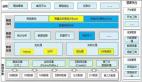
大數據思考:面對海量數據時,選擇哪種模式才是更適合自己的?
如果您從事科技行業或者您不在這個行業,也許您已經聽說過很多關于 AI 的信息。 我所說的不僅僅是多年來我們都喜歡的科幻小說中“天網正在接管地球”式的人工智能,而是人工智能和機器學習已經逐漸成為我們日常生活中的實際應用。
大數據是人工智能與機器學習的 生命線和支柱。 龐大的數據,或者說海量數據,一直驅動著當今的人工智能與機器學習的發展。雖然我們總是希望數據量越大越好,但近年來組織已經開始從追求大數據轉向選擇小而寬。
讓我們比較一下兩者。
延伸閱讀,點擊鏈接了解 Akamai Cloud Computing
大量的數據
大數據可以分為兩種方式。
第一種是收集和組織大型數據集——這是一個可能難以良好執行的簡單概念。 該過程需要大量快速填充且通常是非結構化數據。 容納此數據流的后端基礎設施是資源密集型的,會涉及到網絡帶寬、存儲空間和處理能力以支持大規模數據庫部署,并且 通常價格昂貴。
第二種方法將變得更棘手。 在擁有大量數據后,您需要從中提取所需的洞察力與價值。 技術已經發展以適應大數據的規模,但在確定可以從這些堆積如山的信息中得出什么方面卻進展較少。
是時候變得更聰明了。 即使是無限存儲空間和完美NoSQL部署的環境,如果沒有合適的模型來匹配,世界上所有的數據都將毫無意義。
這其中也蘊含了機會。 一些公司正在尋找更多來源的更少數據更實用的用例,并從數據集中得出更好的結論和相關性。
小而寬
通過“小而寬”的方法,您可以查看更多種類的來源,搜索相關性,而不僅僅是增加原始數量。 這種更具戰術性的方法需要更少的數據,從而減少計算資源。從小到大意味著尋找不同的數據格式,結構化和非結構化,并找到它們之間的聯系。
根據 Gartner 2021 年的一份報告:“可以使用小數據和大數據的潛在領域是零售業的需求預測、應用于超個性化的客戶服務中的實時行為和情感智能,以及客戶體驗的改善。”
潛力看上去很大,但在實踐中看起來又是怎樣的呢? 海量數據集可能會很快變得笨拙或過時。 在信息時代,人類趨勢和行為可能會突然發生變化,容易發生文化和經濟轉變。 使用可以動態適應這些變化的較小數據集的更敏捷模型還有空間。
哈佛商業評論的一份報告解釋說,“組織中許多最有價值的數據集都非常小:想想千字節或兆字節,而不是艾字節。 因為這些數據缺乏大數據的數量和速度,所以它經常被忽視,在PC和功能數據庫中萎靡不振,并且與企業范圍的IT創新計劃無關。”
報告描述了他們與醫學編碼人員進行的一項實驗,該實驗強調了用小數據訓練 人工智能時的人為因素。 我建議通讀這項研究,但最終的結論是,除了小數據之外,考慮人為因素可以改進模型,并使組織在大數據軍備競賽中具有競爭優勢。
換句話說,我們探討的是小數據、大數據和智能數據的成功組合。
結論推導
這一切意味著什么呢?我們在前面已經描述了很多,最后簡單舉一個例子來總結:雖然我希望擁有一臺足夠強大的電腦,但它的發熱量足以成為我的家庭或辦公室的加熱源,并且未來總有一天它會遇到問題,比如一個缺乏優化的軟件依然會在這臺性能強大的機器上以糟糕的方式運行,即使我們使用了高端的工作站,也無法逃脫這樣的問題。
在多數情況下,將更多資源投入到一個問題上是不切實際的,而且會讓人們忽視真正的問題。 更常見的情況是,有一個很好的改進機會擺在面前,這就是我們今天開始看到的大數據。 仍然存在確實需要大量數據的用例,但通過設計模型來充分利用數據也是至關重要的,而不僅僅是依靠設計方法來獲得最多數據。
—————————————————————————————————————————————————
如您所在的企業也在考慮采購云服務或進行云遷移,
點擊鏈接了解Akamai Linode的解決方案