一文教你玩轉 RAG 大模型應用開發
Part.1.RAG這么火,你會用嗎?
自從大模型技術走向市場以來,“幻覺”現象總是對用戶造成困擾,而RAG(Retrieval-Augmented Generation,檢索增強生成)技術正在成為解決這一難題的利器。國內眾多科技大廠在實踐RAG技術時都取得了階段性的成果。
螞蟻集團采用RAG技術,通過知識庫分層構建、復雜文檔處理、混合搜索策略和總結模型優化,答案獲取效率提高約20%。
阿里云通過外掛知識庫提供可靠知識,優化知識檢索與答案生成流程,成功化解智能問答面臨的幻覺、知識更新滯后、隱私數據泄露等挑戰。
嗶哩嗶哩運用大模型升級智能客服系統,優化RAG鏈路和檢索機制,構建全面的領域知識庫,智能客服攔截率提升近30%。
字節跳動充分發揮RAG和FineTuning(微調)兩種建設思路,利用大模型構建答疑機器人,實現研發基建部門答疑值班。
RAG這么厲害,很多小伙伴擼起袖子就想一氣呵成地干好,但卻沒少碰壁,一是發現其所涵蓋的技術棧特別廣泛,二是實現過程中遇到技術難點后一籌莫展。難道要將AI所有的知識都學習一遍才能做好RAG嗎?
Part.2RAG的核心
RAG的核心功能,就是它可以訪問一個外部知識庫或文檔集,從中檢索與當前問題相關的片段,將這些最新或特定領域的外部信息納入“思考過程”,然后再進行回答生成。這使得大模型在回答問題時,不必依賴于其在訓練過程中“記住”的知識,以此有效降低“幻覺”。
RAG使大模型能夠“查閱資料”,將靜態的、受限于訓練時間的語言模型轉變為能夠動態獲取信息、實時擴展知識的智能體。對大模型的“閉卷考試”瞬間變成了“開卷考試”,這種變化對大模型應用效果提升有著巨大潛力。
 圖片
圖片
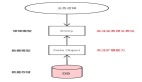
RAG的核心組件包括知識嵌入、檢索器和生成器。
知識嵌入(Knowledge Embedding):將外部知識庫的內容讀取并拆分成塊,通過嵌入模型將文本或其他形式的知識轉化為向量表示,使其能夠在高維語義空間中進行比較。這些嵌入向量捕捉了句子或段落的深層語義信息,并被索引存儲在向量數據庫中,以支持高效檢索。
檢索器(Retriever):負責從外部知識庫(向量表示的存儲)中查找與用戶輸入相關的信息。檢索器采用嵌入向量技術,通過計算語義相似性快速匹配相關文檔。常用的方法包括基于稀疏向量的BM25和基于密集向量的近似最近鄰檢索。
生成器(Generator):利用檢索器返回的相關信息生成上下文相關的答案。生成器通常基于大模型,在內容生成過程中整合檢索到的外部知識,確保生成的結果既流暢又可信。
為我們揭開RAG奧秘的本書作者黃佳,是新加坡科研局首席研究員(Lead Researcher),前埃森哲新加坡公司資深顧問。入行20多年來,他參與過政府部門、銀行、電商、能源等多領域大型項目,積累了極為豐富的人工智能和大數據項目實戰經驗。
Part.3.跟著咖哥,全盤掌握RAG
RAG是大模型時代應用開發的一項偉大創新,彌補了單純靠參數記憶知識的不足,使大模型在應對不斷變化或高度專業化的問題時具有更強的適應性和靈活性。本書從RAG系統構建出發,逐步深入系統優化、評估以及復雜范式的探究,下面分為四個部分逐一詳解。
RAG系統構建
這部分是RAG技術落地的第一步。在數據導入環節,書中詳細講解了如何讀取與解析多樣化的文件格式,包括TXT文本、CSV文件、網頁文檔、Markdown文件、PDF文件等,還有借助Unstructured工具從圖片中提取文字并導入。
 圖片
圖片
文本分塊是影響檢索精度與生成質量的關鍵步驟,書中介紹了按固定字符數、遞歸、基于格式或語義等多種分塊策略。針對信息嵌入,介紹了從早期詞嵌入到當下流行的OpenAI、Jina等現代嵌入模型,詳細說明了如何對嵌入模型進行微調。
針對向量存儲則介紹了Milvus、Weaviate等主流向量數據庫,以及選型時在索引類型、檢索方式、多模態支持等多方面因素的考量,為構建高效的向量存儲系統提供依據。
RAG系統優化
優化是提升RAG系統性能的關鍵。在檢索前處理中,介紹查詢構建如何實現Text-to-SQL等復雜轉換,查詢翻譯能將簡單模糊的查詢重寫為精準表述,查詢路由則通過邏輯路由等方式將查詢導向最合適的數據源。
索引優化給出節點-句子滑動窗口檢索、分層合并等實用方法,提高檢索效率。檢索后處理涵蓋RRF、Cross-Encoder等重排手段,以及Contextual Compression Retriever等壓縮技術,這些手段和技術可以對檢索結果執行校正操作。
 圖片
圖片
在響應生成階段,通過改進提示詞、選擇適配的大模型,采用Self-RAG等優化方式,提升生成內容的質量,確保系統輸出既準確又符合用戶需求。
RAG系統評估
評估是度量RAG系統性能的重要手段。書中構建了全面的評估體系,評估數據集為測試提供基礎素材,檢索評估通過精確率、召回率等7種指標,度量系統從知識庫中獲取相關信息的能力。響應評估基于n-gram匹配、語義相似性等3類指標,判斷生成回答的質量。
 圖片
圖片
該部分還介紹了RAGAS、TruLens等4種評估框架,幫助讀者從不同維度對RAG系統進行量化分析,清晰了解系統在準確性、相關性、可靠性等方面的表現,進而有針對性地進行改進。
復雜RAG范式
最后一部分是對RAG技術的前沿探索,包括以下RAG范式:
GraphRAG:整合知識圖譜,提升對復雜問題的處理能力;
上下文檢索:突破傳統上下文限制的困境,為用戶提供更貼合語境的回答;
Modular RAG:實現從固定流程到靈活架構的轉變;
Agentic RAG:引入自主代理驅動機制,讓系統具備更強的自主性和智能性;
Multi-Modal RAG:實現多模態檢索增強生成,支持文本、圖像、音頻等多種信息融合。
 圖片
圖片
經過這四個部分的系統化學習,讀者將打下RAG的理論基礎,并掌握RAG實施的方法與工具,大力提升大模型的工作效能。
Part.4結語
RAG實現了“模型的智力”與“人類知識寶庫”的有機結合,使得智能系統更加緊密地嵌入實際業務流程,為用戶提供始終符合時代、情境、專業要求的智慧服務。