1.8w字圖解Java并發容器框架:并發安全 Map、JUC 集合、Java 7 種阻塞隊列正確使用場景和原理詳解
今天進入 Java 并發編程第二章節,圍繞著并發容器展開,主要內容如下:
- ConcurrentHashMap的使用和原理
- ConcurrentLinkedQueue 的使用和原理
- Java 7 種阻塞隊列使用場景和原理詳解:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、DelayQueue、SynchronousQueue、LinkedTransferQueue以及LinkedBlockingDeque
ConcurrentHashMap 的使用和原理
Map 是一個接口,它的實現方式有很多種,比如常見的 HashMap、LinkedHashMap,但是這些 Map 的實現并不是線程安全的,在多線程高并發的環境中會出現線程安全的問題。
鑒于 Map 是一個在高并發的應用環境中應用比較廣泛的數據結構,Doug Lea 自 JDK 1.5 版本起在 Java 中引入了 ConcurrentHashMap。
ConcurrentHashMap 的使用
對一個技術的掌握,從使用開始。我們現在來實現一個一個高并發計數器,例如記錄網站訪問量、接口調用次數等。
@Service
public class Counter {
private final ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public void increase(String key) {
map.compute(key, (k, v) -> (v == null) ? 1 : v + 1);
}
public int get(String key) {
return map.getOrDefault(key, 0);
}
}- compute :這是一個并發安全原子操作,我們使用 compute 方法實現對計數器的增加操作。
如果 key 不存在則新建一個值為 1 的計數器;
否則將其 value 遞增 1。
- 通過 get 方法可以獲取指定 key 對應的計數器值。
這個例子比較簡單,現在開始上強度。ConcurrentHashMap 還可以用來實現緩存管理器,例如存儲經常使用的業務數據、系統配置等信息,從而避免頻繁的數據庫查詢或網絡請求。
以下是一個支持過期時間、自動刷新和并發控制的緩存管理器實現,包含詳細注釋和最佳實踐:
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicLong;
import java.util.function.Function;
/**
* 高性能并發緩存管理器
* @param <K> 鍵類型
* @param <V> 值類型
*/
publicclass ConcurrentCache<K, V> {
privatefinal ConcurrentHashMap<K, CacheEntry<V>> cache = new ConcurrentHashMap<>();
privatefinal Function<K, V> loader; // 緩存加載器
privatefinal ScheduledExecutorService cleaner; // 過期清理線程
// 默認配置
privatelong defaultTTL = 30_000; // 默認30秒
privatelong cleanupInterval = 5_000; // 5秒清理一次
privateint maxRetries = 3; // 最大重試次數
privateboolean refreshOnAccess = true; // 訪問時刷新TTL
public ConcurrentCache(Function<K, V> loader) {
this.loader = loader;
this.cleaner = Executors.newSingleThreadScheduledExecutor();
startCleanupTask();
}
/**
* 獲取緩存值(線程安全)
*/
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
// 無緩存或已過期時加載
if (entry == null || entry.isExpired()) {
return loadAndCache(key);
}
// 更新訪問時間(可選)
if (refreshOnAccess) {
entry.touch();
}
return entry.value;
}
/**
* 原子性的加載和緩存操作
*/
private V loadAndCache(K key) {
int retry = 0;
while (retry++ < maxRetries) {
try {
// 使用compute保證原子性
CacheEntry<V> newEntry = cache.compute(key, (k, oldEntry) -> {
// 檢查其他線程是否已經加載
if (oldEntry != null && !oldEntry.isExpired()) {
return oldEntry;
}
V value = loader.apply(k);
returnnew CacheEntry<>(value, defaultTTL, TimeUnit.MILLISECONDS);
});
return newEntry.value;
} catch (Exception ex) {
if (retry >= maxRetries) {
thrownew CacheLoadException("加載緩存失敗,key=" + key, ex);
}
// 指數退避重試
sleepUninterruptibly((long) Math.pow(2, retry), TimeUnit.MILLISECONDS);
}
}
thrownew CacheLoadException("超過最大重試次數,key=" + key);
}
/**
* 主動放入緩存(支持自定義TTL)
*/
public void put(K key, V value, long ttl, TimeUnit unit) {
cache.put(key, new CacheEntry<>(value, ttl, unit));
}
/**
* 啟動定期清理任務(雙重檢查鎖模式)
*/
private void startCleanupTask() {
if (cleaner.isShutdown()) return;
cleaner.scheduleWithFixedDelay(() -> {
cache.forEach((key, entry) -> {
if (entry.isExpired()) {
cache.remove(key, entry); // 使用CAS刪除
}
});
}, cleanupInterval, cleanupInterval, TimeUnit.MILLISECONDS);
}
// 其他實用方法
public void remove(K key) { cache.remove(key); }
public void clear() { cache.clear(); }
public long size() { return cache.mappingCount(); }
// 配置方法(Builder模式風格)
public ConcurrentCache<K, V> defaultTTL(long ttl, TimeUnit unit) {
this.defaultTTL = unit.toMillis(ttl);
returnthis;
}
public ConcurrentCache<K, V> cleanupInterval(long interval, TimeUnit unit) {
this.cleanupInterval = unit.toMillis(interval);
returnthis;
}
// 異常處理
privatestaticclass CacheLoadException extends RuntimeException {
CacheLoadException(String message, Throwable cause) {
super(message, cause);
}
CacheLoadException(String message) {
super(message);
}
}
// 工具方法:不可中斷的休眠
private static void sleepUninterruptibly(long duration, TimeUnit unit) {
try {
Thread.sleep(unit.toMillis(duration));
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
// 關閉時釋放資源
public void shutdown() {
cleaner.shutdownNow();
cache.clear();
}
// 緩存條目:包含值、過期時間和訪問時間戳
privatestaticclass CacheEntry<V> {
final V value;
finallong expireAt; // 絕對過期時間(納秒)
final AtomicLong accessTime = new AtomicLong(); // 最后訪問時間(納秒)
