AI 與非結構化數據:簡單 RAG 的局限及生產級解決方案全解析
非結構化數據涵蓋了電子郵件、PDF 文件、會議記錄等多種形式,它們充斥在各個角落,卻由于缺乏固定的格式,給傳統的數據處理工具帶來了巨大的挑戰。而人工智能(AI)的出現,尤其是大型語言模型(LLMs),為解決非結構化數據的難題帶來了新的希望。但在實際應用中,簡單的檢索增強生成(RAG)方法卻存在諸多不足,無法滿足復雜的生產級場景需求。本文將深入探討這些問題,并詳細闡述如何構建適用于生產環境的有效解決方案。
簡單 RAG 為何行不通:深入剖析
RAG 作為 AI 領域的熱門技術,將檢索和生成相結合,理論上能夠從大量數據中找到相關信息并生成答案。但在實際應用中,它存在著諸多局限性。
實際案例 1:缺乏上下文和精確性
假設在研究論文和報告的語料庫中搜索 “具有戰略領導經驗的可再生能源專家”。簡單的 RAG 系統可能會檢索到包含 “可再生能源” 和 “領導” 這兩個詞的文檔,但很可能會忽略一些關鍵細節。如果一篇論文討論的是 “可持續能源戰略”,但沒有直接使用 “可再生能源” 這個短語,RAG 系統就可能會遺漏這篇文檔,因為它過度依賴詞匯的相似性。更糟糕的是,大型語言模型在生成回答時,可能會在沒有核實戰略角度的情況下,將 “領導” 和 “項目管理” 混淆,從而給出模糊或錯誤的答案。
實際案例 2:可擴展性和延遲問題
當處理數百萬份文檔時,比如十年的客戶反饋數據,簡單 RAG 系統的問題就會更加凸顯。由于向量相似性過于寬泛,它可能會檢索到大量不相關的文本塊,這不僅會拖慢響應時間,還會讓大型語言模型在篩選信息時感到困惑。例如,當詢問 “客戶對產品可靠性有什么看法” 時,系統可能會返回數千個提到 “產品” 和 “問題” 的文本塊,但其中很多可能是關于定價或運輸延遲等無關話題的。這樣一來,大型語言模型很難從中提取出有用的信息,導致回答不一致或不完整。
實際案例 3:缺乏控制和可解釋性
在使用簡單 RAG 時,用戶往往對檢索和生成的內容缺乏精細的控制。如果用戶要求 “顯示 2023 年討論數據隱私的法律文件”,RAG 系統可能僅僅根據向量相似性來檢索文檔,忽略了 “日期” 和 “主題” 等關鍵結構化篩選條件。最終生成的輸出可能只是一個通用的摘要,難以進行驗證和審計,這對于受監管的行業來說是完全不可接受的。
正確的方法:適用于生產的藍圖
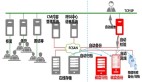
那么,如何構建一個能夠超越簡單 RAG 和簡單 AI 聊天機器人局限性的生產級解決方案呢?這需要一個全面的方法,包括使用大型語言模型結構化數據、進行文本分塊以提高效率、生成向量嵌入以理解語義,以及使用混合搜索引擎進行搜索。
利用 LLMs 和提示將非結構化數據轉換為結構化洞察
首先要面對的挑戰是將雜亂無章的非結構化數據轉化為可用的形式。這就需要借助大型語言模型和精心設計的提示。用戶可以將非結構化數據輸入到大型語言模型中,這些模型可以在本地托管,也可以通過像 Hugging Face Inference 這樣的平臺進行訪問。關鍵在于使用有針對性的提示來引導大型語言模型的輸出。
例如,對于一系列研究論文,可以設計這樣的提示:“從每份文檔中提取以下內容:標題、作者、出版日期、摘要(不超過 200 字)以及關鍵主題。將輸出格式化為每個類別都有相應字段的 JSON 格式。” 大型語言模型會根據對語言的理解,對每份文檔進行處理,將相關信息識別并組織成結構化的字段。
對于更復雜的情況,如客戶反饋或法律合同,提示可以進一步細化。假設處理客戶電子郵件,可以設計這樣的提示:“對于每封電子郵件,識別發件人、收件人、日期、情感(積極、消極、中性)、主要主題(如產品問題、賬單問題)以及緊急程度(高、中、低)。將結果以結構化的 CSV 格式返回。” 大型語言模型的推理引擎會分析文本,利用其預訓練的知識推斷語義和關系,輸出清晰的、機器可讀的數據。
為了優化成本和性能,用戶可以使用 RunPod、vLLM 或 SGLang 等工具來托管自己的大型語言模型。在進行初始批量加載時,可以在 RunPod 上部署 vLLM,一次性處理數千份文檔,并使用連續批處理來最小化內存使用和成本。SGLang 的優化推理內核可以進一步加快令牌生成速度,確保即使是大型數據集也能高效地進行結構化處理。這樣的方法使得用戶可以在不依賴昂貴的云 API 的情況下擴展推理能力,非常適合生產環境。
一旦大型語言模型輸出了結構化數據,如 JSON 或 CSV 文件,用戶就有了進一步構建的基礎。每份文檔現在都有了相關的元數據(如 “標題”“日期”“主題”),可以通過分塊和向量化進行進一步的豐富,以實現高級搜索。
在 Elasticsearch 中存儲數據:為何它是正確的選擇
