深入Linux系統調用:原理、機制與實戰全解析
在 Linux 操作系統中,系統調用是連接用戶程序與內核的關鍵橋梁。當我們在終端輸入命令,或是運行各類應用程序時,背后都離不開系統調用的支撐。它不僅是內核為用戶空間提供服務的核心接口,更是理解 Linux 運行機制的重要鑰匙。若將操作系統比作精密的工廠,內核便是掌控全局的中樞,而系統調用則是連接生產線(用戶程序)與中樞的通道。用戶程序通過它向內核請求服務,無論是文件操作、進程管理,還是內存分配等任務,系統調用都發揮著不可或缺的作用。
從本質上看,系統調用是內核提供的接口,常以 C 函數形式呈現,方便開發者調用系統功能。在 Linux 系統里,它構建了用戶程序安全訪問硬件資源的通道。由于硬件資源由內核底層操作,若用戶程序直接訪問,易引發系統不穩定甚至崩潰,而系統調用就像門衛,保障了系統的安全與穩定。在多任務管理方面,系統調用如同工廠調度員。內核借助它合理調度 CPU 時間,讓多個進程協同工作,顯著提升系統并發處理能力,確保系統流暢運行。
對開發者和系統管理員而言,掌握系統調用至關重要。開發者編寫應用程序時,可通過 open、read 等系統調用實現文件操作,用 fork、exec 進行進程管理;系統管理員則能借助 sysinfo 獲取系統性能信息,使用 ioctl 配置管理設備。掌握系統調用,就能更好地與 Linux 交互,釋放系統潛能。接下來,就讓我們一起深入探索 Linux 系統調用的奇妙世界,層層揭開它神秘的面紗,探尋它的原理與實現機制,看看這個強大的工具是如何在幕后掌控整個操作系統的運行,為我們的日常操作和開發工作保駕護航的。
一、Linux 系統調用是什么?
1.1 系統調用的定義
系統調用,顧名思義,說的是操作系統提供給用戶程序調用的一組“特殊”接口。用戶程序可以通過這組“特殊”接口來獲得操作系統內核提供的服務,比如用戶可以通過文件系統相關的調用請求系統打開文件、關閉文件或讀寫文件,可以通過時鐘相關的系統調用獲得系統時間或設置定時器等。
從邏輯上來說,系統調用可被看成是一個內核與用戶空間程序交互的接口——它好比一個中間人,把用戶進程的請求傳達給內核,待內核把請求處理完畢后再將處理結果送回給用戶空間。系統服務之所以需要通過系統調用來提供給用戶空間的根本原因是為了對系統進行“保護”,因為我們知道Linux的運行空間分為內核空間與用戶空間,它們各自運行在不同的級別中,邏輯上相互隔離。所以用戶進程在通常情況下不允許訪問內核數據,也無法使用內核函數,它們只能在用戶空間操作用戶數據,調用用戶空間函數。
比如我們熟悉的“hello world”程序(執行時)就是標準的用戶空間進程,它使用的打印函數printf就屬于用戶空間函數,打印的字符“hello word”字符串也屬于用戶空間數據。但是很多情況下,用戶進程需要獲得系統服務(調用系統程序),這時就必須利用系統提供給用戶的“特殊接口”——系統調用了,它的特殊性主要在于規定了用戶進程進入內核的具體位置;換句話說,用戶訪問內核的路徑是事先規定好的,只能從規定位置進入內核,而不準許肆意跳入內核。有了這樣的陷入內核的統一訪問路徑限制才能保證內核安全無虞。
我們可以形象地描述這種機制:作為一個游客,你可以買票要求進入野生動物園,但你必須老老實實地坐在觀光車上,按照規定的路線觀光游覽。當然,不準下車,因為那樣太危險,不是讓你丟掉小命,就是讓你嚇壞了野生動物。
1.2 存在的必要性
系統調用的存在,有著諸多至關重要的原因,每一點都與操作系統的穩定、安全和高效運行息息相關。
(1)保護系統資源
操作系統的資源,無論是硬件資源,如 CPU、內存、磁盤等,還是軟件資源,像文件、進程等,都是極其珍貴且需要嚴格保護的。內核如同一位嚴謹的管家,牢牢掌控著這些資源。如果用戶程序能夠隨意直接訪問這些資源,就好比未經授權的人隨意進出管家的核心管理區域,必然會引發混亂,導致系統的安全性和穩定性遭受嚴重威脅。
而系統調用就像是管家設置的一扇安全門,用戶程序必須通過系統調用這一正規途徑向內核提出資源訪問請求,內核會依據一系列嚴格的規則,如用戶權限、資源使用狀態等,對請求進行細致的審查和合理的裁決,只有符合條件的請求才會被批準,從而有效避免了用戶程序對系統資源的非法或不當訪問,保障了系統的穩定和安全。
(2)提供統一接口
在計算機系統中,硬件設備的種類繁雜多樣,不同的硬件設備有著各自獨特的操作方式和特性。這就好比一個大型工廠里有著各種不同類型的機器設備,每臺設備的操作方法都不一樣。如果沒有一個統一的接口,用戶程序在訪問不同硬件設備時,就需要針對每種設備編寫復雜且差異巨大的代碼,這無疑會極大地增加編程的難度和復雜性,降低開發效率。而系統調用就像是工廠里的統一操作指南,為用戶空間提供了一種簡潔、統一的硬件抽象接口。
無論用戶程序需要訪問何種硬件設備,都只需通過相應的系統調用,而無需深入了解硬件設備的底層細節,這使得編程變得更加簡單、高效,也提高了應用程序的可移植性,就像按照統一操作指南,工人可以輕松操作不同的設備,而無需為每種設備單獨學習復雜的操作方法。
(3)實現多任務和虛擬內存管理
在現代操作系統中,多任務處理和虛擬內存管理是至關重要的功能。多任務處理就像一位優秀的調度員同時安排多個任務并行執行,讓多個進程能夠在同一時間內有條不紊地運行,充分利用系統資源,提高系統的并發處理能力。虛擬內存管理則如同一個智能的內存分配助手,為每個進程分配獨立的虛擬地址空間,使得進程在運行時仿佛擁有了自己獨立的內存空間,互不干擾。而這些功能的實現,都離不開系統調用的支持。系統調用能夠讓內核清晰地了解每個進程的運行狀態和資源需求,從而合理地調度 CPU 時間,精準地分配內存資源。
當一個進程通過系統調用請求創建新進程時,內核會根據系統的資源狀況和調度策略,為新進程分配必要的資源,并將其納入多任務管理的范疇;在內存管理方面,進程通過系統調用請求內存分配時,內核會依據虛擬內存管理機制,為進程分配合適的虛擬內存空間,并負責管理虛擬內存與物理內存之間的映射關系,確保進程能夠正常訪問內存資源,就像調度員根據任務需求合理安排工作時間,內存分配助手根據進程需要分配和管理內存空間,保障了系統多任務和虛擬內存管理功能的順利實現。
1.3為什么需要系統調用
linux內核中設置了一組用于實現系統功能的子程序,稱為系統調用。系統調用和普通庫函數調用非常相似,只是系統調用由操作系統核心提供,運行于內核態,而普通的函數調用由函數庫或用戶自己提供,運行于用戶態。
一般的,進程是不能訪問內核的。它不能訪問內核所占內存空間也不能調用內核函數。CPU硬件決定了這些(這就是為什么它被稱作“保護模式”)。
為了和用戶空間上運行的進程進行交互,內核提供了一組接口。透過該接口,應用程序可以訪問硬件設備和其他操作系統資源。這組接口在應用程序和內核之間扮演了使者的角色,應用程序發送各種請求,而內核負責滿足這些請求(或者讓應用程序暫時擱置)。實際上提供這組接口主要是為了保證系統穩定可靠,避免應用程序肆意妄行,惹出大麻煩。
系統調用在用戶空間進程和硬件設備之間添加了一個中間層,該層主要作用有三個:
- 它為用戶空間提供了一種統一的硬件的抽象接口。比如當需要讀些文件的時候,應用程序就可以不去管磁盤類型和介質,甚至不用去管文件所在的文件系統到底是哪種類型。