CacheEntry(V value, long ttl, TimeUnit unit) {
this.value = value;
this.expireAt = System.nanoTime() + unit.toNanos(ttl);
touch();
}
// 刷新訪問時間
void touch() {
accessTime.set(System.nanoTime());
}
// 判斷是否已過期
boolean isExpired() {
return System.nanoTime() > expireAt;
}
}
}實現原理
- CHM 的源碼有 6k 多行,包含的內容多,精巧,不容易理解;建議在查看源碼的時候,可以首先把握整體結構脈絡,對于一些精巧的優化,哈希技巧可以先了解目的就可以了,不用深究;
- 對整體把握比較清楚后,在逐步分析,可以比較快速的看懂;
- JDK1.8 版本中的 CHM,和 JDK1.7 版本的差別非常大,在查看資料的時候要注意區分,1.7 中主要是使用 Segment 分段鎖 來解決并發問題的。
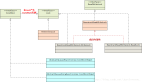
JDK 1.7 版本 ConcurrentHashMap
在 JDK1.7 版本中,ConcurrentHashMap 的數據結構是由一個 Segment 數組和多個 HashEntry 組成。
而每一個 Segment 元素存儲的是 HashEntry 數組+鏈表,并對應一個 ReentrantLock 鎖,用于并發訪問控制。
 圖片
圖片
以 put 操作為例,來看一下 ConcurrentHashMap 的實現過程:
- 首先計算 key 的哈希值;
- 根據哈希值找到對應的 Segment;
- 獲取 Segment 對應的鎖;
- 如果還沒有元素,就直接插入到 Segment 中;
- 如果已經存在元素,就循環比較 key 是否相等;
- 如果 key 已經存在,就根據要求更新 value;
- 如果 key 不存在,就插入新的元素(鏈表或者紅黑樹)。
上述操作中,步驟 2 到 3 相當于對對應的 Segment 加了一個悲觀鎖,如果 Segment 數組只有一個 Segment 元素,效果與 Hashtable 類似;
如果存在多個 Segment,效果就相當于使用了分段鎖機制,提高了并發訪問性能。
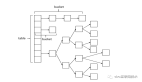
JDK 1.8 ConcurrentHashMap
在 JDK1.8 中,ConcurrentHashMap 的實現原理摒棄了這種設計,而是選擇了與 HashMap 類似的數組+鏈表+紅黑樹的方式實現,而加鎖則采用 CAS 和 synchronized 實現。
 圖片
圖片
其主要區別就在 CHM 支持并發:
- 使用 Unsafe 方法操作數組內部元素,保證可見性;(U.getObjectVolatile、U.compareAndSwapObject、U.putObjectVolatile);
- 在更新和移動節點的時候,直接鎖住對應的哈希桶,鎖粒度更小,且動態擴展;
- 針對擴容慢操作進行優化。
a.首先擴容過程的中,節點首先移動到過度表 nextTable ,所有節點移動完畢時替換散列表 table;
b.移動時先將散列表定長等分,然后逆序依次領取任務擴容,設置 sizeCtl 標記正在擴容;
c.移動完成一個哈希桶或者遇到空桶時,將其標記為 ForwardingNode 節點,并指向 nextTable ;
d.后有其他線程在操作哈希表時,遇到 ForwardingNode 節點,則先幫助擴容(繼續領取分段任務),擴容完成后再繼續之前的操作;
- 優化哈希表計數器,采用 LongAdder、Striped64 類似思想;
- 以及大量的哈希算法優化和狀態變量優化;
- 關注「碼哥跳動」,并設置星標,一起擁抱硬核技術和對象,面向人民幣編程。
類定義和成員變量
// node數組最大容量:2^30=1073741824
privatestaticfinalint MAXIMUM_CAPACITY = 1 << 30;
// 默認初始值,必須是2的幕數
privatestaticfinalint DEFAULT_CAPACITY = 16;
//數組可能最大值,需要與toArray()相關方法關聯
staticfinalint MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//并發級別,遺留下來的,為兼容以前的版本
privatestaticfinalint DEFAULT_CONCURRENCY_LEVEL = 16;
// 負載因子
privatestaticfinalfloat LOAD_FACTOR = 0.75f;
// 鏈表轉紅黑樹閥值,> 8 鏈表轉換為紅黑樹
staticfinalint TREEIFY_THRESHOLD = 8;
//樹轉鏈表閥值,小于等于6(tranfer時,lc、hc=0兩個計數器分別++記錄原bin、新binTreeNode數量,<=UNTREEIFY_THRESHOLD 則untreeify(lo))
staticfinalint UNTREEIFY_THRESHOLD = 6;
staticfinalint MIN_TREEIFY_CAPACITY = 64;
privatestaticfinalint MIN_TRANSFER_STRIDE = 16;
privatestaticint RESIZE_STAMP_BITS = 16;
// 2^15-1,help resize的最大線程數
privatestaticfinalint MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 32-16=16,sizeCtl中記錄size大小的偏移量
privatestaticfinalint RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// forwarding nodes的hash值
staticfinalint MOVED = -1;
// 樹根節點的hash值
staticfinalint TREEBIN = -2;
// ReservationNode的hash值
staticfinalint RESERVED = -3;
// 可用處理器數量
staticfinalint NCPU = Runtime.getRuntime().availableProcessors();
//存放node的數組
transientvolatile Node<K,V>[] table;
/*控制標識符,用來控制table的初始化和擴容的操作,不同的值有不同的含義
*當為負數時:-1代表正在初始化,-N代表有N-1個線程正在 進行擴容
*當為0時:代表當時的table還沒有被初始化
*當為正數時:表示初始化或者下一次進行擴容的大小
*/
privatetransientvolatileint sizeCtl;上面有幾個重要的地方這里單獨講:
LOAD_FACTOR:
這里的負載系數,同 HashMap 等其他 Map 的系數有明顯區別:
- 通常的系數默認 0.75,可以由構造函數傳入,當節點數 size 超過 loadFactor * capacity 時擴容;
- 而 CMH 的系數則固定 0.75(使用 n - (n >>> 2) 表示),構造函數傳入的系數只影響初始化容量,見第 5 個構造函數。
sizeCtl:
sizeCtl 是 CHM 中最重要的狀態變量,其中包括很多中狀態,這里先整體介紹幫助后面源碼理解;
- sizeCtl = 0 :初始值,還未指定初始容量;
- sizeCtl > 0 :
table 未初始化,表示初始化容量;
table 已初始化,表示擴容閾值(0.75n);
- sizeCtl = -1 :表示正在初始化;
- sizeCtl < -1 :表示正在擴容,具體結構如圖所示:
 圖片
圖片
Node 節點
Node 是 ConcurrentHashMap 存儲結構的基本單元,繼承于 HashMap 中的 Entry,用于存儲數據,源代碼如下。
static class Node<K,V> implements Map.Entry<K,V> { // 哈希表普通節點
finalint hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node<K,V> find(int h, Object k) {} // 主要在擴容時,利用多態查詢已轉移節點
}
staticfinalclass ForwardingNode<K,V> extends Node<K,V> { // 標識擴容節點
final Node<K,V>[] nextTable; // 指向成員變量 ConcurrentHashMap.nextTable
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null); // hash = -1,快速確定 ForwardingNode 節點
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {}
}
staticfinalclass TreeBin<K,V> extends Node<K,V> { // 紅黑樹根節點
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null); // hash = -2,快速確定紅黑樹,
...
