解析 Java 集合工具類:功能與實踐
在編程的廣袤領域中,集合是一個至關重要的概念,它猶如數據的魔法盒子,承載著各種元素的有序或無序組合。而集合工具類,則像是一把神奇的鑰匙,為我們開啟了高效處理和操作這些集合的大門。

一、詳解Java集合常用的方法
1. 集合判空
日常業務功能開發,為保證程序的健壯性,判空操作是必不可少的,筆者在日常審查代碼時候會看到很多開發會使用size方法進行判空,這種方案在常規集合容器下沒有任何問題,但是在某些特殊場景下,這個判空就可能存在性能問題:
if (list.size() == 0) {
//do something
}最典型的就是ConcurrentLinkedQueue,打開其內部源碼即可看到,該容器獲取元素數時是從頭節點開始遍歷獲取的:
public int size() {
int count = 0;
//從頭節點開始遍歷累加count
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}所以一般情況下,我們更建議使用isEmpty,該方法無論從語義還是實現上,都避免了掃描容器的開銷,是筆者比較推薦的一種判空方式:
public boolean isEmpty() {
return size == 0;
}2. 列表集合轉Map
集合轉Map時可以直接使用java8版本的流編程,對應代碼示例如下:
ArrayList<Person> list = new ArrayList<>();
list.add(new Person("jack", 18));
list.add(new Person("rose", 16));
//用流編程進行轉換
list.stream().collect(Collectors.toMap(Person::getName, Person::getAge));對應的我們也給出輸出結果:
16:17:35.383 [main] INFO com.sharkChili.Main - [Person(name=jack, age=18), Person(name=rose, age=16)]需要注意一點,我們使用的時候盡可能保證value非空,要知道toMap底層用到了HashMap的方法,該方法中如果判斷value為空會拋出空指針異常:
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
//如果value為空則拋出空指針異常
if (value == null)
throw new NullPointerException();
//......
}3. 集合遍歷時移除元素(重點)
不建議使用for循環等方式進行remove,會拋出ConcurrentModificationException ,這就是單線程狀態下產生的 fail-fast 機制。
fail-fast 機制,即快速失敗機制,是java集合(Collection)中的一種錯誤檢測機制。當在迭代集合的過程中該集合在結構上發生改變的時候,就有可能會發生fail-fast,即拋出ConcurrentModificationException異常。fail-fast機制并不保證在不同步的修改下一定會拋出異常,它只是盡最大努力去拋出,所以這種機制一般僅用于檢測bug。
所以我們建議jdk8情況下使用這種方式進行動態移除,即使用removeIf方法,該方法已經為我們做好了封裝無論從使用還是語義上,這種寫法更加友好:
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
//移除元素為5的
list.removeIf(integer -> integer == 5);這一點,我們從底層的源碼就可以知道,它為我們做好了:
- 獲取迭代器
- 遍歷元素
- 基于迭代器安全刪除元素
對應我們給出這段源碼實現,該代碼位于Collection下:
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
//獲取迭代器
final Iterator<E> each = iterator();
//檢查是否有下一個元素
while (each.hasNext()) {
//如果斷言(即我們外部傳入的判斷條件)返回true,將元素刪除
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}4. 集合去重
集合去重可以利用 Set 元素唯一的特性且通過O(1)級別的元素定位,可以快速對一個集合進行去重操作,避免使用 List 的 contains() 進行掃描元素的性能開銷:

如下代碼所示,list去重需要調用contains,要遍歷數組,而set底層用hash計算,如果散列良好情況下判重只需要O(1)
int size = 10_0000;
//List元素去重
List<Integer> resultList = new ArrayList<>(size);
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
if (!resultList.contains(i)) {
resultList.add(i);
}
}
long end = System.currentTimeMillis();
System.out.println("List去重:" + (end - start));
//set集合去重
start = System.currentTimeMillis();
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < size; i++) {
set.add(i);
}
end = System.currentTimeMillis();
System.out.println("HashSet去重:" + (end - start));對應我們也給出輸出結果來比對一下兩個集合之間的性能差異:
List去重:4353
HashSet去重:85. 集合轉數組
使用集合轉數組的方法,一般使用的是集合的 toArray(T[] array)這個方法,我們只需傳入數組首元素引用地址即可:
List<String> list = Arrays.asList("a", "b", "c", "d", "e", "f", "g", "h");
//集合轉數組
String[] array = list.toArray(new String[0]);這一點我們查看Arrays的toArray實現詳情就知道,該方法會獲取當前需要轉為數組的列表大小,然后從列表首元素地址開始將元素我們傳入的數組引用空間中:
public <T> T[] toArray(T[] a) {
//獲取列表元素大小
int size = size();
//......