- 系統調用保證了系統的穩定和安全。作為硬件設備和應用程序之間的中間人,內核可以基于權限和其他一些規則對需要進行的訪問進行裁決。舉例來說,這樣可以避免應用程序不正確地使用硬件設備,竊取其他進程的資源,或做出其他什么危害系統的事情。
- 每個進程都運行在虛擬系統中,而在用戶空間和系統的其余部分提供這樣一層公共接口,也是出于這種考慮。如果應用程序可以隨意訪問硬件而內核又對此一無所知的話,幾乎就沒法實現多任務和虛擬內存,當然也不可能實現良好的穩定性和安全性。在Linux中,系統調用是用戶空間訪問內核的惟一手段;除異常和中斷外,它們是內核惟一的合法入口。
1.4 API/POSIX/C庫的區別與聯系
一般情況下,應用程序通過應用編程接口(API)而不是直接通過系統調用來編程。這點很重要,因為應用程序使用的這種編程接口實際上并不需要和內核提供的系統調用一一對應。
一個API定義了一組應用程序使用的編程接口。它們可以實現成一個系統調用,也可以通過調用多個系統調用來實現,而完全不使用任何系統調用也不存在問題。實際上,API可以在各種不同的操作系統上實現,給應用程序提供完全相同的接口,而它們本身在這些系統上的實現卻可能迥異。
在Unix世界中,最流行的應用編程接口是基于POSIX標準的,其目標是提供一套大體上基于Unix的可移植操作系統標準。POSIX是說明API和系統調用之間關系的一個極好例子。在大多數Unix系統上,根據POSIX而定義的API函數和系統調用之間有著直接關系。
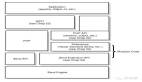
Linux的系統調用像大多數Unix系統一樣,作為C庫的一部分提供如下圖所示。C庫實現了 Unix系統的主要API,包括標準C庫函數和系統調用。所有的C程序都可以使用C庫,而由于C語言本身的特點,其他語言也可以很方便地把它們封裝起來使用。
從程序員的角度看,系統調用無關緊要,他們只需要跟API打交道就可以了。相反,內核只跟系統調用打交道;庫函數及應用程序是怎么使用系統調用不是內核所關心的。
關于Unix的界面設計有一句通用的格言“提供機制而不是策略”。換句話說,Unix的系統調用抽象出了用于完成某種確定目的的函數。至干這些函數怎么用完全不需要內核去關心。區別對待機制(mechanism)和策略(policy)是Unix設計中的一大亮點。大部分的編程問題都可以被切割成兩個部分:“需要提供什么功能”(機制)和“怎樣實現這些功能”(策略)。
區別
api是函數的定義,規定了這個函數的功能,跟內核無直接關系。而系統調用是通過中斷向內核發請求,實現內核提供的某些服務。
聯系
- 一個api可能會需要一個或多個系統調用來完成特定功能。通俗點說就是如果這個api需要跟內核打交道就需要系統調用,否則不需要。
- 程序員調用的是API(API函數),然后通過與系統調用共同完成函數的功能。因此,API是一個提供給應用程序的接口,一組函數,是與程序員進行直接交互的。系統調用則不與程序員進行交互的,它根據API函數,通過一個軟中斷機制向內核提交請求,以獲取內核服務的接口。
- 并不是所有的API函數都一一對應一個系統調用,有時,一個API函數會需要幾個系統調用來共同完成函數的功能,甚至還有一些API函數不需要調用相應的系統調用(因此它所完成的不是內核提供的服務)
二、系統調用與用戶程序的交互
系統調用(system calls),Linux內核, GNU C庫(glibc)
在電腦中,系統調用(英語:system call),指運行在用戶空間的程序向操作系統內核請求需要更高權限運行的服務。系統調用提供用戶程序與操作系統之間的接口。大多數系統交互式操作需求在內核態執行。如設備IO操作或者進程間通信。
用戶空間(用戶態)和內核空間(內核態)
操作系統的進程空間可分為用戶空間和內核空間,它們需要不同的執行權限。其中系統調用運行在內核空間。
庫函數
系統調用和普通庫函數調用非常相似,只是系統調用由操作系統內核提供,運行于內核核心態,而普通的庫函數調用由函數庫或用戶自己提供,運行于用戶態。
典型實現(Linux)
Linux 在x86上的系統調用通過 int 80h 實現,用系統調用號來區分入口函數。操作系統實現系統調用的基本過程是:
- 應用程序調用庫函數(API);
- API 將系統調用號存入 EAX,然后通過中斷調用使系統進入內核態;
- 內核中的中斷處理函數根據系統調用號,調用對應的內核函數(系統調用);
- 系統調用完成相應功能,將返回值存入 EAX,返回到中斷處理函數;
- 中斷處理函數返回到 API 中;
- API 將 EAX 返回給應用程序。
應用程序調用系統調用的過程是:
- 把系統調用的編號存入 EAX;
- 把函數參數存入其它通用寄存器;
- 觸發 0x80 號中斷(int 0x80)。
查看系統調用號
- 使用命令cat /usr/include/asm/unistd_32.h來打開32位系統調用表
- 使用命令cat /usr/include/asm/unistd_64.h來打開32位系統調用表
簡介幾種系統調用函數:write、read、open、close、ioctl
在 Linux 中,一切(或幾乎一切)都是文件,因此,文件操作在 Linux 中是十分重要的,為此,Linux 系統直接提供了一些函數用于對文件和設備進行訪問和控制,這些函數被稱為系統調用(syscall),它們也是通向操作系統本身的接口。
系統調用工作在內核態,實際上,系統調用是用戶空間訪問內核空間的唯一手段(除異常和陷入外,它們是內核唯一的合法入口)。系統調用的主要作用如下:
- 1)系統調用為用戶空間提供了一種硬件的抽象接口,這樣,當需要讀寫文件時,應用程序就可以不用管磁盤類型和介質,甚至不用去管文件所在的文件系統到底是哪種類型;
- 2)系統調用保證了系統的穩定和安全。作為硬件設備和應用程序之間的中間人,內核可以基于權限、用戶類型和其他一些規則對需要進行的訪問進行判斷;
- 3)系統調用是實現多任務和虛擬內存的前提
要訪問系統調用,通常通過 C 庫中定義的函數調用來進行。它們通常都需要定義零個、一個或幾個參數(輸入),而且可能產生一些副作用(會使系統的狀態發生某種變化)。系統調用還會通過一個 long 類型的返回值來表示成功或者錯誤。通常,用一個負的值來表明錯誤,0表示成功。系統調用出現錯誤時,C 庫會把錯誤碼寫入 errno 全局變量,通過調用 perror() 庫函數,可以把該變量翻譯成用戶可理解的錯誤字符串。
2.1 用戶程序發起調用的方式
(1)write 系統調用
在 Linux 系統中,用戶程序發起系統調用主要有兩種常見方式。一種是通過應用程序編程接口(API),這些 API 通常是對系統調用的封裝,以更友好、易用的形式呈現給開發者。另一種則是在一些特定場景下,直接使用 syscall 函數。
以 write 函數為例,它是一個用于向文件描述符寫入數據的系統調用封裝函數,在 C 語言中被廣泛應用。當我們需要將數據寫入文件時,便可以使用 write 函數。以下是一個簡單的 C 語言示例代碼,展示了如何使用 write 函數將字符串寫入標準輸出(通常是終端屏幕):