}
}
staticfinalclass TreeNode<K,V> extends Node<K,V> { } // 紅黑樹普通節點,其 hash 同 Node 普通節點 > 0;哈希計算
static finalint MOVED = -1; // hash for forwarding nodes
staticfinalint TREEBIN = -2; // hash for roots of trees
staticfinalint RESERVED = -3; // hash for transient reservations
staticfinalint HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// 讓高位16位,參與哈希桶定位運算的同時,保證 hash 為正
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}哈希桶可見性
一個數組即使聲明為 volatile,也只能保證這個數組引用本身的可見性,其內部元素的可見性是無法保證的,如果每次都加鎖,則效率必然大大降低,在 CHM 中則使用 Unsafe 方法來保證:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
staticfinal <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
staticfinal <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}put 操作
思路是對當前的 table 進行無條件自循環直到 put 成功,可以分成以下六步流程來概述。
- 如果沒有初始化就先調用 initTable()方法來進行初始化過程
- 如果沒有 hash 沖突就直接 CAS 插入
- 如果還在進行擴容操作就先進行擴容
- 如果存在 hash 沖突,就加鎖來保證線程安全,這里有兩種情況,一種是鏈表形式就直接遍歷到尾端插入,一種是紅黑樹就按照紅黑樹結構插入,
- 最后一個如果該鏈表的數量大于閾值 8,就要先轉換成黑紅樹的結構,break 再一次進入循環
- 如果添加成功就調用 addCount()方法統計 size,并且檢查是否需要擴容
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) thrownew NullPointerException();
int hash = spread(key.hashCode()); //兩次hash,減少hash沖突,可以均勻分布
int binCount = 0;
for (Node<K,V>[] tab = table;;) { //對這個table進行迭代
Node<K,V> f; int n, i, fh;
//這里就是上面構造方法沒有進行初始化,在這里進行判斷,為null就調用initTable進行初始化,屬于懶漢模式初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
elseif ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果i位置沒有數據,就直接無鎖插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
elseif ((fh = f.hash) == MOVED)//如果在進行擴容,則先進行擴容操作
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//如果以上條件都不滿足,那就要進行加鎖操作,也就是存在hash沖突,鎖住鏈表或者紅黑樹的頭結點
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { //表示該節點是鏈表結構
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//這里涉及到相同的key進行put就會覆蓋原先的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //插入鏈表尾部
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
elseif (f instanceof TreeBin) {//紅黑樹結構
Node<K,V> p;
binCount = 2;
//紅黑樹結構旋轉插入
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) { //如果鏈表的長度大于8時就會進行紅黑樹的轉換
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//統計size,并且檢查是否需要擴容
returnnull;
}流程圖如下所示:
 圖片
圖片
get 操作
get 方法可能看代碼不是很長,但是他卻能 保證無鎖狀態下的內存一致性 。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); // 計算 hash
if ((tab = table) != null && (n = tab.length) > 0 && // 確保 table 已經初始化
// 確保對應的哈希桶不為空,注意這里是 Volatile 語義獲取;因為擴容的時候,是完全拷貝,所以只要不為空,則鏈表必然完整
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash < 0,則必然在擴容,原來位置的節點可能全部移動到 i + oldCap 位置,所以利用多態到 nextTable 中查找
elseif (eh < 0) return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) { // 遍歷鏈表
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
returnnull;
}ConcurrentHashMap 的 get 操作的流程很簡單,也很清晰,可以分為三個步驟來描述.
- 計算 hash 值,定位到該 table 索引位置,如果是首節點符合就返回
- 如果遇到擴容的時候,會調用標志正在擴容節點 ForwardingNode 的 find 方法,查找該節點,匹配就返回
- 以上都不符合的話,就往下遍歷節點,匹配就返回,否則最后就返回 null
size 操作
在 JDK1.8 版本中,對于 size 的計算,在擴容和 addCount()方法就已經有處理了,JDK1.7 是在調用 size()方法才去計算,其實在并發集合中去計算 size 是沒有多大的意義的,因為 size 是實時在變的,只能計算某一刻的大小,但是某一刻太快了,人的感知是一個時間段,所以并不是很精確。
擴容
擴容操作一直都是比較慢的操作,而 CHM 中巧妙的利用任務劃分,使得多個線程可能同時參與擴容;
另外擴容條件也有兩個:
- 有鏈表長度超過 8,但是容量小于 64 的時候,發生擴容;
- 節點數超過閾值的時候,發生擴容;
其擴容的過程可描述為:
- 首先擴容過程的中,節點首先移動到過度表 nextTable ,所有節點移動完畢時替換散列表 table;
- 移動時先將散列表定長等分,然后逆序依次領取任務擴容,設置 sizeCtl 標記正在擴容;
- 移動完成一個哈希桶或者遇到空桶時,將其標記為 ForwardingNode 節點,并指向 nextTable ;
- 后有其他線程在操作哈希表時,遇到 ForwardingNode 節點,則先幫助擴容(繼續領取分段任務),擴容完成后再繼續之前的操作;
如圖:
 圖片
圖片
具體源碼如下:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // 根據 CPU 數量計算任務步長
if (nextTab == null) { // 初始化 nextTab
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // 擴容一倍
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE; // 發生 OOM 時,不再擴容
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); // 標記空桶,或已經轉移完畢的桶
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) { // 逆向遍歷擴容
Node<K,V> f; int fh;
while (advance) { // 向前獲取哈希桶
int nextIndex, nextBound;
if (--i >= bound || finishing) // 已經取到哈希桶,或已完成時退出
advance = false;
elseif ((nextIndex = transferIndex) <= 0) { // 遍歷到達頭節點,已經沒有待遷移的桶,線程準備退出
i = -1;
advance = false;
}
elseif (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { // 當前任務完成,領取下一批哈希桶
bound = nextBound;
i = nextIndex - 1; // 索引指向下一批哈希桶
advance = false;
}
}
// i < 0 :表示擴容結束,已經沒有待移動的哈希桶
// i >= n :擴容結束,再次檢查確認
// i + n >= nextn : 在使用 nextTable 替換 table 時,有線程進入擴容就會出現
if (i < 0 || i >= n || i + n >= nextn) { // 完成擴容準備退出
int sc;
if (finishing) { // 兩次檢查,只有最后一個擴容線程退出時,才更新變量
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1); // 0.75*2*n
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // 擴容線程減一
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; // 不是最后一個線程,直接退出
finishing = advance = true; // 最后一個線程,再次檢查