//基于傳入元素地址將元素復制到傳入的數組地址空間中
System.arraycopy(this.a, 0, a, 0, size);
//......
return a;
}6. 數組轉集合
使用工具類 Arrays.asList() 把數組轉換成集合時,轉成的集合是Arrays工具類內部的ArrayList:
Integer[] nums = new Integer[10];
for (int i = 0; i < 10; i++) {
nums[i] = i;
}
List<Integer> myList = Arrays.asList(nums);需要注意的是AbstractList不能使用其修改集合相關的方法,它是一個只讀的容器, 它并沒有重寫 add/remove/clear 方法,所以會拋出 UnsupportedOperationException 異常,這一點我們查看AbstractList源碼即可知曉這一點:
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public E remove(int index) {
throw new UnsupportedOperationException();
}二、詳解Java集合工具類
1. 常見集合排序操作API
Java內置了很多使用的集合操作的api,這里我們不妨列一下方法清單,讀者可以基于注釋熟悉一下這些API的使用:
void reverse(List list)//反轉
void shuffle(List list)//隨機排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序邏輯
void swap(List list, int i , int j)//交換兩個索引位置的元素
void rotate(List list, int distance)//旋轉。當distance為正數時,將list后distance個元素整體移到前面。當distance為負數時,將 list的前distance個元素整體移到后面2. 集合排序
升序排序我們只需將列表傳入sort方法,其底層排序的工作機制稍微會做介紹,這里我們先熟悉一下使用方法:
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
System.out.println("Collections 升序排序:");
//排序并打印排序后的結果
Collections.sort(list);
System.out.println(list);對應的輸出結果如下:
[16, 84, 72, 18, 42, 93, 55, 28, 47, 14]
Collections 升序排序:
[14, 16, 18, 28, 42, 47, 55, 72, 84, 93]sort方法同樣是支持倒敘的排序的,對應的我們給出倒敘的比較器作為參數即可:
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
//倒敘排序并打印
System.out.println("Collections 倒敘排序:");
Collections.sort(list, Comparator.reverseOrder());
System.out.println(list);對應的我們也給出輸出結果:
[65, 84, 40, 27, 11, 24, 90, 54, 57, 6]
Collections 倒敘排序:
[90, 84, 65, 57, 54, 40, 27, 24, 11, 6]3. 列表翻轉
reverse方法就是將我們元素內部按照倒敘反轉一下,對應我們給出代碼示例:
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
//將列表元素翻轉一圈并打印
System.out.println("Collections 翻轉:");
Collections.reverse(list);
System.out.println(list);可以看到,翻轉后的數值按照列表倒敘進行排列了:
[17, 84, 53, 20, 70, 29, 15, 61, 63, 82]
Collections 翻轉:
[82, 63, 61, 15, 29, 70, 20, 53, 84, 17]4. 列表隨機排列
shuffle顧名思義即洗牌的意思,它會將列表內部元素順序打亂
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
//針對列表進行隨機排序
System.out.println("Collections 隨機排序:");
Collections.shuffle(list);
System.out.println(list);輸出結果:
[64, 24, 63, 94, 41, 76, 60, 69, 43, 27]
Collections 隨機排序:
[63, 64, 27, 41, 60, 24, 94, 69, 43, 76]5. 列表整體移動
