Java并發編程:Synchronized 的優化機制
在上一篇文章中,我們學習了 Synchronized 的底層實現原理、JDK1.6 在偏向鎖、輕量級鎖上對 Synchronized 的優化,以及從偏向鎖,到輕量級鎖,再到重量級鎖的升級過程。今天我們繼續看看 JDK1.6 對 Synchronized 的還做了哪些其他優化,以及 Synchronized 的作用。
我們知道,Synchronized 鎖在升級操作后,有很大可能會變成重量級鎖,這種情況開銷會很大。開銷大的原因是因為 Synchronized 是基于底層操作系統的 Mutex Lock 實現的,每次獲取和釋放鎖操作都會帶來用戶態和內核態的切換,從而增加系統性能開銷。下面我們介紹一下用戶態和內核態。
用戶態和內核態
用戶態(User Mode)指的是當進程在執行用戶自己的代碼時,則稱其處于用戶運行態。而當一個任務(進程)執行系統調用而陷入內核代碼中執行時,我們就稱進程處于內核運行態,此時處理器處于特權級最高的內核代碼中執行。
 圖片
圖片
區分了用戶態和內核態后,程序在執行某個操作時會進行一系列的驗證和檢驗,確認沒問題之后才可以正常的操作資源,這樣就不會擔心一不小心就把系統搞崩潰的問題了,可以讓程序更加安全地運行,但用戶態和內核態這兩種形態的切換,也會導致一定的性能開銷。
自適應自旋鎖
在有些場景下,對象鎖的鎖狀態只會持續很短一段時間,短時間內頻繁地阻塞和喚醒線程是非常不值得的。 正是為了解決這一問題,我們引入了自旋鎖。
簡單來說,自旋鎖就是指通過自身循環,嘗試獲取鎖的一種方式。自旋鎖在 JDK 1.4.2 中引入時,默認為關閉,需要通過參數 -XX:+UseSpinning 開啟。而到之后的 JDK1.6 中,自旋鎖則默認為開啟,同時自旋的默認次數為 10 次。我們可以通過參數-XX:PreBlockSpin 來調整自旋的默認次數。但是,如果通過參數-XX:preBlockSpin 來調整自旋鎖的自旋次數,會帶來諸多不便。
我們舉一個實際的例子來說明:我將參數-XX:preBlockSpin 調整為 10,自旋 10 次后若還沒有獲取鎖就退出。但在你剛剛退出的時候,可能有的線程就釋放了鎖,也就是說,在這種情況下,其實你多自旋一兩次其實就可以獲取鎖。所以我們能看到, 即使可以調整參數,也還是不能徹底解決問題,于是 JDK1.6 引入自適應的自旋鎖。
所謂自適應就意味著自旋的次數不再是固定的,而是由前一次在同一個鎖上的自旋時間,以及鎖的擁有者狀態來決定的。
線程如果自旋成功了,那么下次自旋的次數會更加多。這是由于虛擬機會認為既然上次成功了,那么此次自旋也很有可能會再次成功,所以它就會允許自旋等待持續的次數更多。反之,如果對于某個鎖,很少有自旋能夠成功的,那么以后在獲取這個鎖的時候,自旋的次數會減少甚至省略掉自旋過程,以免浪費處理器資源。
下面這張圖展示了一個線程 T1 嘗試獲取鎖的操作,簡單來說:如果獲取鎖失敗,則將保持自旋;如果獲取鎖成功,就將跳出循環,開始業務邏輯。
 圖片
圖片
有了自適應自旋鎖,在程序運行和性能監控信息的不斷完善的情況下,虛擬機對程序鎖的狀況預測會越來越準確,虛擬機會變得越來越聰明。對于 Synchronized 關鍵字來說,它的自旋鎖更加地“智能”,并且 Synchronized 中的自旋鎖也是自適應自旋鎖。
自旋鎖的優點在于它避免了一些線程的掛起和恢復操作,因為掛起線程和恢復線程都需要從用戶態轉入內核態,這個過程是比較慢的,所以通過自旋的方式可以在一定程度上避免線程掛起和恢復時,所造成的性能開銷。但是,如果長時間自旋還獲取不到鎖,那么也會造成一定的資源浪費,所以我們通常會給自旋設置一個固定的值來避免一直自旋帶來的性能開銷。
鎖的優化機制
接下來,我們一起來看一下鎖的優化機制,其中會著重介紹到鎖膨脹、鎖消除以及鎖粗化的原理和實際操作。從中你能看到 Synchronized 在幾種鎖之間的狀態變化、用來加速程序運行的鎖消除操作,以及提升程序執行效率的鎖粗化操作。
鎖膨脹
鎖膨脹是指 Synchronized 從無鎖升級到偏向鎖,再到輕量級鎖,最后到重量級鎖的過程,也就是我們上一節提到的鎖升級。
 圖片
圖片