i = n; // recheck before commit
}
}
elseif ((f = tabAt(tab, i)) == null) // 當前節點為空,直接標記為 ForwardingNode,然后繼續獲取下一個桶
advance = casTabAt(tab, i, null, fwd);
// 之前的線程已經完成該桶的移動,直接跳過,正常情況下自己的任務區間,不會出現 ForwardingNode 節點,
elseif ((fh = f.hash) == MOVED) // 此處為極端條件下的健壯性檢查
advance = true; // already processed
// 開始處理鏈表
else {
// 注意在 get 的時候,可以無鎖獲取,是因為擴容是全拷貝節點,完成后最后在更新哈希桶
// 而在 put 的時候,是直接將節點加入尾部,獲取修改其中的值,此時如果允許 put 操作,最后就會發生臟讀,
// 所以 put 和 transfer,需要競爭同一把鎖,也就是對應的哈希桶,以保證內存一致性效果
synchronized (f) {
if (tabAt(tab, i) == f) { // 確認鎖定的是同一個桶
Node<K,V> ln, hn;
if (fh >= 0) { // 正常節點
int runBit = fh & n; // hash & n,判斷擴容后的索引
Node<K,V> lastRun = f;
// 此處找到鏈表最后擴容后處于同一位置的連續節點,這樣最后一節就不用再一次復制了
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
// 依次將鏈表拆分成,lo、hi 兩條鏈表,即位置不變的鏈表,和位置 + oldCap 的鏈表
// 注意最后一節鏈表沒有new,而是直接使用原來的節點
// 同時鏈表的順序也被打亂了,lastRun 到最后為正序,前面一節為逆序
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln); // 插入 lo 鏈表
setTabAt(nextTab, i + n, hn); // 插入 hi 鏈表
setTabAt(tab, i, fwd); // 哈希桶移動完成,標記為 ForwardingNode 節點
advance = true; // 繼續獲取下一個桶
}
elseif (f instanceof TreeBin) { // 拆分紅黑樹
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null; // 為避免最后在反向遍歷,先留頭結點的引用,
TreeNode<K,V> hi = null, hiTail = null; // 因為順序的鏈表,可以加速紅黑樹構造
int lc = 0, hc = 0; // 同樣記錄 lo,hi 鏈表的長度
for (Node<K,V> e = t.first; e != null; e = e.next) { // 中序遍歷紅黑樹
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null); // 構造紅黑樹節點
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 判斷是否需要將其轉化為紅黑樹,同時如果只有一條鏈,那么就可以不用在構造
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}ConcurrentLinkedQueue 的使用和原理
ConcurerntLinkedQueue 一個基于單向鏈表的無界線程安全隊列,支持高并發的隊列操作,無需顯式的鎖,而且容量沒有上限。
此隊列按照 FIFO(先進先出)原則對元素進行排序。新的元素插入到隊列的尾部,隊列獲取操作從隊列頭部獲得元素。
應用場景
常見的使用場景可能包括任務調度、事件處理、日志記錄等。比如訂單處理系統,其中多個生產者生成訂單,多個消費者處理訂單。
// 訂單事件處理器(生產環境級實現)
publicclass OrderEventProcessor {
// 使用隊列作為訂單緩沖區(無容量限制)
privatefinal ConcurrentLinkedQueue<OrderEvent> queue = new ConcurrentLinkedQueue<>();
privatefinal ExecutorService workers = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors() * 2,
new NamedThreadFactory("order-processor")
);
// 初始化處理線程
public void start() {
for (int i = 0; i < workers.getCorePoolSize(); i++) {
workers.submit(this::processEvents);
}
}
// 接收訂單事件(來自網絡IO線程)
public void receiveEvent(OrderEvent event) {
queue.offer(event); // 無阻塞插入
metrics.recordEnqueue(); // 監控埋點
}
// 事件處理核心邏輯
private void processEvents() {
while (!Thread.currentThread().isInterrupted()) {
OrderEvent event = queue.poll(); // 無阻塞獲取
if (event != null) {
try {
handleEvent(event);
} catch (Exception ex) {
handleFailure(event, ex); // 異常處理
}
} else {
// 隊列空時自適應休眠(避免CPU空轉)
sleepBackoff();
}
}
}
// 指數退避休眠(動態調節CPU使用率)
private void sleepBackoff() {
long delay = 1; // 初始1ms
while (queue.isEmpty() && delay < 100) {
try {
TimeUnit.MILLISECONDS.sleep(delay);
delay <<= 1; // 指數增加等待時間
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 優雅關閉
public void shutdown() {
workers.shutdown();
while (!queue.isEmpty()) {
// 等待剩余任務處理完成
Uninterruptibles.sleepUninterruptibly(100, TimeUnit.MILLISECONDS);
}
}
}需要注意的是,以下場景不適合。
- 阻塞需求,需要 take()阻塞等待。
- 有界隊列。
- 強一致性,要求精確的 size。
實現原理
以 JDK 17 源碼為基線,ConcurrentLinkedQueue 是 Java 并發包中基于無鎖算法實現的線程安全隊列,專為高并發場景設計。其核心設計目標包括:
- 無阻塞操作:通過 CAS 實現非阻塞算法
- 線性擴展能力:性能隨 CPU 核心數增加而提升
- 弱一致性:迭代器與 size() 方法返回近似值
- 內存效率:每個元素僅需 24 字節存儲開銷
ConcurrentLinkedQueue 的結構
ConcurrentLinkedQueue 由 head 節點和 tail 節點組成,每個節點(Node)由節點元素(item)和指向下一個節點的引用(next)組成,節點與節點之間就是通過這個 next 關聯起來,從而組成一張鏈表結構的隊列。
ConcurrentLinkedQueue 的節點都是 Node 類型的。
static finalclass Node<E> {
volatile E item;
volatile Node<E> next;
Node(E item) {
ITEM.set(this, item);
}
Node() {}
void appendRelaxed(Node<E> next) {
NEXT.set(this, next);
}
boolean casItem(E cmp, E val) {
return ITEM.compareAndSet(this, cmp, val);
}
}入隊操作(offer)
流程圖如下。
 圖片
圖片
代碼解析。
public boolean offer(E e) {
final Node<E> newNode = new Node<E>(Objects.requireNonNull(e));
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// CAS插入新節點
if (NEXT.compareAndSet(p, null, newNode)) {
// 惰性更新tail(允許失敗)
if (p != t)
TAIL.weakCompareAndSet(this, t, newNode);
returntrue;
}
}
elseif (p == q) // 處理已移除節點
p = (t != (t = tail)) ? t : head;
else// 推進指針
p = (p != t && t != (t = tail)) ? t : q;
}
}優化點:
- weakCompareAndSet 減少內存屏障開銷
- 允許尾指針最多滯后 log(n) 個節點
- 通過 VarHandle 實現精確內存排序
出隊操作(poll)
核心機制:
- 兩階段出隊:先標記 item 為 null,再更新 head
- 頭指針可能跳躍多個已消費節點
- 自動清理無效節點
流程圖如下。
 圖片
圖片
核心源碼。
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item;
if ((item = p.item) != null && p.casItem(item, null)) {
// 成功獲取數據
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
elseif ((q = p.next) == null) {
updateHead(h, p);
returnnull;
}
elseif (p == q)
// 繼續循環
continue restartFromHead;
}
}
}Java 7 種阻塞隊列
Chaya:“什么是阻塞隊列?”
