加Log就卡?不加Log就瞎?”——這個插件治好了我的精神內耗
1.現有日志打印情況
??日志作為軟件工程實踐中的重要基礎設施,在系統監控、異常診斷及行為追溯等關鍵環節發揮著不可替代的作用。Apache Log4j2作為當前主流的日志框架,憑借其模塊化架構和高度可擴展的特性,為開發者提供了靈活的多維度日志管理方案。然而若未能深入理解其異步日志機制、緩沖區策略等核心原理,或存在配置參數與業務場景匹配度不足等問題,則可能導致日志I/O阻塞、內存資源過度消耗等負面效應,甚至引發嚴重的服務性能瓶頸。因此,在實際工程實踐中需遵循科學合理的使用準則,通過日志分級管理、輸出格式優化、滾動策略定制等手段,方能充分發揮其技術優勢,有效規避潛在風險。
1)日志阻塞
??日志導致線程Block的問題,相信你或許已經遇到過,對此應該深有體會;或許你還沒遇到過,但不代表沒有問題,只是可能還沒有觸發而已。常見的現象是出現大量的block線程,查看jstack常常是下圖現象:
2)從調試到生產,日志策略的抉擇
??在軟件項目的全生命周期中,從開發階段到生產環境的演進過程中,日志管理往往面臨著微妙的平衡。開發階段我們傾向于采用詳盡的日志策略:業務接口的入參出參被完整記錄,跨系統的調用鏈路被清晰標注,甚至非核心邏輯的輔助性信息也得以留存——這些詳實的日志如同開發者的雙目,為聯調排障與功能驗證提供了不可或缺的洞察。
??然而當服務邁向生產環境時,過度日志帶來的問題便逐漸顯現。冗余的調試信息不僅會影響系統性能,更可能淹沒真正關鍵的業務軌跡。盡管我們嘗試在上線前進行日志裁剪,但總存在令人躊躇的灰色地帶:某些開發期輔助日志是否暗含未來的診斷價值?那些看似非核心的流程記錄會否在某個異常場景下成為關鍵線索?這種取舍的困境,本質上反映了我們對系統可觀測性與運行效能之間永續的權衡。
2.問題出現原因
2.1 日志打印原理分析
??在我們使用的log4j的應用中采用的是異步日志配置,簡單的說明一下一條日志打印在log4j中的處理流程如下圖所示:
 圖片
圖片
??簡單點來說,就是多線程通過 log4j2 的門面類進行日志的打印,日志經過一系列的處理(過濾,包裝)后放入到Disruptor的環形 buffer 中,在服務器的消費端會單啟一個線程進行這些日志的消費,最終放入到我們指定的文件中。
2.2 log4j2 Disruptor 的初始化
??當LoggerContext啟動時,所有AsyncLoggerConfig會通過start()方法初始化其Disruptor:
 圖片
圖片
??其中Disruptor 是一個環形 buffer,官方做了很多的性能優化,這里有興趣的可以了解其實現原理,這里不進行深入的討論,其中在我們的應用log4j.xml配置中,沒對RingBuffer進行自定義的配置,使用的是默認的大小256K。
2.3 隊列滿導致日志阻塞
??Disruptor 的 RingBuffer 是一個固定大小的環形隊列,其發布邏輯:
 圖片
圖片
??隊列滿時的默認行為:AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=true,此時會等待著消費出下一個可以生產的環形 buffer 槽;此時所有打印日志的線程會嘗試獲取全局鎖。此時會阻塞線程,也就是我們上述堆棧中看到的異常。
2.4 產生的根本原因
??生產者速度 > 消費者速度:
??AsyncAppender 的后臺線程從隊列中取出事件并交給實際 Appender(如 FileAppender)處理,如果實際 Appender 的寫入速度慢(如磁盤 I/O 高),消費者線程無法及時清空隊列,導致隊列積壓。其實log4j消費時會調用多次 flush,這些flush的調用根本在文件寫入的 native 調用,當這種native調用太多時,系統寫入不過來。
3 應對方案
3.1 方案選擇
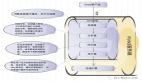
??上述問題情況解決,大致分成兩個方向:生產者方向&消費者方向,具體行為如下圖簡述:
 圖片
圖片
??在應對日志管理的挑戰時,除了調整日志隊列容量等基礎優化(需警惕OOM風險),更核心的問題在于如何平衡日志的詳實性與系統穩定性。開發者往往陷入兩難:若詳盡記錄日志,可能引發阻塞風險;若過度精簡,則排查問題時如盲人摸象,難溯根源。
為此,可考慮將日志劃分為兩類:
功能日志(必須):如埋點數據、核心流程記錄,確保業務可觀測性;
業務排查日志(非必須):如RPC入參/出參、調試斷點等,按需動態啟停;
??通過這種分層策略,既能在高并發場景下保障核心日志的穩定輸出,又能靈活控制輔助日志的打印量,使系統整體具備更強的適應性與可控性。如此,我們既能從容應對生產環境的嚴苛要求,又能在需要時快速激活詳盡的診斷信息,實現運維效率與系統性能的兼得。
3.2 技術選擇