rotate算是比較少用的api,讀者可以簡單了解一下,這個方法會將列表中所有元素斗向前移動,對于列表末尾的元素會移動到列表首部,具體算法筆者會在后面的源碼講解進行分析,這里我們了解一下其使用效果:
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
//將列表元素全部向前移動一步
System.out.println("Collections 所有元素向前移動一步:");
Collections.rotate(list, 1);
System.out.println(list);輸出結果:
[4, 80, 35, 52, 28, 79, 17, 61, 33, 11]
Collections 所有元素向前移動一步:
[11, 4, 80, 35, 52, 28, 79, 17, 61, 33]6. 兩數交換
swap可以指定兩數索引位置元素交換,如下代碼,我們將索引0和索引1位置的元素進行交換:
//隨機生成長度為10的列表
List<Integer> list = RandomUtil.randomEleList(IntStream.range(0, 100).boxed().collect(Collectors.toList()), 10);
//打印排序前的列表
System.out.println(list);
//打印兩數交換后的列表
System.out.println("Collections 交換兩個索引位置元素:");
Collections.swap(list, 0, 1);
System.out.println(list);對應輸出結果如下:
[24, 8, 91, 59, 34, 13, 78, 44, 84, 86]
Collections 交換兩個索引位置元素:
[8, 24, 91, 59, 34, 13, 78, 44, 84, 86]三、詳解Java集合工具類算法底層實現
1. Collections.sort底層實現
查看sort方法底層實現可以看出,除非開發顯式配置歸并排序才會調用legacyMergeSort進行歸并排序,否則一律使用TimSort進行列表排序:
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
//如果配置指定要求才使用歸并排序
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
//默認使用TimSort排序
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}而TimSort的sort方法就是排序核心的實現,TimSort是自適應的、混合的、穩定的排序算法。是基于歸并和二分插入排序優點結合的排序算法。復雜度最壞的情況下只有O(nlogn),最壞的情況下,空間復雜度為O(n/2)。
這個方法在基數閾值的選取和排序的實現細節都做了機制都做了相對極致的優化,當列表元素小于32的情況下,TimSort會直接通過二分插入排序直接完成排序操作。
二分插入排序法是插入排序法的升級版本,如下所示,我們都知道插入排序后左邊的元素都是有序的,如果使用常規二分排序,那么最壞情況下插入時間是O(n),所以我們基于左邊有序這個特點改用二分插入的方式完成排序優化了這個問題。
當右邊元素進行插入時,不斷在左邊進行二分運算定位到mid元素:
- 如果mid索引對應的元素小于插入元素,說明left索引元素值太小,需要向右移動找到下一個折中值。
- 如果mid索引元素值大于待插入的元素值,說明right坐標對應的元素值太大,需要讓right坐標向左移動找到小一點的中間值。
通過這樣的二分運算最終會找到一個小于或者等于待入元素坐標left作為插入索引并將元素插入,然后其余元素全部向后移動一位:

對此我們也給出TimSort排序的前半部分實現,可以看到這段代碼在進行二分排序前會先定位開頭有序的最小區間initRunLen ,如下圖所示,這個數組索引3之前的元素都是正向元素的,所以排序是從索引4開始:

對應的我們也給出這段代碼的整體實現:
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c,
T[] work, int workBase, int workLen) {
int nRemaining = hi - lo; //計算出待排序的范圍
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// 若小于32則直接調用`binarySort`
if (nRemaining < MIN_MERGE) {
//計算出lo 到 hi 范圍找出有序的長度,若是降序則轉為升序后返回
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
//使用二分插入法將hi以內未排序的元素插入到數組中
binarySort(a, lo, hi, lo + initRunLen, c);
//完成后直接返回
return;
}
//......