#include <unistd.h>
#include <stdio.h>
int main() {
char *message = "Hello, World!\n";
int len = 15; // 包括空終止符的長度
// 使用write函數將字符串寫入stdout
if (write(1, message, len) != len) {
perror("write error");
return 1;
}
return 0;
}在這段代碼中,首先定義了一個字符串 message,即我們想要輸出的內容,以及它的長度 len。然后,調用 write 函數,其第一個參數 1 代表標準輸出的文件描述符,在 Linux 系統中,文件描述符是一個非負整數,用于標識打開的文件或設備,標準輸出的文件描述符通常為 1;第二個參數 message 是指向要寫入數據緩沖區的指針,也就是我們定義的字符串;第三個參數 len 則表示要寫入數據的字節數。如果 write 函數返回值不等于請求寫入的字節數 len,說明寫入過程出現了錯誤,此時通過 perror 函數輸出錯誤信息,并返回 1 表示程序異常結束。如果寫入成功,則正常返回 0 。
在這個例子中,write 函數雖然看似只是一個普通的函數調用,但實際上它是對底層系統調用的封裝。當程序執行 write 函數時,會進一步觸發系統調用機制,實現從用戶態到內核態的切換,進而完成實際的寫入操作。這種通過 API 封裝系統調用的方式,極大地簡化了開發者的工作,使得我們無需深入了解底層系統調用的復雜細節,就能輕松實現文件寫入等功能 。
(2)read 系統調用
系統調用 read 的作用是:從文件描述符 fildes 相關聯的文件里讀入 nbytes 個字節的數據,并把它們放到數據區 buf 中。它返回實際讀入的字節數,這可能會小于請求的字節數。如果 read 調用返回 0,就表示沒有讀入任何數據,已到達了文件尾;如果返回 -1,則表示 read 調用出現了錯誤。read 系統調用的原型如下:
#include <unistd.h>
size_t read(int fildes,void *buf,size_t nbytes);用一段代碼演示一下用法:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
char buffer[30];
size_t x = read(0,buffer,30);
write(1,buffer,x);
exit(0);
}
/* 輸出結果:
hello ,my name is tongye!
hello ,my name is tongye!
*/這段代碼使用 read 系統調用函數從標準輸入讀取 30 個字節到緩沖區 buffer 中去(輸出結果中的第一行是從標準輸入鍵入的),然后使用 write 系統調用函數將 buffer 中的字節寫到標準輸出中去。
(3)open 系統調用
系統調用 open 用于創建一個新的文件描述符。
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int open(const char *path,int oflags);
int open(const char *path,int oflags,mode_t mode); // oflags 標志為 O_CREAT 時,使用這種格式open 建立了一條到文件或設備的訪問路徑。如果調用成功,它將返回一個可以被 read、write 和其他系統調用使用的文件描述符。這個文件描述符是唯一的,不會與任何其他運行中的進程共享。在調用失敗時,將返回 -1 并設置全局變量 errno 來指明失敗的原因。
使用 open 系統調用時,準備打開的文件或設備的名字作為參數 path 傳遞給函數,oflags 參數用于指定打開文件所采取的動作。oflags 參數是通過命令文件訪問模式與其他可選模式相結合的方式來指定的,open 調用必須指定以下文件訪問模式之一:
- 1)O_RDONLY:以只讀方式打開;
- 2)O_WRONLY:以只寫方式打開;
- 3)O_RDWR :以讀寫方式打開。
另外,還有以下幾種可選模式的組合( 用按位或 || 來操作 ):
- 4)O_APPEND:把寫入數據追加在文件的末尾;
- 5)O_TRUNC:把文件長度設置為零,丟棄已有的內容;
- 6)O_CREAT:如果需要,就按照參數 mode 中給出的訪問模式創建文件;
- 7)O_EXCL:與 O_CREAT 一起使用,確保調用者創建出文件。使用這個模式可以防止兩個程序同時創建同一個文件,如果文件已經存在,open 調用將失敗。
當使用 O_CREAT 標志的 open 調用來創建文件時,需要使用有 3 個參數格式的 open 調用。其中,第三個參數 mode 是幾個標志按位或后得到的,這些標志在頭文件 sys/stat.h 中定義,如下:
標志 | 說明 |
S_IRUSR | 文件屬主可讀 |
S_IWUSR | 文件屬主可寫 |
S_IXUSR | 文件屬主可執行 |
S_IRGRP | 文件所在組可讀 |
S_IWGRP | 文件所在組可寫 |
S_IWOTH | 文件所在組可執行 |
S_IROTH | 其他用戶可讀 |
S_IWOTH | 其他用戶可寫 |
S_IWOTH | 其他用戶可執行 |
用一個例子說明一下:
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
int main()
{
open("file",O_CREAT,S_IRUSR | S_IWGRP);
exit(0);
}執行這段代碼將在當前目錄下創建一個名為 file 的文件,該文件對文件屬主可讀,對文件所在組可寫,用 ls -l 命令查看如下:
[tongye@Iocalhost OpenSysCaII]$ Is -I
total 20
-r---W---- 1 tongye tongye 0 0ct 24 00:55 file
-rw-rw-r-- 1 tongye tongye 96 0ct 24 00:54 Makefile
-rwxrwxr-x 1 tongye tongye 8496 0ct 24 00:57
-rw-rw-r-- 1 tongye tongye 127 0ct 24 00:57 open_sys_calT.c可以看到有一個名為 file 的文件,該文件就是使用 open 系統調用創建的,文件的權限為文件屬主可讀,文件所在組可寫。
(4)close 系統調用
系統調用 close 可以用來終止文件描述符 fildes 與其對應文件之間的關聯。當 close 系統調用成功時,返回 0,文件描述符被釋放并能夠重新使用;調用出錯,則返回 -1。
#include <unistd.h>
int close(int fildes);(5)ioctl 系統調用
系統調用 ioctl 提供了一個用于控制設備及其描述符行為和配置底層服務的接口。終端、文件描述符、套接字甚至磁帶機都可以有為它們定義的 ioctl。
#include <unistd.h>