阻塞隊列,顧名思義,首先它是一個隊列,線程 1 往阻塞隊列中添加元素,而線程 2 從阻塞隊列中移除元素。
- 當阻塞隊列是空時,從隊列中獲取元素的操作將會被阻塞。
- 當阻塞隊列是滿時,從隊列中添加元素的操作將會被阻塞。
JDK1.8 中的阻塞隊列實現共有 7 個,分別是:
- ArrayBlockingQueue:基于數組的有界隊列;
- LinkedBlockingQueue:基于鏈表的無界隊列(可以設置容量);
- PriorityBlockingQueue:基于二叉堆的無界優先級隊列;
- DelayQueue:基于 PriorityBlockingQueue 的無界延遲隊列;
- SynchronousQueue:無容量的阻塞隊列(Executors.newCachedThreadPool() 中使用的隊列);
- LinkedTransferQueue:基于鏈表的無界隊列;
- LinkedBlockingDeque:一個由鏈表結構組成的雙向阻塞隊列。
阻塞隊列核心接口
阻塞隊列統一實現了BlockingQueue接口,BlockingQueue接口在java.util包Queue接口的基礎上提供了put(e)以及take()兩個阻塞方法。
除了阻塞功能,BlockingQueue 接口還定義了定時的offer以及poll,以及一次性移除方法drainTo。
//插入元素,隊列滿后會拋出異常
boolean add(E e);
//移除元素,隊列為空時會拋出異常
E remove();
//插入元素,成功反會true
boolean offer(E e);
//移除元素
E poll();
//插入元素,隊列滿后會阻塞
void put(E e) throws InterruptedException;
//移除元素,隊列空后會阻塞
E take() throws InterruptedException;
//限時插入
boolean offer(E e, long timeout, TimeUnit unit)
//限時移除
E poll(long timeout, TimeUnit unit);
//獲取所有元素到Collection中
int drainTo(Collection<? super E> c);阻塞隊列 6 大使用場景
Java 阻塞隊列(BlockingQueue)是并發編程中的核心工具,其線程安全和阻塞特性使其在以下場景中發揮重要作用。
生產者-消費者模型(經典場景)
電商系統中,用戶下單后需異步處理庫存扣減、支付回調、物流通知等操作。
痛點:生產(下單)與消費(處理)速度不一致,需解耦并保證高吞吐。
public class OrderProcessor {
// 生產級配置:建議隊列大小為 CPU 核心數*2~4
privatestaticfinal BlockingQueue<Order> queue = new LinkedBlockingQueue<>(2048);
privatestaticfinal ExecutorService consumerPool = Executors.newFixedThreadPool(8);
// 生產者(Web 服務線程)
public void submitOrder(Order order) {
if (!queue.offer(order)) { // 隊列滿時快速失敗
log.warn("Order queue overflow! Reject order: {}", order.getId());
thrownew ServiceException("系統繁忙,請稍后重試");
}
log.info("Order submitted: {}", order.getId());
}
// 消費者(后臺線程池)
@PostConstruct
public void initConsumers() {
for (int i = 0; i < 8; i++) {
consumerPool.execute(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
Order order = queue.take(); // 阻塞直到有訂單
processOrder(order);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
}
}
private void processOrder(Order order) {
// 扣減庫存、支付回調等業務邏輯
}
}線程池任務調度
場景問題
視頻平臺需將上傳的視頻轉碼為不同分辨率,任務具有突發性。
public class VideoTranscoder {
// 使用 PriorityBlockingQueue 確保 VIP 用戶優先處理
privatestaticfinal BlockingQueue<TranscodeTask> queue =
new PriorityBlockingQueue<>(1000, Comparator.comparing(TranscodeTask::getPriority));
// 自定義線程池(核心線程數=CPU數, 最大線程數=CPU數*2)
privatestaticfinal ThreadPoolExecutor executor = new ThreadPoolExecutor(
4, 8, 30, TimeUnit.SECONDS, queue
);
public void submitTranscodeTask(TranscodeTask task) {
executor.execute(() -> {
// 執行實際轉碼操作
process(task);
});
}
// 監控隊列狀態(生產環境建議接入 Prometheus)
public MonitorData getQueueStatus() {
returnnew MonitorData(
queue.size(),
executor.getActiveCount(),
queue.remainingCapacity()
);
}
}生產級要點:
- 使用有界隊列避免 OOM
- RejectedExecutionHandler 需配置合理拒絕策略
- 隊列監控接入告警系統
流量削峰
瞬時流量高峰可達平時 100 倍,數據庫無法承受直接壓力。
public class SeckillService {
// 隊列容量=商品庫存*2(內存可控)
privatefinal BlockingQueue<SeckillRequest> queue =
new ArrayBlockingQueue<>(20000);
// 異步消費隊列
@Scheduled(fixedRate = 100)
public void processQueue() {
List<SeckillRequest> batch = new ArrayList<>(100);
queue.drainTo(batch, 100); // 批量取100條
if (!batch.isEmpty()) {
seckillDao.batchProcess(batch); // 批量寫入數據庫
}
}
public boolean trySeckill(SeckillRequest request) {
return queue.offer(request); // 非阻塞提交
}
} 圖片
圖片
生產級設計:
- 隊列容量與數據庫吞吐量匹配
- 批量處理減少數據庫壓力
- 前端配合顯示排隊狀態
延遲任務調度:訂單超時關閉
需在訂單創建 30 分鐘后檢查支付狀態,未支付自動關閉。
public class OrderTimeoutChecker implements Runnable {
privatefinal DelayQueue<DelayedOrder> queue = new DelayQueue<>();
public void addOrder(Order order) {
queue.put(new DelayedOrder(order, 30, TimeUnit.MINUTES));
}
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
DelayedOrder order = queue.take(); // 阻塞直到有到期訂單
checkPayment(order.getOrderId());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
privatestaticclass DelayedOrder implements Delayed {
privatefinal Order order;
privatefinallong expireTime;
// 實現 getDelay() 和 compareTo()
}
}生產級注意:
- 分布式場景需用 Redis/ZooKeeper 替代
- 集群環境下需防重復處理
- 添加 JVM 關閉鉤子確保任務不丟失
異步日志系統
需要記錄詳細業務日志但磁盤 I/O 不能影響主線程性能。
public class AsyncLogger {
privatestaticfinal BlockingQueue<LogEvent> queue =
new LinkedTransferQueue<>(); // 高吞吐無界隊列
static {
// 守護線程消費日志
Thread loggerThread = new Thread(() -> {
while (true) {
try {
LogEvent event = queue.take();
writeToDisk(event);
} catch (InterruptedException e) {
// 優雅關閉處理
drainRemainingLogs();
break;
}
}
});
loggerThread.setDaemon(true);
loggerThread.start();
}
public static void log(LogEvent event) {
if (!queue.offer(event)) { // 防御性設計
fallbackLog(event);
}
}
}線程池隊列
- 線程池中活躍線程數達到 corePoolSize 時,線程池將會將后續的 task 提交到 BlockingQueue 中;
- 線程池的核心方法 ThreadPoolExecutor,用 BlockingQueue 存放任務的阻塞隊列,被提交但尚未被執行的任務。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)線程池在內部實際也是構建了一個生產者消費者模型,將線程和任務兩者解耦,并不直接關聯,從而良好的緩沖任務,復用線程。
 圖片
圖片
不同的線程池實現用的是不同的阻塞隊列,newFixedThreadPool 和 newSingleThreadExecutor 用的是 LinkedBlockingQueue,newCachedThreadPool 用的是 SynchronousQueue。
各類隊列對比和選型
 圖片
圖片
生產選型建議:
- 網絡請求緩沖 → ArrayBlockingQueue(可控內存)
- 任務調度 → PriorityBlockingQueue(優先級控制)
- 線程間直接通信 → SynchronousQueue
- 磁盤 I/O 解耦 → LinkedBlockingQueue(吞吐優先)
性能優化要點
隊列監控:
// 通過 JMX 暴露指標
public class QueueMonitor implements QueueMonitorMXBean {
private final BlockingQueue<?> queue;
public int getQueueSize() {
return queue.size();
}
// 注冊到 MBeanServer...
