)接收請求并放入全局讀隊列。
- 主線程將任務(wù)分發(fā)到各個線程對應(yīng)的隊列中,并設(shè)置相應(yīng)的標(biāo)記。
- 子線程輪詢檢查自己的隊列是否有任務(wù),如果有則處理網(wǎng)絡(luò)I/O讀寫和協(xié)議解析。
- 解析完成后,子線程將解析結(jié)果返回給主線程。
- 主線程根據(jù)解析結(jié)果執(zhí)行相應(yīng)的命令,并將結(jié)果放入全局寫隊列。
- 主線程再將寫任務(wù)分發(fā)到各個線程對應(yīng)的隊列中,子線程負(fù)責(zé)將結(jié)果寫回給客戶端。
在Redis 6.0及以后的版本中,多線程默認(rèn)是禁用的。要啟用多線程,需要在redis.conf配置文件中設(shè)置io-threads-do-reads yes,并指定線程數(shù)(io-threads)。如果不設(shè)置線程數(shù),多線程將不會生效。
關(guān)于線程數(shù)的設(shè)置,官方有一個建議:4核的機(jī)器建議設(shè)置為2或3個線程,8核的建議設(shè)置為6個線程,線程數(shù)一定要小于機(jī)器核數(shù)。還需要注意的是,線程數(shù)并不是越大越好,官方認(rèn)為超過了8個基本就沒什么意義了。
實際上如果開啟多線程,至少要4核的機(jī)器,且Redis實例已經(jīng)占用相當(dāng)大的CPU耗時的時候才建議采用,否則使用多線程沒有意義。所以估計80%的公司業(yè)務(wù)在不開啟多線程的情況下也能正常支撐。
綜上所述,Redis多線程的實現(xiàn)機(jī)制是通過將網(wǎng)絡(luò)I/O操作分發(fā)到多個工作線程中進(jìn)行處理,而命令的執(zhí)行仍然由單線程完成。這種設(shè)計既充分利用了多核CPU的性能,又避免了多線程切換和共享資源競爭帶來的開銷。

