}countRunAndMakeAscending代碼的實現,該方法本質上就是從頭開始比對元素:
- 如果一開始runHi 元素大于其后一個元素,則正序方式先前遍歷,runHi 不斷前行,找到正向有序的最小區間。
- 如果一開始runHi 元素小于后一個元素,則按照倒敘方式進行編譯,runHi 不斷前行,找到逆序的最小區間。
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi,
Comparator<? super T> c) {
assert lo < hi;
// 待比較的值從lo+1 開始
int runHi = lo + 1;
if (runHi == hi)
return 1;
// 第一次比較若小于0就進入循環,找到最小范圍的降序子數組,循環結束后翻轉為升序
if (c.compare(a[runHi++], a[lo]) < 0) { // Descending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
//循環結束后翻轉為升序
reverseRange(a, lo, runHi);
} else {
//反之就尋找升序子數組
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
//runHi - lo即我們本次找到的有序子數組的長度
return runHi - lo;
}然后我們再介紹binarySort,如上文所說不斷通過二分運算比對mid和插入元素的值,然后進行插入,這里筆者特殊說明一下binarySort對于二分插入排序的優化細節,從代碼中可以看到,當二分插入排序定位到合適的位置之后,會判斷這個位置和插入元素之間的距離,如果兩者距離小于2,則直接通過簡單的元素交換:

反之,如果待插入的位置和插入元素索引位置大于2,則找到left及其前方元素批量先前移動一格,然后騰出一塊空間將元素插入:

對應的我們給出binarySort的代碼實現細節:
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
//......
for ( ; start < hi; start++) {
T pivot = a[start];
// 二分搜索范圍設置為[lo,start)
int left = lo;
int right = start;
assert left <= right;
//通過二分法,找到合適插入位置
while (left < right) {
//通過位運算高效實現/2得到一個中間索引mid
int mid = (left + right) >>> 1;
//如果中間值大于插入元素,則right設置為mid,視圖找到小一點的mid
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
//如果中間值小于插入元素,則left等于mid找到一個大一點的mid
left = mid + 1;
}
assert left == right;
int n = start - left; // 計算需要移動的步數
// 這里正是設計者的精華所在,可以看到如果只要移動1-2步,直接交換即可,若大于兩步則直接指定數組范圍進行批量拷貝
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}當元素大于32的時候,TimSort排序算法就會進行更近一步的設計,即針對當前數組生成無數個子單元進行二分插入排序,然后基于每個有序的子單元進行歸并從而得到不斷歸并得到一個有序集合:

對應的我們給出TimSort后續代碼,整體邏輯與筆者說明一致,建議讀者結合筆者說明和注釋理解:
TimSort<T> ts = new TimSort<>(a, c, work, workBase, workLen);
int minRun = minRunLength(nRemaining);
do {
// 計算出最大的有序范圍的索引
int runLen = countRunAndMakeAscending(a, lo, hi, c);
//若小于minRun,則說明進行排序的數組太小,需要指定一個范圍排序一下
if (runLen < minRun) {
//nRemaining 為當前待排序的范圍大小,minRun 為計算出來至少要排序的范圍。若nRemaining 小于minRun ,則取nRemaining ,意味需要排序的范圍就剩幾個了直接用這幾個值排個序就好了。反之則取minRun 進行二分插入排序
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
//完成后force的值就代表當前經歷排序的元素個數,存到runLen中,作為后續合并的依據
runLen = force;
}
// 將lo到runLen的值存到棧中,后續歸并會用到
ts.pushRun(lo, runLen);
//將當前排序的范圍數組歸并到已排序的數組中
ts.mergeCollapse();
// 起始位置加到runLen之后
lo += runLen;
//待排序的值減去已排序的長度
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;由于這篇文章主要描述Java集合工具類的使用,所以就不展開細講了。
2. rotate列表旋轉算法的實現
rotate旋轉算法底層也有很多的巧妙設計,步入其源碼可以看到:
- 如果是RandomAccess即具備隨機訪問特性的數組或者數組大小小于100時使用rotate1方法進行旋轉
- 反之說明該列表是不具備隨機范文的鏈表則調用rotate2進行元素旋轉
對應的我們給出代碼的頂層實現:
public static void rotate(List<?> list, int distance) {
//如果是具備隨機訪問特性或者元素小于100則調用rotate1