}拒絕策略(以線程池為例):
new ThreadPoolExecutor.CallerRunsPolicy() { // 生產推薦策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
log.warn("Task rejected, running in caller thread");
if (!e.isShutdown()) {
r.run();
}
}
}動態擴縮容:
// 根據監控指標調整隊列容量
public void adjustQueueCapacity(int newSize) {
if (queue instanceof ResizableBlockingQueue) {
((ResizableBlockingQueue) queue).setCapacity(newSize);
}
}掌握了各種阻塞隊列的使用場景,接下來我們深入拆解每個阻塞隊列的實現原理。
ArrayBlockingQueue
ArrayBlockingQueue是一個底層用數組實現的有界阻塞隊列,有界是指他的容量大小是固定的,不能擴充容量,在初始化時就必須確定隊列大小。
它通過可重入的獨占鎖ReentrantLock來控制并發,Condition來實現阻塞和通知喚醒。
結構概述
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
final Object[] items; // 容器數組
int takeIndex; // 出隊索引
int putIndex; // 入隊索引
int count; // 排隊個數
final ReentrantLock lock; // 全局鎖
private final Condition notEmpty; // 出隊條件隊列
private final Condition notFull; // 入隊條件隊列
...
}ArrayBlockingQueue 的結構如圖所示:
 圖片
圖片
- ArrayBlockingQueue 的數組其實是一個邏輯上的環狀結構,在添加、取出數據的時候,并沒有像 ArrayList 一樣發生數組元素的移動(當然除了 removeAt(final int removeIndex));
- 并且由 takeIndex 和 putIndex 指示讀寫位置;
- 在讀寫的時候還有兩個讀寫條件隊列。
阻塞入隊
阻塞入隊 put 方法:
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
//獲取獨占鎖
lock.lockInterruptibly();
try {
//如果隊列已滿則通過await阻塞put方法
while (count == items.length)
notFull.await();
//滿足條件,插入元素,并喚醒因notEmpty等待的消費線程
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
//插入元素后將putIndex+1,當隊列使用完后重置為0
if (++putIndex == items.length)
putIndex = 0;
count++;
//隊列添加元素后喚醒因notEmpty等待的消費線程
notEmpty.signal();
}阻塞出隊
//移除隊列中的元素
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//獲取獨占鎖
lock.lockInterruptibly();
try {
//如果隊列已空則通過await阻塞take方法
while (count == 0)
notEmpty.await();
return dequeue(); //移除元素
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
//移除元素后將takeIndex+1,當隊列使用完后重置為0
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
//隊列消費元素后喚醒因notFull等待的消費線程
notFull.signal();
return x;
}隊列滿后通過notFull.await()來阻塞生產者線程,消費元素后通過 notFull.signal()來喚醒阻塞的生產者線程。
隊列為空后通過notEmpty.await()來阻塞消費者線程,生產元素后通過notEmpty.signal()喚醒阻塞的消費者線程。
drainTo
drainTo方法可以一次性獲取隊列中所有的元素,它減少了鎖定隊列的次數,使用得當在某些場景下對性能有不錯的提升。
public int drainTo(Collection<? super E> c, int maxElements) {
checkNotNull(c);
if (c == this)
thrownew IllegalArgumentException();
if (maxElements <= 0)
return0;
final Object[] items = this.items;
final ReentrantLock lock = this.lock; //僅獲取一次鎖
lock.lock();
try {
int n = Math.min(maxElements, count); //獲取隊列中所有元素
int take = takeIndex;
int i = 0;
try {
while (i < n) {
@SuppressWarnings("unchecked")
E x = (E) items[take];
c.add(x); //循環插入元素
items[take] = null;
if (++take == items.length)
take = 0;
i++;
}
return n;
} finally {
// Restore invariants even if c.add() threw
if (i > 0) {
count -= i;
takeIndex = take;
if (itrs != null) {
if (count == 0)
itrs.queueIsEmpty();
elseif (i > take)
itrs.takeIndexWrapped();
}
for (; i > 0 && lock.hasWaiters(notFull); i--)
notFull.signal(); //喚醒等待的生產者線程
}
}
} finally {
lock.unlock();
}
}LinkedBlockingQueue
LinkedBlockingQueue是一個底層用單向鏈表實現的有界阻塞隊列,和ArrayBlockingQueue一樣,采用ReentrantLock來控制并發,不同的是它使用了兩個獨占鎖來控制消費和生產。
如果不是特殊業務,LinkedBlockingQueue 使用時,切記要定義容量 new LinkedBlockingQueue(capacity),防止過度膨脹。
結構概述
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// 默認 Integer.MAX_VALUE
privatefinalint capacity;
// 容量
privatefinal AtomicInteger count = new AtomicInteger();
// 頭結點 head.item == null
transient Node<E> head;
// 尾節點 last.next == null
privatetransient Node<E> last;
// take鎖,出隊鎖,只有take,poll方法會持有
privatefinal ReentrantLock takeLock = new ReentrantLock();
// 出隊等待條件
// 當隊列無元素時,take鎖會阻塞在notEmpty條件上,等待其它線程喚醒
privatefinal Condition notEmpty = takeLock.newCondition();
// 入隊鎖,只有put,offer會持有
privatefinal ReentrantLock putLock = new ReentrantLock();
// 入隊等待條件
// 當隊列滿了時,put鎖會會阻塞在notFull上,等待其它線程喚醒
privatefinal Condition notFull = putLock.newCondition();
// 基于鏈表實現,肯定要有結點類,典型的單鏈表結構
staticclass Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
}LinkedBlockingQueue 的結構如圖所示:
 圖片
圖片
如圖所示,
- LinkedBlockingQueue 其實就是一個簡單的單向鏈表,其中頭部元素的數據為空,尾部元素的 next 為空;
- 因為讀寫都有競爭,所以在頭部和尾部分別有一把鎖;同時還有對應的兩個條件隊列;
put 和 take 方法
public void put(E e) throws InterruptedException {
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
//因為使用了雙鎖,需要使用AtomicInteger計算元素總量,避免并發計算不準確
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
//隊列已滿,阻塞生產線程
notFull.await();
}
//插入元素到隊列尾部
enqueue(node);
