分布式ID生成的常見方案~都在這里啦!
前言
大家好,我是田螺。
我們日常開發中,經常需要使用到分布式ID。我們系統一般都是分布式部署的,一些分布式鎖、冪等、數據庫的唯一鍵,都需要分布式ID。
今天田螺哥盤點一些常見的分布式唯一ID生成方案。
1. 數據庫自增ID
原理:利用數據庫自增字段(如MySQL的AUTO_INCREMENT)生成唯一ID
 圖片
圖片
優點:簡單易用、ID有序、索引效率高缺點:單點故障、擴展性差(分庫分表困難)
適用場景:單機或簡單主從架構系統
代碼示例:
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
order_data VARCHAR(255)
);2. UUID
- 原理:基于MAC地址、時間戳、隨機數生成128位字符串
- 優點:全局唯一、無需中心化服務
- 缺點:無序導致索引效率低、存儲空間大(36字符)
- 適用場景:日志跟蹤、非核心業務(如臨時會話)
我們的項目中,有些伙伴為了簡單方便,有時候會直接用它,如果業務性比較強的,就在它后綴拼接寫個性化標記(業務標記)進來~
代碼示例:
import java.util.UUID;
String uuid = UUID.randomUUID().toString();3. 雪花算法(Snowflake)
- 原理:64位結構 = 時間戳(41位) + 機器ID(10位) + 序列號(12位)
 圖片
圖片 - 優點:高性能(單機每秒4萬+)、趨勢遞增29
- 缺點:依賴時鐘同步(時鐘回撥會導致重復)
- 適用場景:分布式高并發系統(如電商訂單)
其實,我們現在的系統,很多場景就是用雪花算法生成的,如流水號等等~
代碼示例:
public class Snowflake {
private long machineId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException("時鐘回撥!");
}
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & 4095; // 12位序列號
if (sequence == 0) timestamp = tilNextMillis(lastTimestamp);
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return (timestamp << 22) | (machineId << 12) | sequence;
}
}4. 數據庫號段模式
- 原理:批量獲取ID段(如一次取1000個),減少數據庫訪問
- 優點:降低數據庫壓力、可用性高(緩存號段)、速度快
- 缺點:在服務器重啟或故障轉移等情況下,可能會導致ID的生成出現不連續的情況。
- 適用場景:中等并發業務(如用戶ID生成)
我們的一些客戶號,當前是用號段模式生成的,然后拼一些業務標記
表結構:
CREATE TABLE id_segment (
biz_tag VARCHAR(50) PRIMARY KEY,
max_id BIGINT NOT NULL,
step INT NOT NULL,
version INT NOT NULL
);5. Redis分布式ID
- 原理:利用INCR原子操作生成遞增ID
 圖片
圖片 - 優點:性能優于數據庫、天然有序、高性能、可擴展性強
- 缺點:依賴Redis可用性
- 適用場景:按日生成的流水號(如訂單號=日期+自增)
代碼示例:
Jedis jedis = new Jedis("redis-host");
Long orderId = jedis.incr("order:20240526");6.百度的uid-generator
優點:避免頻繁生成、吞吐量提升至600萬/秒
適用場景:超大規模分布式系統
基于Twitter的Snowflake算法進行改進,增加了更多的配置和靈活性。
與原始的snowflake算法不同在于,uid-generator支持自定義時間戳、工作機器ID和 序列號 等各部分的位數,而且uid-generator中采用用戶自定義workId的生成策略。
代碼示例:
import com.baidu.fsg.uid.UidGenerator;
import com.baidu.fsg.uid.impl.CachedUidGenerator;
public class UidGeneratorDemo {
public static void main(String[] args) {
// 創建一個UidGenerator實例
UidGenerator uidGenerator = new CachedUidGenerator();
// 初始化,這里只是一個簡單的示例,實際使用時你可能需要根據你的業務場景進行更復雜的配置
// 例如,設置workerId、epoch等
// 注意:在多實例部署時,每個實例的workerId必須唯一
long workerId = 1L; // 示例ID,實際使用時需要保證每個實例的唯一性
long datacenterId = 1L; // 數據中心ID,示例
uidGenerator.init(workerId, datacenterId, null);
// 生成一個UID
long uid = uidGenerator.getUID();
System.out.println("Generated UID: " + uid);
}
}7. 基于Zookeeper的順序節點
利用Zookeeper的順序節點特性來生成全局唯一ID。
 圖片
圖片
優點:
- 利用Zookeeper的集群特性保證高可用。
- ID全局唯一。
缺點:
- 需要依賴Zookeeper集群。
- 可能會受到Zookeeper性能的限制。
- 并發競爭較大不適合用Zookeeper
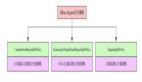
8. 數據庫集群模式
單庫的數據庫自增ID會存在單點問題,所以可以用數據庫集群模式,去解決這個問題。數據庫集群模式:通過多個數據庫實例設置不同的起始值和步長來生成全局唯一的ID。
 圖片
圖片
數據庫集群模式優點:
- 可以有效生成集群中的唯一ID。解決了單點的問題。
- 降低ID生成數據庫操作的負載。
數據庫集群模式缺點:
- 需要獨立部署多個數據庫實例,成本高。
- 后期不方便擴展
9. 美團(Leaf)
Leaf是美團點評開源的分布式ID生成系統,包含基于數據庫和基于Zookeeper的兩種實現方式。
以基于數據庫的自增ID生成策略為例(數據庫表結構):
CREATE TABLE leaf_alloc (
biz_tag VARCHAR(128) NOT NULL COMMENT '業務key',
max_id BIGINT(20) NOT NULL COMMENT '當前已分配的最大id',
