求求你們了,別在某音上學習DeepSeek部署了好嗎?
哈嘍大家好啊,我是Hydra。
最近刷某音的時候,總是動不動就給我推一個類型的直播間,標題都差不多,類似于“1分鐘教你本地部署DeepSeek滿血版”什么的,頭像清一色的藍色小鯨魚,就很耽誤我看小姐姐跳舞。
前幾次的時候,我還耐著性子看了幾分鐘,后來基本上看見了就拉黑劃走,首先是因為他們講的內容高度雷同,都是部署Ollama、ChatBox、CherryStudio這些東西,內容相似到我甚至懷疑他們是同一個割韭菜培訓班培訓出來的。其次就是講的東西真沒什么用, 稍微了解一些大模型的都明白,按他們這樣部署完了,你頂多也就當個玩具玩玩。
為什么呢,聽我給你分析分析,聽完之后,答應我別看這些直播浪費時間了好嗎?
首先,大家都知道,運行大模型是需要算力的,這個算力通常由GPU提供。注意我說的是"通常",因為還有NPU、TPU等設備也能提供算力,但是平常使用的電腦一般并沒有配備,所以暫不討論。在本地部署大模型之前,你首先需要評估一下你的電腦配置,明確兩件事情:
我的電腦能不能跑起來大模型、能跑起來多大參數量的模型?
如果你的電腦沒有GPU或者使用的是集顯,這種情況下,建議你部署個1.5B的模型嘗一下鮮就可以了,即使純CPU跑個推理也沒什么問題,速度也勉強說的過去。
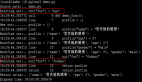
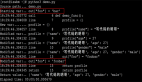
但是如果你想部署7B以上的模型,沒有GPU的話還是算了,只用CPU推理的話token輸出速度非常感人。我在16核64G內存的CPU的服務器上做了個測試,可以感受一下這個速度:
 圖片
圖片
那么模型的參數規模和性能有什么具體的關聯呢?一般來說,參數規模越大,大模型推理時就擁有更高的準確性和泛化能力,處理問題的表現也更加出色。但是同時,運行所需要的顯存資源更高,推理時間可能更長。
在計算大模型推理需要的顯存時,需要考慮的不光是模型基礎占用顯存,還需要考慮KV cache、激活值占用顯存,以及一些其他的開銷等。
我看了看那些直播間里列出的顯存估算表格,但是基本上都是只考慮了最低模型基礎占用顯存,這一塊可以使用公式計算:
其中,P是模型的參數量(單位是億),Q是加載模型使用的位數。那么以DeepSeek-R1-Distill-Qwen-7B為例,它的參數規模是7B,模型精度為BF16,那么加載它使用的基礎顯存就需要:
也就是,要運行起來模型,最少需要13.04GB的顯存。
除了模型基礎顯存外,上下文長度也是個顯存刺客,離開上下文長度談顯存使用就是耍流氓,這里使用工具對比一下不同上下文長度進行推理時占用的顯存:
 圖片
圖片
所以說,如果在顯存有限的情況下,還需要額外對上下文長度進行一定控制。群里大佬發了一張圖,給出了DeepSeek-R1在穩定運行情況下,各個模型的顯存需求。
 圖片
圖片
至于這個表上為什么R1的規模是685B,是因為額外加了14B的MTP模塊的參數,使R1能夠在推理階段一次生成多個token。并且,這張表中R1還是進行了FP8量化或INT4量化的情況,如果直接運行BF16精度需要的顯存更高,估計至少也需要雙節點的8卡H100才能部署成功。
所以說,我的建議是如果你的電腦GPU配置不足,與其花費時間搗鼓部署,真不如去SiliconFlow上直接調用API,1.5B、7B、8B的R1蒸餾模型的API都是免費調用,難道不香嗎?
其次,我覺得Ollama這個東西是有些雞肋的,它的優點是安裝確實很簡單,運行模型也容易。但是說直接點,Ollama就是個玩具,根本不可能拿到生產環境使用,原因很簡單,它有一個最致命的問題,并發處理能力有限。
相比之下,vLLM在這方面就做的好的多。簡單來說,vLLM是一個高性能的大模型推理引擎,它通過 Paged Attention 技術高效管理KV cache,實現了比 transformers 高14-24倍的吞吐量,所以我們在選推理框架的時候,首先會看它支不支持vllm。
所以個人推薦的是,使用Xinference這一推理框架來代替Ollama,它支持的推理引擎非常多,包括了transformers 、vLLM、Llama.cpp、SGLang、MLX,并且支持多卡部署、多副本部署,在實用性上真的比Ollama要強上很多,而且部署也非常簡單。
最后,其實本地部署的小規模的模型能力還是比較有限的,例如7B模型有時候會出現輸出的token中英文混雜的情況,并且對 Function Call 的支持也不是很好。在配置有限的情況下,本地部署的小規模模型和官方滿血版提供的能力差距還是挺大的,不過歸根結底,咱們部署的小規模模型在本質上其實不是DeepSeek-R1,看一下官方倉庫,可以看到這幾個單詞:DeepSeek-R1-Distill Models。
復習一下 distill 這個單詞,六級詞匯,蒸餾的意思。
所以說,這個列表里從1.5B到70B的模型都是蒸餾模型,是用最簡易的方法使R1的結果能在小模型上復現,將R1的推理能力遷移至小規模模型。
 圖片
圖片
拿DeepSeek-R1-Distill-Qwen-7B 這個模型舉例,它就是基于Qwen2.5-Math-7B這個模型蒸餾出來的,通過這一過程,驗證了較大模型的推理能力的可遷移性。但是歸根結底,測試過程中還是存在各種各樣的問題,后續還需要做各種的適配工作。
在這個算法狂歡的時代,技術祛魅或許比盲目追新更重要,當我們刷著滿屏的"本地部署"教程時,不妨先看清它們背后的真相,雖然看似充滿了誘惑,但實際上卻缺乏深度和實用性,這些內容往往只是在重復一些基礎的操作,卻忽略了運行大模型背后真正需要考慮的因素。
所以,下次看到類似的直播間時,不妨停下來思考一下,這些內容是否真的對你有價值,當你劃走時,失去的不是通向人工智能的捷徑,而是一張名為"技術智商稅"的入場券。