??在日志打印的精細化控制中,核心在于靈活性與精準度的平衡。傳統的全局級別過濾(如INFO/WARN/ERROR)雖能粗放管理,卻難以適配復雜多變的業務場景。理想的方案應突破層級限制,實現行級細粒度控制——無論是核心鏈路的關鍵節點,還是特定業務場景的臨時調試,均可針對單行日志動態啟停。
??這種設計賦予開發者更高的自主權:業務視角:按需捕獲特定模塊的完整上下文;鏈路視角:精準聚焦某次調用的全生命周期軌跡;應急場景:即時激活深層診斷日志,無需重啟或改碼。
??通過將控制粒度細化至代碼行,我們既能維持生產環境的日志精簡,又能隨時按業務訴求“點亮”關鍵路徑,使系統可觀測性兼具嚴謹與彈性。
3.2.1 區分必要日志和非必要日志打印:
?自定義封裝日志打印的方式如下圖所示:
 圖片
圖片
3.2.2 如何對非必要日志進行行級別控制
?1)自定義Appender中的filter:
??在實現行級日志控制時,若需精確控制特定代碼行(如第133行)的日志輸出,采用自定義Appender過濾機制是一種可行方案。其核心思路在于:通過解析日志調用的堆棧信息,動態判斷當前行號是否符合預設的打印條件,若不符合則直接過濾。
??然而,該方案存在若干固有局限: 堆棧解析的可靠性問題:Lambda表達式中的日志調用往往難以準確獲取行號信息,即使通過堆棧緩存優化,仍存在定位失準的風險;性能損耗隱患:頻繁的堆棧遍歷操作會引入不可忽視的性能開銷,在高并發場景下可能成為新的瓶頸;分類管理缺失:該機制難以與既有的日志分級體系(必需/非必需日志)形成有機協同,增加了運維復雜度。
?2)在打印日志前獲取日志的行信息:
??最簡單的方式是人工的形式,在寫日志的時候同時將日志的行信息寫入進去,比如: 這種方式在可擴展性和可觀測性維度存在設計缺陷。
這種方式在可擴展性和可觀測性維度存在設計缺陷。
?3)在編譯的時候獲取日志的行信息:
??我們想使用LogUtils.debug(()->log.info("業務日志"));這種方式,但是我們不會在代碼中明顯的寫入,可以在代碼編譯期間將行信息獲取到后使用字節碼修改這行代碼,利用Java的重寫。將它轉變成 LogUtils.debug("類+行",()->log.info("業務日志")); 然后再這個方法執行中進行條件判斷。
字節碼技術選擇:
 圖片
圖片
??在本次實現中需要更靈活的方式操作字節碼,還要考慮性能的問題,以及對應用框架的支持, 我們選擇ASM的形式。
4)如何隨心控制開啟和關閉:
??這里我們采用的是ider插件的方式,有idea插件上報我們的對這行日志的控制行為,如下圖所示:
 圖片
圖片
3.3 落地實現
3.3.1 Maven編譯插件
??目的:獲取日志所在的類和行信息。
??運行時獲取的方式:在 Logger 配置中啟用 includeLocation,代碼從 LogEvent通過堆棧分析獲取行號。這種方式存在很大的弊端,堆棧跟蹤生成開銷很大,每次調用 getStackTrace() 時,JVM 需要遍歷當前線程的調用棧,生成完整的堆棧信息,這是一個 同步且耗時 的操作(尤其在深調用鏈中),如果每秒有數萬次日志調用,頻繁生成堆棧跟蹤可能導致 CPU 使用率飆升,直接影響吞吐量。
?? Maven的process-classes階段獲取:通過Maven編譯之后獲取到字節碼文件時,對字節碼文件進行修改,存放日志的類和行信息。對運行期間無額外消耗。處理邏輯如下圖所示:
 圖片
圖片
3.3.2 Idea插件
??目的:精準的控制某一行日志是否進行打印。
??利用Idea的插件能力,將我們對某一行日志的開啟和關閉狀態進行上報,整個過程不阻塞主線程,保持Idea操作流暢性。提供定時能力,保障線上我們可以更靈活的控制日志是否打印的狀態。處理邏輯如下圖所示;
 圖片
圖片
3.3.3 整體流程
??使用方式:通過在項目中使用上述Maven插件對項目進行編譯部署,使用Idea插件對目標日志的是否開啟打印狀態進行上報,存儲狀態采用的Apollo的能力,通過自定義打印工具類中對Apollo配置內容的分析,進一步做判斷邏輯,最終將日志進行打印或者不打印。處理邏輯如下圖所示:
 圖片
圖片
4.總結
??在分布式系統日益復雜的今天,日志管理已從簡單的信息記錄演進為系統可觀測性的核心支柱。本文揭示的日志阻塞與策略困境,折射出現代化服務在穩定性與可維護性之間的深層博弈。通過剖析Log4j2異步日志機制的內在原理,我們識別出隊列積壓導致線程阻塞的關鍵癥結,并由此展開對日志治理體系的深度重構。
??本次優化方案突破傳統日志分級思維的桎梏,創新性地提出雙軌制日志管理體系:將日志劃分為功能型與診斷型兩類,前者確保核心業務脈絡的持續可見,后者實現按需動態管控。通過編譯期字節碼增強技術,我們實現代碼行級別的精準控制,配合IDE插件的可視化操作,使開發人員能夠像調試斷點般自由啟停日志輸出。這種"外科手術式"的日志管理,既避免了傳統方案"一刀切"的弊端,又賦予系統在高負載場景下的彈性適應能力。
關于作者:蔡夢輝 平臺技術部后端