step INT(11) NOT NULL COMMENT '每次id的增長步長',
PRIMARY KEY (biz_tag)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;Java 實現:
import java.sql.*;
public class LeafIdGenerator {
private static final String JDBC_URL = "jdbc:mysql://localhost:3306/your_database?useSSL=false&serverTimeznotallow=UTC";
private static final String USERNAME = "your_username";
private static final String PASSWORD = "your_password";
private static final String UPDATE_SQL = "UPDATE leaf_alloc SET max_id = max_id + ? WHERE biz_tag = ?";
private static final String SELECT_SQL = "SELECT max_id FROM leaf_alloc WHERE biz_tag = ? FOR UPDATE";
public synchronized long getId(String bizTag) throws SQLException {
Connection conn = null;
PreparedStatement updateStmt = null;
PreparedStatement selectStmt = null;
ResultSet rs = null;
try {
conn = DriverManager.getConnection(JDBC_URL, USERNAME, PASSWORD);
selectStmt = conn.prepareStatement(SELECT_SQL);
selectStmt.setString(1, bizTag);
rs = selectStmt.executeQuery();
if (rs.next()) {
long maxId = rs.getLong("max_id");
int step = 1000; // 假設步長為1000,你可以從數據庫中讀取這個值
// 假設這里只是簡單演示,不檢查是否超過max_id + step是否溢出
updateStmt = conn.prepareStatement(UPDATE_SQL);
updateStmt.setInt(1, step);
updateStmt.setString(2, bizTag);
updateStmt.executeUpdate();
// 返回ID區間中的一個ID,這里簡單返回maxId(實際應用中可能需要更復雜的策略)
return maxId;
} else {
// 如果沒有找到對應的bizTag,則需要初始化
// ... 初始化代碼省略 ...
throw new RuntimeException("BizTag not found: " + bizTag);
}
} finally {
// 關閉資源,省略了異常處理
if (rs != null) rs.close();
if (selectStmt != null) selectStmt.close();
if (updateStmt != null) updateStmt.close();
if (conn != null) conn.close();
}
}
public static void main(String[] args) {
LeafIdGenerator generator = new LeafIdGenerator();
try {
long id = generator.getId("test-biz-tag");
System.out.println("Generated ID: " + id);
} catch (SQLException e) {
e.printStackTrace();
}
}
}優點:
- 結合了數據庫和Zookeeper的優點,提供了高可用和高性能的ID生成服務。缺點:
- 就是時鐘回撥問題、復雜性高。
10. 滴滴(Tinyid)
Tinyid是滴滴開源的輕量級分布式ID生成系統,它是基于號段模式原理實現的與Leaf如出一轍,每個服務獲取一個號段(1000,2000]、(2000,3000]、(3000,4000]
 圖片
圖片
以下是一個簡化的Tinyid,服務端的偽代碼:
// 假設我們有一個ID生成器,這里用AtomicLong模擬
import java.util.concurrent.atomic.AtomicLong;
public class TinyidService {
private AtomicLong idGenerator = new AtomicLong(0);
// 模擬的ID生成方法
public synchronized long generateId() {
return idGenerator.incrementAndGet();
}
// 這里應該是RESTful API的實現,但為簡化起見,我們省略了HTTP部分
// 客戶端應該通過HTTP請求調用此方法
public long getIdOverHttp() {
return generateId();
}
}客戶端(Java示例)
import okhttp3.*;
public class TinyidClient {
private static final String TINYID_SERVICE_URL = "http://localhost:8080/tinyid/generate";
public static void main(String[] args) {
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url(TINYID_SERVICE_URL)
.build();
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful()) {
throw new IOException("Unexpected code " + response);
} else {
// 假設服務端返回的是純文本格式的ID
String responseBody = response.body().string();
long id = Long.parseLong(responseBody);
System.out.println("Generated ID: " + id);
}
}
});
}
}- 優缺點:簡單、輕量級,但性能可能不如其他方案。