int ioctl(int fildes,int cmd,...);octl 對描述符 fildes 引用的對象執行 cmd 參數中給出的操作。
2.2 調用過程中的狀態切換
當用戶程序發起系統調用時,一個關鍵的環節便是從用戶態到內核態的狀態切換。在 Linux 系統中,這種切換是通過軟中斷機制來實現的,而軟中斷又是借助中斷向量表來精準找到對應的中斷處理程序。
在計算機系統中,用戶態和內核態是兩種不同的執行模式。用戶態下運行的程序權限較低,只能訪問用戶空間的內存,并且不能直接操作硬件資源,這就像一個普通員工在公司的特定工作區域內工作,權限有限,不能隨意進入核心管理區域。而內核態則擁有對系統所有資源的完全控制權限,包括硬件訪問、內存管理和進程調度等,類似于公司的核心管理層,擁有最高權限,可以掌控公司的一切資源。
為了實現從用戶態到內核態的切換,Linux 使用軟中斷指令。以 x86 架構為例,早期使用 int 0x80 指令來觸發系統調用軟中斷,后來隨著技術發展,引入了更高效的 syscall 指令。當用戶程序執行到發起系統調用的代碼時,如上述的 write 函數調用,會執行相應的軟中斷指令。這條指令就像一個特殊的 “通行證”,它會觸發 CPU 產生一個軟件中斷信號。
CPU 接收到這個軟中斷信號后,會暫停當前用戶態程序的執行,就像一個正在專心工作的員工突然被緊急通知停下手中工作。接著,CPU 開始進行一系列復雜的操作來切換到內核態。它首先會保存當前用戶態程序的上下文信息,包括程序計數器(記錄下一條要執行的指令地址)、通用寄存器的值等,這些信息就像是員工停下工作時記錄的工作進度和手頭的資料,以便后續能夠恢復工作。然后,CPU 根據中斷向量表來查找與該軟中斷對應的中斷處理程序的入口地址。
中斷向量表是一個非常重要的數據結構,它就像一本詳細的 “指南手冊”,存儲了所有中斷處理程序的地址。每個中斷都被賦予一個唯一的中斷號,這個中斷號就像是手冊中的頁碼,通過它可以快速定位到相應中斷處理程序的地址。在系統調用軟中斷的情況下,CPU 會根據軟中斷對應的中斷號,從中斷向量表中找到系統調用處理程序的入口地址,進而跳轉到該地址開始執行內核態的代碼。
一旦進入內核態,系統調用處理程序就會根據用戶程序傳遞過來的系統調用號和參數,執行相應的內核服務例程。在 write 函數對應的系統調用中,內核會根據傳遞的文件描述符、數據緩沖區和數據長度等參數,在內核空間中進行實際的文件寫入操作,訪問底層的硬件設備(如磁盤)來完成數據的存儲。
當內核完成系統調用的處理后,會將結果返回給用戶程序。此時,CPU 會再次進行上下文切換,恢復之前保存的用戶態程序的上下文信息,就像員工重新拿起之前記錄的工作進度和資料,繼續之前被中斷的工作。然后,CPU 返回到用戶態,繼續執行用戶程序中系統調用之后的代碼 。
從用戶態到內核態的切換過程是 Linux 系統調用實現的關鍵環節,它涉及到 CPU、內存、中斷向量表等多個組件的協同工作,通過軟中斷機制和中斷向量表的配合,實現了用戶程序與內核之間安全、高效的通信,確保了系統的穩定運行和資源的合理利用 。
三、系統調用的實現原理
3.1 系統調用號與系統調用表
在 Linux 系統調用的實現過程中,系統調用號與系統調用表扮演著不可或缺的關鍵角色。
系統調用號,簡單來說,是一個獨一無二的標識符,就像每個人都有一個獨特的身份證號碼一樣,每個系統調用都被賦予了一個唯一的系統調用號。在 x86 架構中,系統調用號通常是通過 eax 寄存器傳遞給內核的。在用戶空間執行系統調用之前,會將對應的系統調用號存入 eax 寄存器,這樣當系統進入內核態時,內核就能依據這個系統調用號,精準地知曉用戶程序究竟請求的是哪一個系統調用。
以常見的文件操作相關系統調用為例,打開文件的系統調用 open,它擁有特定的系統調用號,當用戶程序需要打開文件時,會將 open 系統調用對應的系統調用號存入 eax 寄存器,再發起系統調用,內核就能根據這個號碼識別出用戶的意圖是打開文件。這種通過唯一編號來標識系統調用的方式,極大地提高了系統調用處理的效率和準確性,避免了因名稱解析等復雜操作帶來的性能損耗 。
而系統調用表,則是一個存儲著系統調用函數指針的數組,它就像是一本精心編制的索引目錄,數組的每個元素都是一個指向特定系統調用處理函數的指針。在 x86 架構下,系統調用表的定義和實現與具體的內核版本和架構相關。
在 64 位系統中,系統調用表定義在arch/x86/kernel/syscall_64.c文件中 ,其數組名為sys_call_table,該數組的大小為__NR_syscall_max + 1,其中__NR_syscall_max是一個宏,在 64 位模式下,它的值為 542 ,這個宏定義于include/generated/asm-offsets.h文件,該文件是在 Kbuild 編譯后生成的。系統調用表中的元素類型為sys_call_ptr_t,這是通過 typedef 定義的函數指針,它指向的是具體的系統調用處理函數。當內核接收到系統調用請求,并獲取到系統調用號后,就會以這個系統調用號作為索引,迅速在系統調用表中找到對應的函數指針,進而調用相應的系統調用處理函數,執行具體的系統調用操作 。
假設系統調用號為n,那么系統調用表sys_call_table中第n個元素sys_call_table[n]就指向了處理該系統調用的函數。如果系統調用號為 1,對應sys_call_table[1],它指向的就是處理 write 系統調用的函數,當內核根據系統調用號 1 在表中找到這個指針并調用相應函數時,就能完成實際的文件寫入操作。系統調用號與系統調用表的緊密配合,構成了 Linux 系統調用實現的重要基礎,它們使得內核能夠高效、準確地響應用戶程序的各種系統調用請求,保障了系統的穩定運行和高效工作 。
3.2 系統調用處理程序
系統調用處理程序是系統調用實現過程中的核心環節,它負責處理用戶程序發起的系統調用請求,執行相應的內核服務例程,并返回處理結果。當用戶程序發起系統調用時,會觸發軟中斷,從而進入內核態,開始執行系統調用處理程序。
系統調用處理程序的工作流程嚴謹而有序。當 CPU 響應軟中斷進入內核態后,首先會保存當前用戶程序的寄存器狀態。這一步至關重要,因為寄存器中存儲著用戶程序當前的執行狀態和相關數據,保存這些寄存器狀態就如同為用戶程序的執行進度拍了一張 “快照”,以便在系統調用完成后能夠準確地恢復到調用前的狀態,繼續執行用戶程序。在 x86 架構中,通常會將寄存器的值壓入到核心棧中,這些寄存器包括通用寄存器如 eax、ebx、ecx、edx 等,以及程序計數器(記錄下一條要執行的指令地址)等關鍵寄存器。
保存完寄存器狀態后,系統調用處理程序會根據用戶程序傳遞過來的系統調用號,在系統調用表中查找對應的系統調用處理函數。這個查找過程就像是在一本索引清晰的大字典中查找特定的詞條,系統調用號就是詞條的索引,通過它能夠快速定位到系統調用表中對應的函數指針,進而找到真正執行系統調用功能的處理函數。如果系統調用號為 5,表示打開文件的系統調用,處理程序就會根據這個 5 作為索引,在系統調用表中找到指向sys_open函數的指針,這個sys_open函數就是專門負責處理打開文件系統調用的函數 。