//count + 1
c = count.getAndIncrement();
//如果+1后隊列還未滿,通過其他生產線程繼續生產
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
//只有當之前是空時,消費隊列才會阻塞,否則是不需要通知的
if (c == 0)
signalNotEmpty();
}
private void enqueue(Node<E> node) {
//將新元素添加到鏈表末尾,然后將last指向尾部元素
last = last.next = node;
}
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
//隊列為空,阻塞消費線程
notEmpty.await();
}
//消費一個元素
x = dequeue();
//count - 1
c = count.getAndDecrement();
// 通知其他等待的消費線程繼續消費
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
//只有當前隊列是滿的,生產隊列才會阻塞,否則是不需要通知的
signalNotFull();
return x;
}
//消費隊列頭部的下一個元素,同時將新頭部置空
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}可以看到LinkedBlockingQueue通過takeLock和putLock兩個鎖來控制生產和消費,互不干擾,只要隊列未滿,生產線程可以一直生產,只要隊列不為空,消費線程可以一直消費,不會相互因為獨占鎖而阻塞。
Chaya:“為什么 ArrayBlockingQueue 中不使用雙鎖來實現隊列的生產和消費呢?”
我的理解是 ArrayBlockingQueue 也能使用雙鎖來實現功能,但由于它底層使用了數組這種簡單結構,相當于一個共享變量,如果通過兩個鎖,需要更加精確的鎖控制。
LinkedBlockingQueue不存在這個問題,鏈表這種數據結構頭尾節點都相對獨立,存儲上也不連續,雙鎖控制不存在復雜性。
PriorityBlockingQueue
PriorityBlockingQueue是一個底層由數組實現的無界隊列,并帶有排序功能,同樣采用ReentrantLock來控制并發。
由于是無界的,所以插入元素時不會阻塞,沒有隊列滿的狀態,只有隊列為空的狀態。
PriorityBlockingQueue 具有以下特性:
- 基于優先級排序:元素按自然順序(Comparable)或自定義 Comparator 排序。
- 線程安全:通過 ReentrantLock 保證并發操作的安全性。
- 動態擴容:底層是數組實現的二叉堆,容量不足時自動擴容。
- 阻塞操作:take() 在隊列為空時阻塞;put() 不會阻塞(因為隊列無界)。
適用場景
例子中,創建了一個優先級阻塞隊列,用于存儲和檢索PriorityTask對象,這些對象根據它們的優先級進行排序,client 代碼會向隊列中添加任務,并從隊列中檢索并處理優先級最高的任務。
// 定義一個具有優先級的任務類
class PriorityTask implements Comparable<PriorityTask>{
privateint priority;
private String name;
public PriorityTask(int priority, String name) {
this.priority = priority;
this.name = name;
}
@Override
public int compareTo(PriorityTask o) {
if (this.priority < o.priority) {
return -1;
} elseif (this.priority > o.priority) {
return1;
} else {
return0;
}
}
@Override
public String toString() {
return"PriorityTask{" +
"priority=" + priority +
", name='" + name + '\'' +
'}';
}
}
publicclass PriorityBlockingQueueExample {
public static void main(String[] args) throws InterruptedException {
// 創建一個優先級阻塞隊列,使用PriorityTask類的自然順序進行排序
PriorityBlockingQueue<PriorityTask> queue = new PriorityBlockingQueue<>();
// 添加任務到隊列
queue.put(new PriorityTask(3, "Task 3"));
queue.put(new PriorityTask(1, "Task 1"));
queue.put(new PriorityTask(2, "Task 2"));
// 從隊列中取出并打印任務,優先級高的先出隊
while (!queue.isEmpty()) {
PriorityTask task = queue.take();
System.out.println("Processing: " + task);
}
}
}在這個示例中,定義了一個名為 PriorityTask 的類,它實現了 Comparable 接口,并且重寫了 compareTo 方法來定義優先級規則。
隊列中的元素將根據這個規則自動排序,從而保證優先級高的任務先被處理。
實現原理
PriorityBlockingQueue 內部通過 數組 維護一個 最小二叉堆(默認),堆頂元素始終是優先級最高的(最小元素)。 數組下標關系:
- 父節點:parent = (childIndex - 1) / 2
- 左子節點:leftChild = parent * 2 + 1
- 右子節點:rightChild = parent * 2 + 2
關鍵字段
// 存儲元素的數組
privatetransient Object[] queue;
// 元素數量
privatetransientint size;
// 排序規則(為 null 時使用自然排序)
privatetransient Comparator<? super E> comparator;
// 保證線程安全的鎖
privatefinal ReentrantLock lock = new ReentrantLock();
// 非空條件變量(用于 take() 阻塞)
privatefinal Condition notEmpty = lock.newCondition();入隊源碼
public boolean offer(E e) {
if (e == null)
thrownew NullPointerException();
// 首先獲取鎖對象。
final ReentrantLock lock = this.lock;
// 只有一個線程操作入隊和出隊動作。
lock.lock();
// n代表數組的實際存儲內容的大小
// cap代表隊列的整體大小,也就是數組的長度。
int n, cap;
Object[] array;
// 如果數組實際長度大于等于數組的長度時,需要進行擴容操作。
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
// 如果用戶指定比較器,則使用用戶指定的比較器來進行比較,如果沒有則使用默認比較器。
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 進行上浮操作。
siftUpComparable(n, e, array);
else
// 進行上浮操作。
siftUpUsingComparator(n, e, array, cmp);
// 實際長度增加1,由于有且僅有一個線程操作隊列,所以這里并沒有使用原子性操作。
size = n + 1;
// 通知等待的線程,隊列已經有數據,可以獲取數據。
notEmpty.signal();
} finally {
// 解鎖操作。
lock.unlock();
}
// 返回操作成功。
returntrue;
}關鍵步驟
- 加鎖:確保線程安全。
- 擴容檢查:若數組已滿,調用 tryGrow() 擴容(通常擴容 50%)。
- 堆上浮:將新元素插入數組末尾,逐步與父節點比較并交換,直到滿足堆性質。
- 喚醒消費者:通知可能阻塞的 take() 線程。
出隊
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
private E dequeue() {
// 數組的元素的個數。
int n = size - 1;
// 如果數組中不存在元素則直接返回null。
if (n < 0)
returnnull;
else {
// 獲取隊列數組。
Object[] array = queue;
// 將第一個元素也就是二叉堆的根結點堆頂元素作為返回結果。
E result = (E) array[0];
// 獲取數組中最后一個元素。
E x = (E) array[n];
// 將最后一個元素設置為null。
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 進行下沉操作。
siftDownComparable(0, x, array, n);
else
// 進行下沉操作。
siftDownUsingComparator(0, x, array, n, cmp);
// 實際元素大小減少1.