有了結構化數據后,下一步就是存儲和索引。Elasticsearch 作為一個分布式的、基于 RESTful 的搜索和分析引擎,基于 Apache Lucene 構建,非常適合處理這種情況。
Elasticsearch 具有先進的搜索功能。它原生支持基于關鍵詞的 Query DSL 搜索、用于向量搜索的 k 最近鄰(k-NN)算法,以及通過插件或自定義配置實現的混合搜索。這意味著用戶可以同時查詢結構化字段(如 “2023 年的文檔”)和向量空間(如 “與可持續性語義相似的內容”),這是其他系統無法如此無縫實現的。
此外,Elasticsearch 的相關性排名和優化功能也很強大。它使用像 TF-IDF 和 BM25 這樣的評分算法進行詞匯搜索,使用余弦相似度或 L2 距離進行向量搜索,確保結果按相關性進行排名。它還能夠通過互惠排名融合(RRF)等技術將這些方法結合起來,實現混合搜索,平衡精確性和上下文。
將自然語言查詢轉換為 DSL、混合和語義搜索
接下來,讓我們看看用戶如何與這個系統進行交互。目標是讓用戶能夠用自然語言提問,比如 “給我展示具有戰略經驗的可持續性專家” 或 “查找去年討論數據隱私的文檔”,并獲得精確、相關的結果。
用戶通過界面(如 Web 應用程序或 API)輸入查詢,該界面會將自然語言提示傳遞給大型語言模型進行處理。大型語言模型可以通過 Hugging Face、RunPod 或類似的設置進行托管,它會解釋查詢并將其轉換為搜索引擎能夠理解的格式。例如,對于 “給我展示具有戰略經驗的可持續性專家” 這個查詢,大型語言模型可能會將其分解為 “可持續性”(語義概念)、“專家”(角色或領域)和 “戰略經驗”(技能或上下文)等組件。
然后,系統會生成三種類型的查詢,它們協同工作:
- 關鍵詞驅動的 DSL 查詢大型語言模型為 Elasticsearch 構建一個 DSL 查詢,針對結構化字段進行搜索。對于上述示例,它可能生成
{"bool": {"must": [{"match": {"topic": "sustainability"}}, {"match": {"role": "expert"}}, {"match": {"skills": "strategic experience"}}]}}。這樣可以確保在 “主題” 或 “技能” 等字段上進行精確匹配,為需要特定術語的用戶提供精確性。 - 語義向量查詢同時,大型語言模型或專門的嵌入模型(如 Sentence-BERT)會將查詢轉換為向量,然后在 Elasticsearch 中用于 k-NN 搜索。對于 “可持續性與戰略經驗”,該向量可能會找到討論 “綠色能源戰略” 或 “可持續領導力” 的文檔,即使這些確切的短語沒有出現,也會根據余弦相似度進行排名。
- 混合查詢真正的強大之處在于將這兩種查詢結合起來。Elasticsearch 的混合搜索功能允許用戶合并 DSL 和向量搜索的結果,并根據相關性對每個結果進行加權。例如,可以將 DSL 查詢的權重設置為 0.6(以提高精確性),將向量查詢的權重設置為 0.4(以提供上下文),然后使用 RRF 融合排名。這樣可以確保既獲得精確匹配(如明確標記為 “可持續性” 的文檔),又獲得相關概念(如 “環境戰略”),實現兩者的優勢互補。
這些查詢協同工作是因為它們各自利用了不同的優勢。DSL 對于結構化數據的搜索快速且精確,向量搜索對于非結構化數據的洞察靈活且具有上下文感知,而混合搜索則彌補了兩者之間的差距,在準確性和相關性方面進行了優化。大型語言模型就像是一個指揮家,確保自然語言查詢被智能地解析并轉換為正確的搜索組合,而 Elasticsearch 則快速、大規模地執行這些搜索。
整合所有環節以獲得最佳結果
這種方法的美妙之處在于它的協同效應。用戶通過提示大型語言模型來結構化數據、分塊并生成嵌入,這些嵌入隨后在 Elasticsearch 中進行索引,以便存儲和搜索。當查詢進來時,大型語言模型將其轉換為 DSL、向量和混合搜索的組合,Elasticsearch 實時執行這些搜索,并根據相關性對結果進行排名。例如,當用戶詢問 “查找 2023 年關于數據隱私的法律文件” 時,可能會通過 DSL 匹配到 “2023 年” 和 “數據隱私”,通過向量匹配到相關術語(如 “GDPR”),并通過混合排名優先顯示最具上下文相關性的文檔。
這并非只是理論,而是一個適用于生產的藍圖。通過在像 RunPod 這樣具有成本效益的平臺上使用 vLLM 或 SGLang 托管大型語言模型,使用精確的提示來結構化數據,并利用 Elasticsearch 無與倫比的搜索能力,用戶可以創建一個可擴展、安全且高效的系統。這不是關于快速修復或花哨的演示,而是關于構建在現實世界中真正有效的 AI,通過每次查詢將非結構化數據轉化為可操作的洞察。