if (list instanceof RandomAccess || list.size() < ROTATE_THRESHOLD)
rotate1(list, distance);
else //反之調用rotate2
rotate2(list, distance);
}我們先來說說rotate1方法的實現,邏輯比較簡單,計算出移動的步數之后通過list的set方法將元素設置到移動的位置上,通過set方法得到該位置上原有的元素,再將該元素移動到旋轉后的的索引上:

對應的我們給出這段實現的源碼,讀者可結合說明了解核心流程:
private static <T> void rotate1(List<T> list, int distance) {
int size = list.size();
if (size == 0)
return;
//計算移動的步數
distance = distance % size;
//若為負數則加上數組大小 即可 (向左走n步)==(向右走數組大小+n步)
if (distance < 0)
distance += size;
if (distance == 0)
return;
//移動
for (int cycleStart = 0, nMoved = 0; nMoved != size; cycleStart++) {
T displaced = list.get(cycleStart);
int i = cycleStart;
do {
i += distance;
//若大于數組大小則減去數組大小得出最終要走的步
if (i >= size)
i -= size;
//賦值并返回舊元素進行下一次do while旋轉
displaced = list.set(i, displaced);
nMoved ++;
} while (i != cycleStart);
}
}走到rotate2這個函數則說明這個數組為不具備隨機訪問性的鏈表,為了保證性能,該方法會通過計算的方式得到計算出一個批量移動的區間,然后基于這兩個整體進行批量的移動。
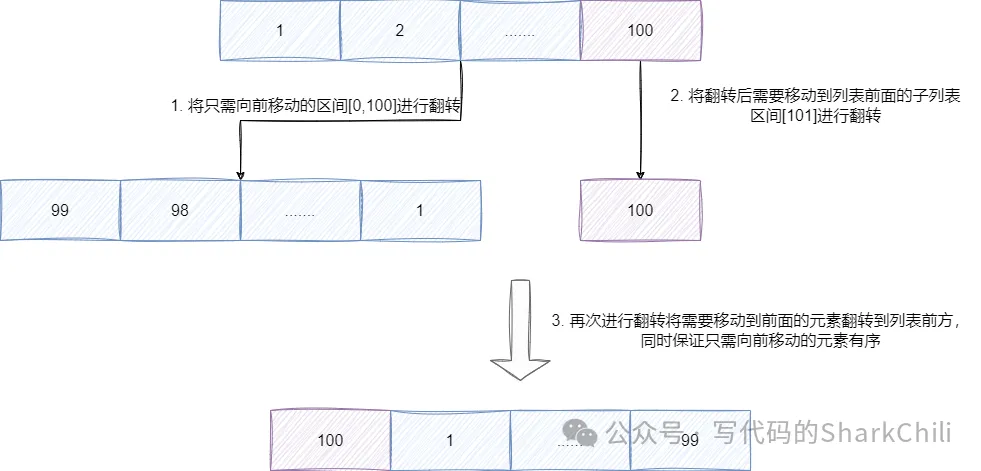
例如我們現在有一個鏈表,內部包含0-100一共101個元素,元素值為0~100,剛剛好可以執行rotate2方法,假設我們希望全體向前移動一步,rotate2算法會通過-distance % size得到100,即[0,100]區間是只需先前移動的區間,而[101]是需要移動到列表前面的區間,rotate2的執行步驟為:
- 將區間1翻轉,得到99~0。
- 將區間2翻轉,得到100,此時列表排列為99~0、100。
- 最后將整個列表進行一次翻轉,將100移動到列表最前面的同時,也將只需先前移動一格的區間放到100的后面:
對應的我們也給出rotate2的代碼實現,整體思路和筆者說明的一致,就是通過-distance % size計算得到只需先前移動和要翻轉到列表前面的兩個區間,然后執行:
- 只需向前移動的區間1翻轉。
- 移動到列表首部的區間2翻轉。
- 整個列表翻轉將區間2提前。
private static void rotate2(List<?> list, int distance) {
int size = list.size();
if (size == 0)
return;
//[0,mid]只需向前移動distance步,(mid,list.size()-1]移動到列表前面
int mid = -distance % size;
if (mid < 0)
mid += size;
if (mid == 0)
return;
//翻轉[0,mid]
reverse(list.subList(0, mid));
//翻轉(mid,list.size()-1]
reverse(list.subList(mid, size));
//整體移動,將(mid,list.size()-1]翻轉到列表前方,同時保證[0,mid]有序
reverse(list);
}四、詳解jdk常見搜索比對函數
1. 核心api概覽
jdk也為我提供了很多使用的搜索和比較統計函數,對應的函數列表如下:
int binarySearch(List list, Object key)//對List進行二分查找,返回索引,注意List必須是有序的
int max(Collection coll)//根據元素的自然順序,返回最大的元素。 類比int min(Collection coll)
int max(Collection coll, Comparator c)//根據定制排序,返回最大元素,排序規則由Comparatator類控制。類比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
int frequency(Collection c, Object o)//統計元素出現次數
int indexOfSubList(List list, List target)//統計target在list中第一次出現的索引,找不到則返回-1,類比int lastIndexOfSubList(List source, list target)
boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替換舊元素2. 使用示例
System.out.println("Collections 二分搜索法(注意數組并需有序):");
Collections.sort(list);
int idx = Collections.binarySearch(list, 1);
System.out.println(idx);
System.out.println("Collections 求最大值:");
System.out.println(Collections.max(list));
