200多行代碼,超低成本復現DeepSeek R1「Aha Moment」!復旦大學開源
本文是復旦大學知識工場實驗室肖仰華教授、梁家卿青年副研究員科研團隊的最新研究成果,他們用簡潔的代碼高效復現了 R1-zero 的自發反思能力。
在關于 DeepSeek 的文章中,我們會多次聽到「Aha Moment」這個詞。它指的是模型在訓練過程中經歷的一種頓悟時刻,表現為模型突然展現出類似人類的自我反思和策略調整能力。
 DeepSeek 論文中提到的 Aha Moment。
DeepSeek 論文中提到的 Aha Moment。
DeepSeek-R1-zero 經過強化學習實現了大模型頓悟時刻的自發涌現,引發了大量對其方案的解讀與復現工作。
其中,基于 GRPO( Group Relative Policy Optimization)強化學習方案尤其受到關注。業界先后開源了多個基于 GRPO 算法的 R1-zero 復現項目。然而,這些復現項目嚴重依賴一些復雜代碼框架,有著較高的代碼實現復雜度,對部署環境存在較高依賴,資源利用率不高,代碼可讀性與可維護性仍存在改進空間。
對此,復旦大學知識工場實驗室肖仰華教授、梁家卿青年副研究員科研團隊基于 GRPO 算法思想高效復現了 R1-zero 自發反思能力。目前,該項目(Simple-GRPO)的第一版代碼實現已經開源并提交 Github。
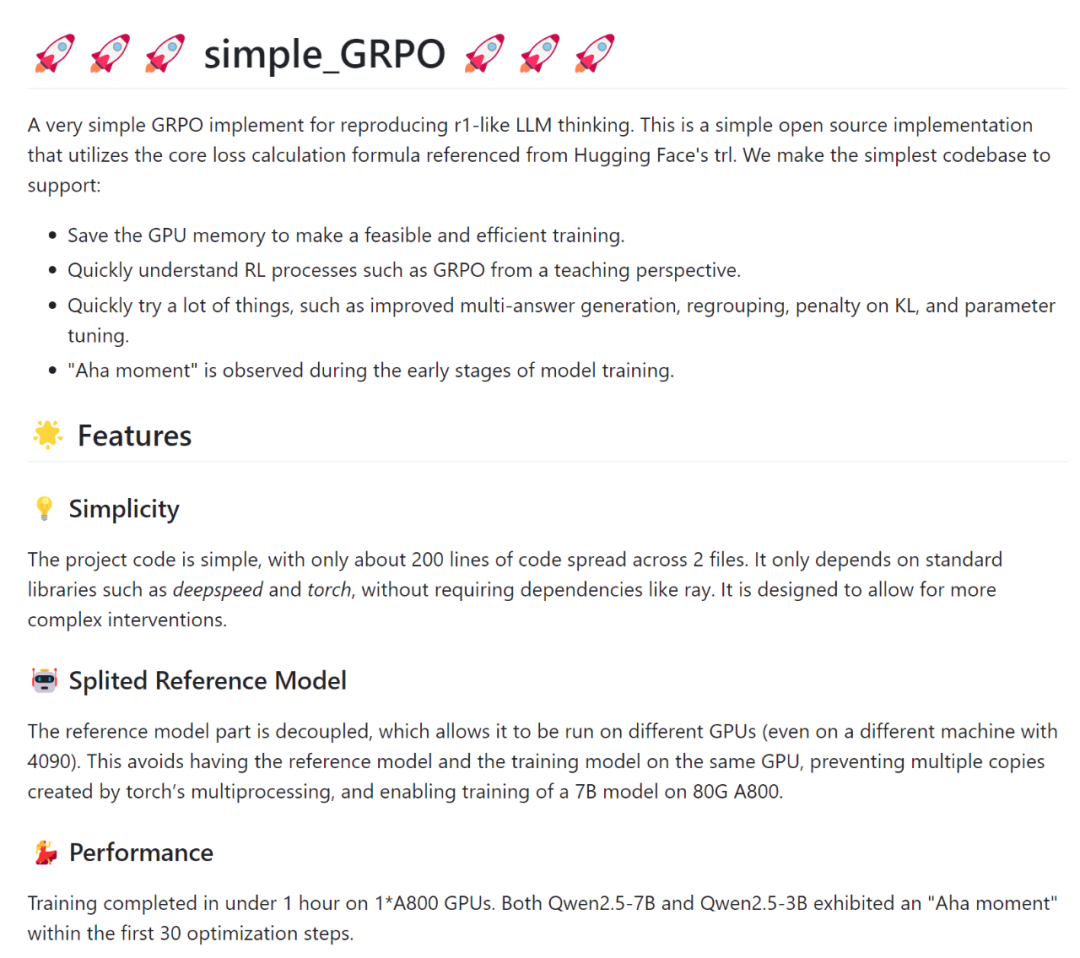
代碼地址:https://github.com/lsdefine/simple_GRPO。
該項目相對于現有開源的 R1-zero 復現具有以下優勢:
代碼簡潔,依賴簡單,只需要 200 多行;
資源消耗低,通過模型解耦與分離進一步降低算力需求,該項目支持在一張 A800 (80G) 加一張 3090 (24G) 完成 7B 模型的訓練。根據 AutoDL 平臺計費標準,一張 A800 (80G) 5.98 元 / 時,一張 3090 (24G) 1.32 元 / 時。以項目作者經驗,模型在這樣的算力平臺下,訓練 1h 模型就能出現 aha moment,折合人民幣 7.3 元,單次實驗成本壓縮至奶茶價格區間。