找到對應的處理函數后,系統調用處理程序就會調用該函數,執行相應的內核服務例程。在執行過程中,處理函數會根據系統調用的具體需求,訪問和操作內核資源,完成用戶程序請求的任務。在執行文件寫入的系統調用時,處理函數會根據傳遞過來的文件描述符、數據緩沖區和數據長度等參數,在內核空間中進行實際的文件寫入操作,訪問底層的磁盤設備,將數據存儲到指定的文件中 。
當內核服務例程執行完畢后,系統調用處理程序會將執行結果返回給用戶程序。在返回之前,會先恢復之前保存的用戶程序寄存器狀態,就像把之前拍的 “快照” 重新還原,讓 CPU 回到系統調用前的狀態。然后,CPU 會從內核態切換回用戶態,繼續執行用戶程序中系統調用之后的代碼,將系統調用的執行結果傳遞給用戶程序,用戶程序就可以根據這個結果進行后續的處理 。
系統調用處理程序的工作流程確保了系統調用的安全、高效執行,它在用戶程序與內核之間搭建起了一座可靠的橋梁,使得用戶程序能夠在不直接訪問內核資源的情況下,通過系統調用獲取內核提供的各種服務,保障了系統的穩定性和安全性 。
3.3 參數傳遞與返回值處理
在系統調用過程中,參數傳遞和返回值處理是兩個關鍵環節,它們確保了用戶程序與內核之間能夠準確、有效地進行數據交互。
系統調用的參數傳遞方式與硬件架構密切相關。以常見的 x86 架構為例,在 32 位系統中,當用戶程序發起系統調用時,參數通常通過寄存器來傳遞。具體來說,ebx、ecx、edx、esi 和 edi 這幾個寄存器按照順序存放前五個參數。如果系統調用需要傳遞六個或更多參數,由于寄存器數量有限,此時會用一個單獨的寄存器(通常是 eax)存放指向所有這些參數在用戶空間地址的指針,然后通過內存空間進行參數傳遞。在執行一個需要傳遞多個參數的文件寫入系統調用時,前五個參數(如文件描述符、數據緩沖區指針、數據長度等)可能分別存放在 ebx、ecx、edx、esi 和 edi 寄存器中,如果還有其他參數,就會將這些參數在用戶空間的地址存放在 eax 寄存器中,內核可以根據這個地址從用戶空間獲取完整的參數 。
在 64 位的 x86 架構系統中,參數傳遞規則有所不同。前 6 個整數或指針參數會在寄存器 RDI、RSI、RDX、RCX、R8、R9 中傳遞,對于嵌套函數,R10 用作靜態鏈指針,其他參數則在堆棧上傳遞。這種參數傳遞方式充分利用了 64 位架構下寄存器數量增加的優勢,提高了參數傳遞的效率和靈活性 。
關于系統調用的返回值,也有著明確的約定。在 Linux 系統中,通常用一個負的返回值來表明系統調用執行過程中出現了錯誤。返回值為 - 1 可能表示權限不足,-2 可能表示文件不存在等。不同的負值對應著不同的錯誤類型,這些錯誤類型的定義可以在errno.h頭文件中找到。當用戶程序接收到負的返回值時,可以通過查看errno變量的值來確定具體的錯誤原因,并且可以調用perror()庫函數,將errno的值翻譯成用戶可以理解的錯誤字符串,以便進行錯誤處理 。
如果系統調用執行成功,返回值通常為正值或 0。對于一些返回數據的系統調用,如讀取文件內容的系統調用,返回值可能是實際讀取到的字節數;而對于一些只執行操作不返回具體數據的系統調用,成功時返回值可能為 0,表示操作順利完成。在執行讀取文件系統調用時,如果成功讀取到數據,返回值就是實際讀取的字節數,用戶程序可以根據這個返回值來判斷讀取操作是否成功以及獲取到的數據量 。
參數傳遞和返回值處理機制是系統調用實現的重要組成部分,它們確保了用戶程序與內核之間能夠準確地傳遞數據和信息,使得系統調用能夠按照預期的方式執行,并將結果反饋給用戶程序,為應用程序的正確運行提供了堅實的保障 。
四、不同架構下的系統調用實現差異
4.1 x86架構
x86 架構下系統調用的實現方式隨著技術的發展不斷演進,經歷了從 int 0x80 到 syscall 指令的重要轉變。
在早期,x86 架構主要通過 int 0x80 指令來實現系統調用。當用戶程序需要發起系統調用時,會執行 int 0x80 這條軟中斷指令。這一指令就像是一個特殊的 “信號彈”,它會觸發 CPU 產生一個軟件中斷信號。CPU 在接收到這個信號后,會暫停當前用戶態程序的執行,轉而執行中斷處理程序。在這個過程中,系統調用號被存放在 eax 寄存器中,參數則通過 ebx、ecx、edx 等寄存器傳遞。例如,當執行一個打開文件的系統調用時,會將打開文件系統調用對應的系統調用號存入 eax 寄存器,文件路徑等參數可能存放在 ebx 等寄存器中 。
與 int 0x80 指令緊密相關的是 entry_INT80_32 函數,它在系統調用處理流程中扮演著關鍵角色。當 int 0x80 中斷發生后,CPU 會跳轉到 entry_INT80_32 函數執行。這個函數主要負責保存用戶態的寄存器狀態,因為這些寄存器中存儲著用戶程序當前的執行狀態和相關數據,保存它們就如同為用戶程序的執行進度拍了一張 “快照”,以便在系統調用完成后能夠準確地恢復到調用前的狀態,繼續執行用戶程序。在 entry_INT80_32 函數中,會將寄存器的值壓入到核心棧中,這些寄存器包括通用寄存器如 eax、ebx、ecx、edx 等,以及程序計數器(記錄下一條要執行的指令地址)等關鍵寄存器 。
保存完寄存器狀態后,entry_INT80_32 函數會調用 do_syscall_32_irqs_on 函數,這個函數才是真正處理系統調用的核心函數。它會根據 eax 寄存器中保存的系統調用號,在系統調用表中查找對應的系統調用處理函數。系統調用表就像是一本精心編制的索引目錄,數組的每個元素都是一個指向特定系統調用處理函數的指針。do_syscall_32_irqs_on 函數會以系統調用號作為索引,在系統調用表中找到對應的函數指針,進而調用相應的系統調用處理函數,執行具體的系統調用操作 。
隨著 x86 架構的不斷發展,為了提高系統調用的性能,引入了 syscall 指令。syscall 指令相比 int 0x80 指令,減少了一些不必要的操作,使得系統調用的執行更加高效。在使用 syscall 指令時,系統調用號被存放在 rax 寄存器中,參數則通過 rdi、rsi、rdx 等寄存器傳遞。這種方式在一定程度上簡化了參數傳遞過程,提高了系統調用的執行效率 。
從 int 0x80 到 syscall 指令的演變,體現了 x86 架構在系統調用實現上不斷追求性能優化的過程。雖然具體的實現細節在不同的內核版本和架構下可能會有所差異,但總體上都是圍繞著如何更高效、更安全地實現用戶程序與內核之間的通信這一核心目標展開的。無論是早期的 int 0x80 指令,還是后來的 syscall 指令,它們都在 x86 架構的系統調用實現中發揮了重要作用,為 x86 架構下的 Linux 系統提供了穩定、高效的系統調用支持 。
4.2 ARM架構
ARM 架構下系統調用的實現與 x86 架構有著顯著的不同,展現出自身獨特的特點。
在 ARM 架構中,系統調用主要通過 SWI(Software Interrupt)指令來觸發,在 Thumb 指令集下則使用 SVC(Supervisor Call)指令,它們的功能類似,都是用于實現從用戶態到內核態的切換,以執行系統調用。當用戶程序需要發起系統調用時,會執行 SWI 或 SVC 指令,這就如同按下了一個特殊的 “開關”,觸發系統進入內核態進行系統調用的處理 。