size = n;
// 返回結果。
return result;
}
}關鍵步驟
- 加鎖:確保線程安全。
- 取出堆頂:返回堆頂元素(優先級最高)。
- 堆下沉:將末尾元素移到堆頂,逐步與子節點比較并交換,直到滿足堆性質。
DelayQueue
DelayQueue 也是一個無界隊列,它是在PriorityQueue基礎上實現的,先按延遲優先級排序,延遲時間短的排在前面。
和PriorityBlockingQueue相似,底層也是數組,采用一個ReentrantLock來控制并發。
由于是無界的,所以插入元素時不會阻塞,沒有隊列滿的狀態。
private finaltransient ReentrantLock lock = new ReentrantLock();
privatefinal PriorityQueue<E> q = new PriorityQueue<E>();//優先級隊列
public void put(E e) {
offer(e);
}
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e); //插入元素到優先級隊列
if (q.peek() == e) { //如果插入的元素在隊列頭部
leader = null;
available.signal(); //通知消費線程
}
returntrue;
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek(); //獲取頭部元素
if (first == null)
available.await(); //空隊列阻塞
else {
long delay = first.getDelay(NANOSECONDS); //檢查元素是否延遲到期
if (delay <= 0)
return q.poll(); //到期則彈出元素
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay); //阻塞未到期的時間
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}SynchronousQueue
SynchronousQueue相比較之前的 4 個隊列就比較特殊了,它是一個沒有容量的隊列,也就是說它內部時不會對數據進行存儲,每進行一次 put 之后必須要進行一次 take,否則相同線程繼續 put 會阻塞。
這種特性很適合做一些傳遞性的工作,一個線程生產,一個線程消費。
這里只對它的非公平實現下的 take 和 put 方法做下簡單分析:
//非公平情況下調用內部類TransferStack的transfer方法put
public void put(E e) throws InterruptedException {
if (e == null) thrownew NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
thrownew InterruptedException();
}
}
//非公平情況下調用內部類TransferStack的transfer方法take
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
thrownew InterruptedException();
}
//具體的put以及take方法,只有E的區別,通過E來區別REQUEST還是DATA模式
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
//棧無元素或者元素和插入的元素模式相匹配,也就是說都是插入元素
if (h == null || h.mode == mode) {
//有時間限制并且超時
if (timed && nanos <= 0) {
if (h != null && h.isCancelled())
casHead(h, h.next); // 重新設置頭節點
else
returnnull;
}
//未超時cas操作嘗試設置頭節點
elseif (casHead(h, s = snode(s, e, h, mode))) {
//自旋一段時間后未消費元素則掛起put線程
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
returnnull;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
//棧不為空并且和頭節點模式不匹配,存在元素則消費元素并重新設置head節點
elseif (!isFulfilling(h.mode)) { // try to fulfill
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
elseif (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
SNode m = s.next; // m is s's match
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // help unlink
}
}
}
//節點正在匹配階段
else { // help a fulfiller
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
}
}
//先自旋后掛起的核心方法
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
finallong deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
//計算自旋的次數
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
//匹配成功過返回節點
if (m != null)
return m;
//超時控制
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
//自旋檢查,是否進行下一次自旋
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
elseif (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
elseif (!timed)
LockSupport.park(this); //在這里掛起線程
elseif (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}代碼非常復雜,這里說下我所理解的核心邏輯。
代碼中可以看到put以及take方法都是通過調用transfer方法來實現的,然后通過參數mode來區別,在生產元素時如果是同一個線程多次put則會采取自旋的方式多次嘗試put元素,可能自旋過程中元素會被消費,這樣可以及時put,降低線程掛起的性能損耗,高吞吐量的核心也在這里。
消費線程一樣,空棧時也會先自旋,自旋失敗然后通過線程的LockSupport.park方法掛起。
LinkedTransferQueue
LinkedTransferQueue 是一個由鏈表結構組成的無界阻塞 TransferQueue 隊列。
LinkedTransferQueue采用一種預占模式。意思就是消費者線程取元素時,如果隊列不為空,則直接取走數據,若隊列為空,那就生成一個節點(節點元素為 null)入隊,然后消費者線程被等待在這個節點上,后面生產者線程入隊時發現有一個元素為 null 的節點,生產者線程就不入隊了,直接就將元素填充到該節點,并喚醒該節點等待的線程,被喚醒的消費者線程取走元素,從調用的方法返回。我們稱這種節點操作為“匹配”方式。
隊列實現了 TransferQueue 接口重寫了 tryTransfer 和transfer方法,這組方法和SynchronousQueue` 公平模式的隊列類似,具有匹配的功能.。
LinkedBlockingDeque
LinkedBlockingDeque 是一個由鏈表結構組成的雙向阻塞隊列。
所謂雙向隊列指的你可以從隊列的兩端插入和移出元素。雙端隊列因為多了一個操作隊列的入口,在多線程同時入隊時,也就減少了一半的競爭。
相比其他的阻塞隊列,LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast 等方法,以 First 單詞結尾的方法,表示插入,獲取(peek)或移除雙端隊列的第一個元素。
以 Last 單詞結尾的方法,表示插入,獲取或移除雙端隊列的最后一個元素。
另外插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。
在初始化 LinkedBlockingDeque 時可以設置容量防止其過渡膨脹,默認容量也是 Integer.MAX_VALUE。
另外雙向阻塞隊列可以運用在“工作竊取”模式中。