System.out.println("Collections 按自定義方式找最大值:");
System.out.println(Collections.max(list, Comparator.reverseOrder()));
System.out.println("Collections 用指定元素替代list中所有的元素:");
Collections.fill(list, 5);
System.out.println(list);
System.out.println("Collections 統計頻次:");
System.out.println(Collections.frequency(list, 5));
System.out.println("Collections 返回target子集在list中第一次出現的位置:");
List<Integer> list1 = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> target = Arrays.asList(3, 4);
System.out.println(Collections.indexOfSubList(list1, target));//返回target子集在list中第一次出現的位置
System.out.println("Collections replaceAll:");
Collections.replaceAll(list, 5, 6);
System.out.println(list);3. 詳解洗牌算法
這里我們著重說明一下隨機洗牌算法的實現,邏輯比較簡單:
- 如果列表具備隨機訪問或者size小于100,可以直接從size開始倒敘調用swap進行隨機元素交換。
- 反之說明當前列表是大于100的鏈表,首先將這些元素存到一個具備隨機訪問的數組中,然后基于這個數組進行隨機swap交換,再存入鏈表中,所以性能表現會差一些。
對應的源碼如下:
public static void shuffle(List<?> list, Random rnd) {
int size = list.size();
//若小于SHUFFLE_THRESHOLD 或者是RandomAccess類則從高位索引與隨機一個低位索引交換值完成洗牌
if (size < SHUFFLE_THRESHOLD || list instanceof RandomAccess) {
for (int i=size; i>1; i--)
//將i-1位置元素和隨機一個位置進行交換
swap(list, i-1, rnd.nextInt(i));
} else {
//反之轉成數組,再遍歷數組的值存到list中
Object arr[] = list.toArray();
for (int i=size; i>1; i--)
////將i-1位置元素和隨機一個位置進行交換
swap(arr, i-1, rnd.nextInt(i));
//然后設置到鏈表中
ListIterator it = list.listIterator();
for (int i=0; i<arr.length; i++) {
it.next();
it.set(arr[i]);
}
}
}五、同步控制
1. 同步控制常見函數
注意,非必要不要使用這種API,效率極低
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(線程安全的)collection。
synchronizedList(List<T> list)//返回指定列表支持的同步(線程安全的)List。
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(線程安全的)Map。
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(線程安全的)set。2. 使用示例
可以看到筆者在下面貼出使用Collections.synchronizedList包裝后的list的add方法,鎖的粒度很大,在多線程操作情況下,性能非常差。
我們就以synchronizedList為例查看其add方法,可以看到其實現線程安全的方式很簡單,直接在工作代碼上synchronized ,在高并發情況下,很可能造成大量線程阻塞
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}示例代碼如下,我們分別開兩個線程,往數組中添加1000個數組,可以看到筆者注釋代碼中用了普通list,以及通過Collections.synchronizedList后的list,感興趣的讀者可以基于下面代碼測試是否線程安全
@Test
public void ThreadSafe() {
CountDownLatch latch = new CountDownLatch(1);
// List<Integer> list = new ArrayList<>();
List<Integer> list = Collections.synchronizedList(new ArrayList<>());
ExecutorService threadPool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 2; i++) {
threadPool.submit(() -> {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int j = 0; j < 1000; j++) {
list.add(j);
}
});
}
latch.countDown();
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
System.out.println(list.size());
}輸出結果為2000,說明該方法確實實現了線程安全
2000