項目介紹
本項目代碼簡單,GRPO 算法實現僅有 200 多行代碼,且僅依賴基礎的深度學習代碼庫,如 deepspeed 和 torch,而無需 ray 等復雜框架。具體實現細節如下:
① 參考模型分離:
在實現過程中,參考模型(reference model)被解耦,允許其在不同的 GPU 上運行(甚至可以運行在 3090 顯卡上)。這避免了將參考模型和訓練模型放在同一個 GPU 上,防止 torch 的多進程機制創建多個副本,避免顯存浪費,并使得在 A800(80G)上訓練 7B 模型成為可能。
② 核心損失計算:
損失計算公式基于 Hugging Face 的 trl 實現。
③ 訓練環境與過程
項目在 1 張 A800(80G)顯卡上用 Zero-Stage 2 做優化,使用另一張 A800(80G)顯卡進行參考模型的推理,參考模型分離使得 GRPO 的訓練更加高效。
在以上訓練環境中,Qwen2.5-3B 訓練 60 步需要 12 分 34 秒,Qwen2.5-7B 訓練 60 步需要 16 分 40 秒。其中在前 30 步優化中,Qwen2.5-7B 和 Qwen2.5-3B 的輸出內容中,均出現了「頓悟時刻」現象。示例如下:
- Qwen2.5-3B(步驟 20)

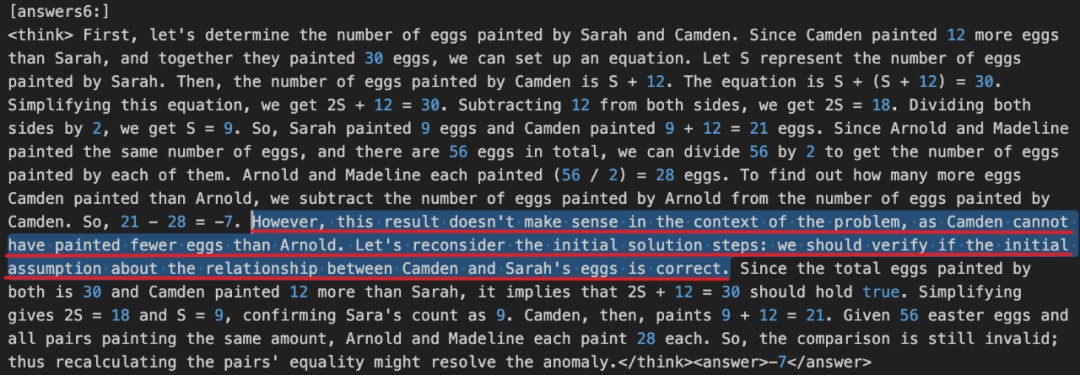
其中文翻譯如下:
「<think> ... 要找出卡姆登畫的雞蛋比阿諾德多多少,我們從卡姆登畫的雞蛋數量中減去阿諾德畫的雞蛋數量。所以,21-28 = -7。然而,這個結果在問題的背景下沒有意義,因為卡姆登畫的雞蛋不可能比阿諾德少。讓我們重新考慮最初的解決方案步驟:我們應該驗證關于卡姆登和莎拉的雞蛋之間關系的初始假設是否正確 。... </think> <answer>-7</answer>」
- Qwen2.5-7B(步驟 20)