與 x86 架構不同,在 ARM 架構中,系統調用號通常被存放在 r7 寄存器中。在發起系統調用之前,用戶程序會將對應的系統調用號存入 r7 寄存器,同時,參數會被放入 r0 - r6 等寄存器中進行傳遞。在執行一個讀取文件的系統調用時,會將讀取文件系統調用的系統調用號存入 r7 寄存器,文件描述符、數據緩沖區指針、數據長度等參數可能分別存放在 r0、r1、r2 等寄存器中 。
系統調用號的定義位置也與 x86 架構不同。在 ARM 架構中,系統調用號的定義通常位于arch/arm/include/asm/unistd.h文件中。在這個文件中,通過一系列的宏定義來為每個系統調用分配唯一的系統調用號。這些宏定義就像是一個編號分配表,明確地規定了每個系統調用對應的編號,使得內核能夠根據系統調用號準確地識別用戶程序請求的系統調用類型 。
在處理流程上,當 SWI 或 SVC 指令被執行后,CPU 會跳轉到相應的中斷處理程序。這個中斷處理程序會根據 r7 寄存器中的系統調用號,在系統調用表中查找對應的處理函數。與 x86 架構類似,系統調用表中存儲著各個系統調用處理函數的指針,通過系統調用號作為索引,能夠快速找到對應的處理函數并執行。在處理函數執行完畢后,會將結果返回給用戶程序,同時恢復用戶態的執行環境,使程序繼續執行 。
ARM 架構下系統調用的實現方式是基于其自身的硬件特點和設計理念而形成的。通過 SWI 或 SVC 指令觸發系統調用,以及獨特的系統調用號定義和參數傳遞方式,使得 ARM 架構在實現系統調用時,能夠充分發揮其低功耗、高性能的優勢,滿足嵌入式系統等應用場景對于系統調用高效、穩定執行的需求 。
五、Linux下系統調用的三種方法
5.1通過 glibc 提供的庫函數
glibc 是 Linux 下使用的開源的標準 C 庫,它是 GNU 發布的 libc 庫,即運行時庫。glibc 為程序員提供豐富的 API(Application Programming Interface),除了例如字符串處理、數學運算等用戶態服務之外,最重要的是封裝了操作系統提供的系統服務,即系統調用的封裝。那么glibc提供的系統調用API與內核特定的系統調用之間的關系是什么呢?
通常情況,每個特定的系統調用對應了至少一個 glibc 封裝的庫函數,如系統提供的打開文件系統調用 sys_open 對應的是 glibc 中的 open 函數;
其次,glibc 一個單獨的 API 可能調用多個系統調用,如 glibc 提供的 printf 函數就會調用如 sys_open、sys_mmap、sys_write、sys_close 等等系統調用;
另外,多個 API 也可能只對應同一個系統調用,如glibc 下實現的 malloc、calloc、free 等函數用來分配和釋放內存,都利用了內核的 sys_brk 的系統調用。
舉例來說,我們通過 glibc 提供的chmod 函數來改變文件 etc/passwd 的屬性為 444:
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#include <stdio.h>
int main()
{
int rc;
rc = chmod("/etc/passwd", 0444);
if (rc == -1)
fprintf(stderr, "chmod failed, errno = %d\n", errno);
else
printf("chmod success!\n");
return 0;
}在普通用戶下編譯運用,輸出結果為:
chmod failed, errno = 1上面系統調用返回的值為-1,說明系統調用失敗,錯誤碼為1,在 /usr/include/asm-generic/errno-base.h 文件中有如下錯誤代碼說明:
#define EPERM 1 /* Operation not permitted */即無權限進行該操作,我們以普通用戶權限是無法修改 /etc/passwd 文件的屬性的,結果正確。
5.2使用 syscall 直接調用
使用上面的方法有很多好處,首先你無須知道更多的細節,如 chmod 系統調用號,你只需了解 glibc 提供的 API 的原型;其次,該方法具有更好的移植性,你可以很輕松將該程序移植到其他平臺,或者將 glibc 庫換成其它庫,程序只需做少量改動。
但有點不足是,如果 glibc 沒有封裝某個內核提供的系統調用時,我就沒辦法通過上面的方法來調用該系統調用。如我自己通過編譯內核增加了一個系統調用,這時 glibc 不可能有你新增系統調用的封裝 API,此時我們可以利用 glibc 提供的syscall 函數直接調用。該函數定義在 unistd.h 頭文件中,函數原型如下:
long int syscall (long int sysno, ...)sysno 是系統調用號,每個系統調用都有唯一的系統調用號來標識。在 sys/syscall.h 中有所有可能的系統調用號的宏定義。
... 為剩余可變長的參數,為系統調用所帶的參數,根據系統調用的不同,可帶0~5個不等的參數,如果超過特定系統調用能帶的參數,多余的參數被忽略。
返回值 該函數返回值為特定系統調用的返回值,在系統調用成功之后你可以將該返回值轉化為特定的類型,如果系統調用失敗則返回 -1,錯誤代碼存放在 errno 中。
還以上面修改 /etc/passwd 文件的屬性為例,這次使用 syscall 直接調用:
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <errno.h>
int main()
{
int rc;
rc = syscall(SYS_chmod, "/etc/passwd", 0444);
if (rc == -1)
fprintf(stderr, "chmod failed, errno = %d\n", errno);
else
printf("chmod succeess!\n");
return 0;
}在普通用戶下編譯執行,輸出的結果與上例相同。
5.3通過 int 指令陷入
如果我們知道系統調用的整個過程的話,應該就能知道用戶態程序通過軟中斷指令int 0x80 來陷入內核態(在Intel Pentium II 又引入了sysenter指令),參數的傳遞是通過寄存器,eax 傳遞的是系統調用號,ebx、ecx、edx、esi和edi 來依次傳遞最多五個參數,當系統調用返回時,返回值存放在 eax 中。
仍然以上面的修改文件屬性為例,將調用系統調用那段寫成內聯匯編代碼:
#include <stdio.h>
#include <sys/types.h>
#include <sys/syscall.h>
#include <errno.h>
int main()
{
long rc;
char *file_name = "/etc/passwd";