在 JDK 1.6 之前,Synchronized 是重量級鎖,在釋放和獲取鎖時會從用戶態轉換成內核態,這個時候轉換的效率是比較低的。JDK 從 1.6 開始,就引入了鎖膨脹機制,Synchronized 的狀態就多了無鎖、偏向鎖以及輕量級鎖。這個時候在進行并發操作時,大部分的場景就不需要從用戶態轉換到內核態了,也因此 Synchronized 的性能得到了大幅度的提升。
鎖消除
鎖消除是指在某些情況下,JVM 虛擬機如果檢測不到某段代碼被共享或競爭的可能性,那么就會將這段代碼所屬的同步鎖消除掉,從而達到提高程序性能的目的。
鎖消除的依據是逃逸分析的數據支持,就像 StringBuffer 的 append() 方法,或 Vector 的 add() 方法,在很多情況下都是可以進行鎖消除的。我們來看下面這個代碼示例:
public String method() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append("i:" + i);
}
return sb.toString();
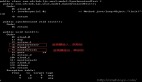
}以上代碼經過編譯之后的字節碼如下:
 圖片
圖片
從上述字節碼結果可以看出,之前我們寫的線程安全的、加鎖的 StringBuffer 對象,在生成字節碼之后就被替換成了線程不安全的、不加鎖的 StringBuilder 對象了。原因是 StringBuffer 的變量屬于一個局部變量,不會從該方法中逃逸出去,此時我們就可以使用鎖消除來加速程序的運行。
鎖粗化
鎖粗化指的是,將多個連續的加鎖、解鎖操作連接在一起,擴展成一個范圍更大的鎖。我們知道縮小鎖的范圍后,在鎖競爭時,等待獲取鎖的線程可以更早地獲取鎖,提高程序的運行效率,這系列的操作,我們稱之為鎖“細化”。
鎖細化的觀點在大多數情況下都是成立的,但是一系列連續加鎖和解鎖的操作,也會導致不必要的性能開銷,從而影響程序的執行效率,所以我們才需要進行鎖粗化的操作。那么鎖粗化是如何提高性能的呢?我們來看下面的例子:
public String test() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++) {
// 加鎖操作
// ...
sb.append("i:" + i);
// 偽代碼:解鎖操作
// ...
}
return sb.toString();
}這里我們不考慮編譯器優化的情況。我們可以看到每次 for 循環都需要進行加鎖和釋放鎖的操作,性能是很低的;但如果我們直接在 for 循環的外層加一把鎖,那么對于同一個對象操作這段代碼的性能就會提高很多,如下代碼所示:
public String test() {
StringBuilder sb = new StringBuilder();
// 加鎖操作
// ...
for (int i = 0; i < 10; i++) {
sb.append("i:" + i);
}
// 解鎖操作
// ...
return sb.toString();
}鎖粗化的作用:如果檢測到同一個對象執行了連續的加鎖和解鎖的操作,則會將這一系列操作合并成一個更大的鎖,從而提升程序的執行效率。其表現為,分散在不同地方的 Synchronized 語句塊會根據代碼邏輯自動合并。JVM 會根據 Synchronized 加鎖解鎖的總時間開銷來自行決定合并 Synchronized 語句塊的時機。
總結
今天我們首先介紹了一下用戶態和內核態的內容。通常我們的應用代碼都是用戶態的,會和系統的內核交互,這樣做的好處是保證系統權限的安全。之后,我們介紹了 JVM 底層對鎖的幾種優化方式,其中自旋可能是大家最為熟悉的操作。但要注意的是,在很多 CAS 的場景中需要我們手動地通過編碼的方式完成自旋操作,而本文提到的自旋是 JVM 底層幫我們做的事情,這是大家要注意區分的地方。
從 JDK1.6 開始,JVM 幫我們實現的自旋,變得很智能,可以自動選擇自旋的次數。此外 JVM 可以根據代碼的實際運行情況自動地對鎖進行升級,這是另一個體現 JVM 對鎖實現智能控制的地方。鎖膨脹是 Synchronized 的核心,Synchronized 通過偏向鎖轉化到輕量級鎖再轉化到重量級鎖來完成膨脹過程;而鎖的消除和粗化更像是一對相關的操作,消除是讓不必要的 Synchronized 語句塊消失,而粗化是讓多個小的 Synchronized 合并成一個大的 Synchronized 語句塊。