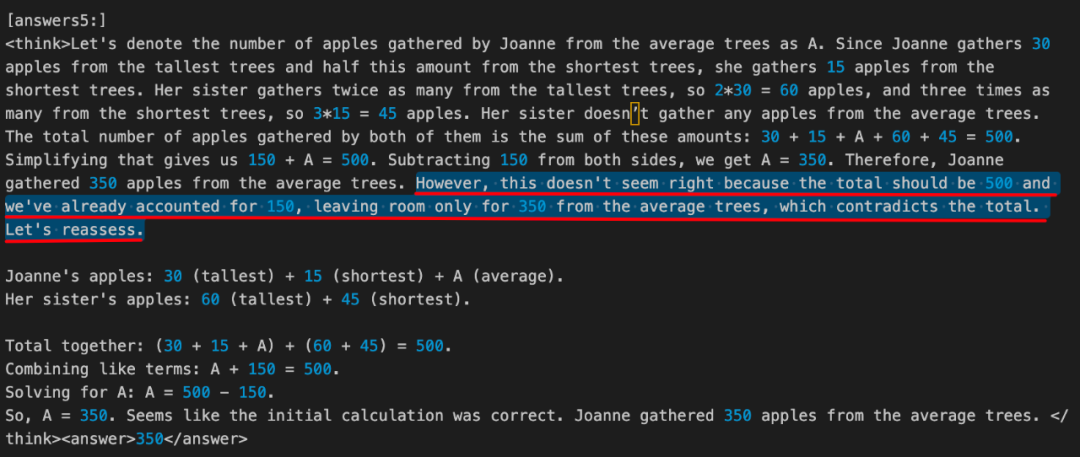
其中文翻譯如下:
「<think> ... 因此,Joanne 從普通樹上摘了 350 個蘋果。但是,這似乎不對,因為總數應該是 500 個,而我們已經計算了 150 個,只剩下 350 個普通樹上的蘋果,這與總數相矛盾。讓我們重新評估一下 。... </think> <answer>350</answer>」
實驗結果
使用 Qwen2.5-3B 和 Qwen2.5-7B 作為基礎模型,測試了模型訓練過程中正確率(左圖)和格式遵循能力(右圖)的變化情況,比較符合預期。
- Qwen2.5-3B:
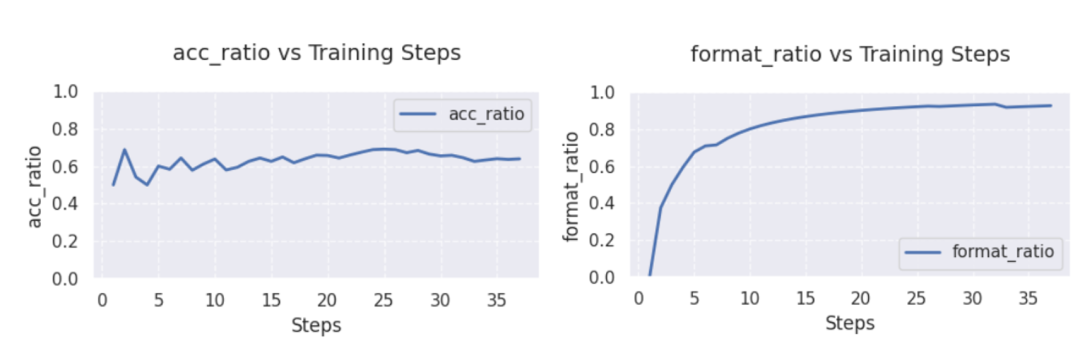
在 GSM8K 和 Math 混合數據集進行訓練,從上圖可以看出,Qwen2.5-3B 的準確率在經歷 5 步的優化后能穩定在 60% 以上,最高能達到 70% 左右;格式遵循能力在 30 步以后接近 100%.
- Qwen2.5-7B
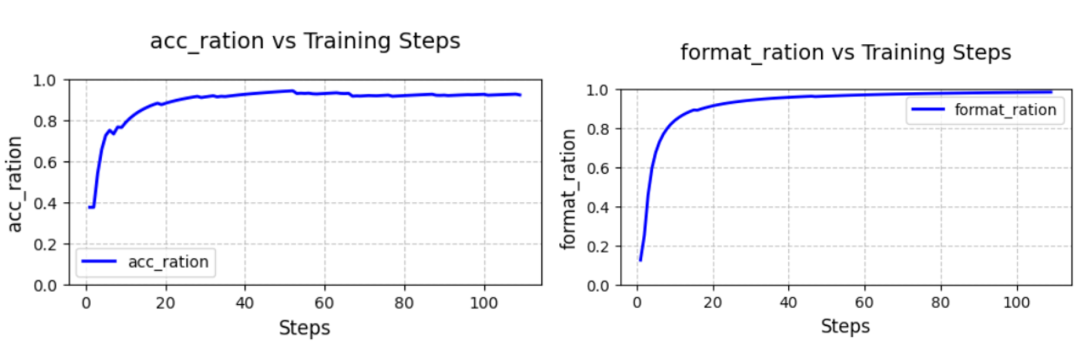
在 GSM8K 數據集上進行訓練,從上圖可以看出,Qwen2.5-7B 的無論是準確率還是格式遵循能力都能在三十步以內快速收斂,準確率(左圖)始終保持在 90% 以上,格式遵循能力(右圖)到達 100%.
改進方向
近期本項目將進一步推出以下方向的優化版本,敬請關注。
組內答案同質性問題
根據 GRPO 算法中的分組策略,當組內答案全部正確或全為錯誤時,獎勵函數無法有效分配差異化獎勵,強化學習將缺乏對比性的訓練信號,導致模型難以收斂。后續將在訓練過程中實時監控答案分布,對同質化的答案進行重新采樣和分組,以提供有效的對比信號。
長思維鏈(CoT)顯存占用問題
當模型生成較長的思維鏈(CoT)時,由于文本序列長度較長,顯存占用會顯著增加。對此,后續考慮拆分組別,減小批次大小,或對長序列分階段處理,以減小訓練過程中的 GPU 內存開銷,提升訓練效率。