unsigned short mode = 0444;
asm(
"int $0x80"
: "=a" (rc)
: "0" (SYS_chmod), "b" ((long)file_name), "c" ((long)mode)
);
if ((unsigned long)rc >= (unsigned long)-132) {
errno = -rc;
rc = -1;
}
if (rc == -1)
fprintf(stderr, "chmode failed, errno = %d\n", errno);
else
printf("success!\n");
return 0;
}如果 eax 寄存器存放的返回值(存放在變量 rc 中)在 -1~-132 之間,就必須要解釋為出錯碼(在/usr/include/asm-generic/errno.h 文件中定義的最大出錯碼為 132),這時,將錯誤碼寫入 errno 中,置系統調用返回值為 -1;否則返回的是 eax 中的值。
上面程序在 32位Linux下以普通用戶權限編譯運行結果與前面兩個相同!
六、系統調用的應用場景與實例分析
6.1Linux下系統調用的實現
Linux下的系統調用是通過0x80實現的,但是我們知道操作系統會有多個系統調用(Linux下有319個系統調用),而對于同一個中斷號是如何處理多個不同的系統調用的?最簡單的方式是對于不同的系統調用采用不同的中斷號,但是中斷號明顯是一種稀缺資源,Linux顯然不會這么做;還有一個問題就是系統調用是需要提供參數,并且具有返回值的,這些參數又是怎么傳遞的?也就是說,對于系統調用我們要搞清楚兩點:
- 1. 系統調用的函數名稱轉換。
- 2. 系統調用的參數傳遞。
首先看第一個問題。實際上,Linux中處理系統調用的方式與中斷類似。每個系統調用都有相應的系統調用號作為唯一的標識,內核維護一張系統調用表,表中的元素是系統調用函數的起始地址,而系統調用號就是系統調用在調用表的偏移量。在進行系統調用是只要指定對應的系統調用號,就可以明確的要調用哪個系統調用,這就完成了系統調用的函數名稱的轉換。舉例來說,Linux中fork的調用號是2(具體定義,在我的計算機上是在/usr/include/asm/unistd_32.h,可以通過find / -name unistd_32.h -print查找)
[cpp] view plain copy
#ifndef _ASM_X86_UNISTD_32_H
#define _ASM_X86_UNISTD_32_H
/*
* This file contains the system call numbers.
*/
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5Linux中是通過寄存器%eax傳遞系統調用號,所以具體調用fork的過程是:將2存入%eax中,然后進行系統調用,偽代碼:
[plain] view plain copy
mov eax, 2
int 0x80對于參數傳遞,Linux是通過寄存器完成的。Linux最多允許向系統調用傳遞6個參數,分別依次由%ebx,%ecx,%edx,%esi,%edi和%ebp這個6個寄存器完成。比如,調用exit(1),偽代碼是:
[plain] view plain copy
mov eax, 2
mov ebx, 1
int 0x80因為exit需要一個參數1,所以這里只需要使用ebx。這6個寄存器可能已經被使用,所以在傳參前必須把當前寄存器的狀態保存下來,待系統調用返回后再恢復,這個在后面棧切換再具體講。
Linux中,在用戶態和內核態運行的進程使用的棧是不同的,分別叫做用戶棧和內核棧,兩者各自負責相應特權級別狀態下的函數調用。當進行系統調用時,進程不僅要從用戶態切換到內核態,同時也要完成棧切換,這樣處于內核態的系統調用才能在內核棧上完成調用。系統調用返回時,還要切換回用戶棧,繼續完成用戶態下的函數調用。
寄存器%esp(棧指針,指向棧頂)所在的內存空間叫做當前棧,比如%esp在用戶空間則當前棧就是用戶棧,否則是內核棧。棧切換主要就是%esp在用戶空間和內核空間間的來回賦值。在Linux中,每個進程都有一個私有的內核棧,當從用戶棧切換到內核棧時,需完成保存%esp以及相關寄存器的值(%ebx,%ecx...)并將%esp設置成內核棧的相應值。
而從內核棧切換會用戶棧時,需要恢復用戶棧的%esp及相關寄存器的值以及保存內核棧的信息。一個問題就是用戶棧的%esp和寄存器的值保存到什么地方,以便于恢復呢?答案就是內核棧,在調用int指令機型系統調用后會把用戶棧的%esp的值及相關寄存器壓入內核棧中,系統調用通過iret指令返回,在返回之前會從內核棧彈出用戶棧的%esp和寄存器的狀態,然后進行恢復。
相信大家一定聽過說,系統調用很耗時,要盡量少用。通過上面描述系統調用的實現原理,大家也應該知道這其中的原因了。
- 第一,系統調用通過中斷實現,需要完成棧切換。
- 第二,使用寄存器傳參,這需要額外的保存和恢復的過程。
6.2文件操作相關系統調用
在 Linux 系統中,文件操作是日常使用和開發中極為常見的任務,而 open、read、write、close 等系統調用則是實現文件操作的核心工具。
open 系統調用用于打開或創建一個文件,它的函數原型為int open(const char *pathname, int flags, mode_t mode);。其中,pathname是要打開或創建的文件的路徑名;flags參數用于指定文件的打開方式,比如O_RDONLY表示以只讀方式打開,O_WRONLY表示以只寫方式打開,O_RDWR則表示以讀寫方式打開,還有一些可選的標志位,如O_CREAT表示如果文件不存在則創建新文件,O_APPEND表示以追加方式寫入文件等;mode參數在創建新文件時用于指定文件的訪問權限,如S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH表示文件所有者具有讀寫權限,同組用戶和其他用戶具有讀權限 。
read 系統調用用于從文件中讀取數據,函數原型是ssize_t read(int fd, void *buf, size_t count);,fd是文件描述符,它是 open 系統調用成功返回的一個非負整數,用于標識打開的文件;buf是用于存儲讀取數據的緩沖區指針;count表示期望讀取的字節數,該函數返回實際讀取到的字節數 。
write 系統調用則用于向文件中寫入數據,其函數原型為ssize_t write(int fd, const void *buf, size_t count);,參數含義與 read 類似,fd為文件描述符,buf是要寫入數據的緩沖區指針,count是要寫入的字節數,返回值是實際寫入的字節數 。
close 系統調用用于關閉一個打開的文件,函數原型為int close(int fd);,fd為要關閉的文件描述符,關閉成功返回 0,失敗返回 - 1 。
以下是一個簡單的 C 語言代碼示例,展示了如何使用這些系統調用實現文件的讀取和寫入操作:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#define BUFFER_SIZE 1024
int main() {
int source_fd, destination_fd;
ssize_t bytes_read, bytes_written;
char buffer[BUFFER_SIZE];
// 打開源文件,以只讀方式
source_fd = open("source.txt", O_RDONLY);
if (source_fd == -1) {
perror("無法打開源文件");
return 1;
}
// 創建目標文件,以讀寫方式,如果文件不存在則創建,權限設置為所有者可讀可寫,其他用戶可讀
destination_fd = open("destination.txt", O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if (destination_fd == -1) {
perror("無法創建目標文件");
close(source_fd);
return 1;
}
// 從源文件讀取數據并寫入目標文件
while ((bytes_read = read(source_fd, buffer, BUFFER_SIZE)) > 0) {
bytes_written = write(destination_fd, buffer, bytes_read);
if (bytes_written != bytes_read) {
perror("寫入目標文件失敗");
close(source_fd);
close(destination_fd);
return 1;
}
}
if (bytes_read == -1) {
perror("讀取源文件失敗");
}
// 關閉文件
close(source_fd);
close(destination_fd);
return 0;
}在這個示例中,首先使用 open 系統調用以只讀方式打開名為source.txt的源文件,如果打開失敗,通過perror函數輸出錯誤信息并返回 1。接著,使用 open 系統調用以讀寫方式創建名為destination.txt的目標文件,如果文件已存在則截斷文件內容,如果創建失敗同樣輸出錯誤信息并關閉已打開的源文件后返回 1 。
然后,通過一個循環,使用 read 系統調用從源文件中讀取數據到緩沖區buffer中,每次最多讀取BUFFER_SIZE個字節。只要讀取到的數據長度大于 0,就使用 write 系統調用將緩沖區中的數據寫入目標文件。如果寫入的字節數與讀取的字節數不一致,說明寫入失敗,輸出錯誤信息并關閉兩個文件后返回 1 。
如果在讀取過程中bytes_read等于 - 1,說明讀取失敗,輸出錯誤信息。最后,使用 close 系統調用分別關閉源文件和目標文件,完成文件操作 。
通過這個示例,我們可以清晰地看到 open、read、write、close 系統調用在文件讀寫操作中的具體應用和執行流程,它們相互配合,實現了高效、準確的文件數據傳輸和管理 。
6.3進程管理相關系統調用
在 Linux 系統中,進程管理是操作系統的核心功能之一,fork、exec、wait 等系統調用在進程的創建、執行和等待過程中發揮著關鍵作用。
fork 系統調用用于創建一個新的進程,稱為子進程,它的函數原型為pid_t fork(void);。調用 fork 后,系統會創建一個與原進程(父進程)幾乎完全相同的子進程,子進程復制了父進程的代碼段、數據段、堆棧段等資源。但父子進程也有一些不同之處,它們擁有不同的進程 ID(PID),通過getpid()函數可以獲取當前進程的 PID,通過getppid()函數可以獲取父進程的 PID 。fork 函數的返回值非常特殊,在父進程中,返回值是新創建子進程的 PID;在子進程中,返回值為 0;如果創建子進程失敗,返回值為 - 1 。
exec 系統調用并不是一個單獨的函數,而是一組函數,如execl、execv、execle、execve等,它們的主要作用是在當前進程中啟動另一個程序。當進程調用 exec 函數時,會用新的程序替換當前進程的正文、數據、堆和棧段,也就是說,當前進程會被新的程序完全取代,從新程序的main函數開始執行。由于 exec 并不創建新進程,所以前后的進程 ID 并未改變 。
wait 系統調用用于等待子進程的結束,并獲取子進程的退出狀態,函數原型為pid_t wait(int *status);。status是一個指向整數的指針,用于存儲子進程的退出狀態信息。調用 wait 后,父進程會阻塞,直到有一個子進程結束,此時 wait 返回結束子進程的 PID,并將子進程的退出狀態存儲在status指向的變量中 。
下面通過一個簡單的代碼示例來說明進程創建和父子進程的執行流程:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
int main() {
pid_t pid;
int status;
// 創建子進程
pid = fork();
if (pid == -1) {
perror("fork失敗");
exit(1);
} else if (pid == 0) {
// 子進程執行的代碼
printf("我是子進程,我的PID是 %d,父進程的PID是 %d\n", getpid(), getppid());
// 子進程執行另一個程序,這里以執行ls命令為例
execl("/bin/ls", "ls", "-l", NULL);
perror("execl失敗");
exit(1);
} else {
// 父進程執行的代碼
printf("我是父進程,我的PID是 %d,子進程的PID是 %d\n", getpid(), pid);
// 父進程等待子進程結束
wait(&status);
printf("子進程已結束,退出狀態為 %d\n", WEXITSTATUS(status));
}
return 0;
}在這個示例中,首先調用 fork 系統調用創建子進程。如果 fork 返回 - 1,說明創建子進程失敗,通過perror函數輸出錯誤信息并調用exit函數退出程序 。
如果 fork 返回 0,說明當前是子進程,子進程打印自己的 PID 和父進程的 PID,然后調用execl函數執行/bin/ls -l命令,列出當前目錄下的文件詳細信息。如果execl執行失敗,同樣輸出錯誤信息并退出 。
如果 fork 返回一個大于 0 的值,說明當前是父進程,父進程打印自己的 PID 和子進程的 PID,然后調用 wait 系統調用等待子進程結束。當子進程結束后,wait 返回,父進程獲取子進程的退出狀態,并打印子進程已結束以及其退出狀態 。
通過這個示例,我們可以清楚地看到 fork、exec、wait 系統調用在進程管理中的協同工作,fork 用于創建新進程,exec 用于在子進程中執行新程序,wait 用于父進程等待子進程結束并獲取其退出狀態,它們共同構成了 Linux 系統強大的進程管理機制 。