LLM 強化學習的開源新力量:字節跳動 DAPO 算法

大家好,我是肆〇柒。看到一款開源的強化學習算法,這是由字節跳動、清華大學 AIR 研究所等機構聯合推出的開源強化學習算法 ——DAPO。目前在 AI 領域,大型語言模型(LLM)的推理能力正以前所未有的速度發展,而強化學習(RL)作為其核心優化技術,扮演著至關重要的角色。然而,現有頂級推理模型的技術細節往往難以獲取,這使得廣大研究人員和開發者在復現和進一步探索時面臨重重困難。在這樣的背景下,研究人員提出了 DAPO 并開源。下面一起了解下。
LLM 推理能力的演進
在早期,LLM 的推理能力主要集中在簡單的邏輯推理和事實性問題的回答上。例如,對于一些基于常識的問題,如“太陽從哪個方向升起?”模型能夠給出準確的答案。然而,隨著技術的發展,LLM 開始能夠處理更復雜的任務,如解決數學問題和編寫代碼。這一進步的關鍵在于測試時擴展(Test-time scaling)技術的引入,尤其是 Chain-of-Thought(思考鏈)方式的廣泛應用。
思考鏈技術通過模擬人類的逐步思考過程,使 LLM 能夠進行更復雜的推理。例如,在解決數學問題時,模型會逐步分解問題,逐步求解,最終得出答案。這種技術不僅提高了模型的準確性,還使其能夠處理更復雜的任務。例如,在解決一個復雜的幾何問題時,模型會先列出已知條件,然后逐步推導出未知條件,最終得出答案。
然而,在不同的推理場景下,LLM 的表現仍存在差異。例如,在處理長推理鏈條(Long CoT)任務時,模型往往面臨更大的挑戰。這是因為長 CoT 任務需要模型在生成過程中保持邏輯連貫性和準確性,同時避免因生成過長文本而引入噪聲。例如,在解決一個復雜的數學競賽題目時,模型可能需要生成長達數千個 token 的推理過程,這不僅對模型的生成能力提出了挑戰,還對模型的邏輯連貫性提出了更高的要求。
強化學習在 LLM 中的應用挑戰
強化學習(RL)在提升 LLM 推理能力方面具有重要作用,但同時也面臨著諸多挑戰。例如,熵崩潰(Entropy Collapse)是一個常見問題,即模型在訓練過程中逐漸失去探索能力,生成的文本變得單一和確定性。這不僅限制了模型的探索能力,還可能導致模型在面對復雜任務時無法找到最優解。
以熵崩潰為例,當模型在訓練過程中過于依賴某些高頻詞匯或模式時,會導致生成的文本缺乏多樣性。例如,在解決一個復雜的數學問題時,模型可能會反復生成相同的解題步驟,而無法探索其他可能的解題路徑。這不僅限制了模型的探索能力,還可能導致模型在面對復雜任務時無法找到最優解。
此外,獎勵噪聲(Reward Noise)和訓練不穩定(Training Instability)等問題也嚴重影響了模型的訓練效果。例如,在訓練過程中,模型可能會因為獎勵信號的不穩定性而出現訓練不穩定的情況。這不僅影響了模型的訓練效果,還可能導致模型在訓練過程中出現性能波動。
現有的強化學習算法,如近端策略優化(PPO)和組相對策略優化(GRPO),在處理長 CoT 任務時也存在局限性。例如,PPO 在處理長文本生成時容易出現梯度消失問題,而 GRPO 則在獎勵分配上存在不足。這不僅影響了模型的訓練效果,還限制了模型在長 CoT 任務中的表現。
DAPO 算法簡介
算法核心架構
DAPO 算法的核心框架在傳統強化學習算法的基礎上進行了多項改進。其基本輸入是問題-答案對,輸出是經過優化的策略模型。DAPO 的核心計算流程包括采樣、獎勵計算、優勢函數估計和策略更新。
與 GRPO 相比,DAPO 在優勢函數計算和策略更新方式上進行了關鍵改進。例如,DAPO 引入了解耦的裁剪策略(Clip-Higher),通過分別設置上下限裁剪范圍(εlow 和 εhigh),有效提升了策略的多樣性。此外,DAPO 還引入了動態采樣機制,通過動態調整采樣數量,確保每個樣本都攜帶有效的梯度信息。
四大核心技術
Clip-Higher 策略是 DAPO 的一項重要創新。通過解耦上下限裁剪范圍,該策略為低概率 token 的概率提升提供了更多空間。當 εlow 設置為 0.2,εhigh 設置為 0.28 時,模型在訓練過程中能夠更好地平衡探索和利用。
從數學公式來看,Clip-Higher 的策略更新公式如下:

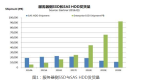
通過實驗數據可以看出,使用 Clip-Higher 策略后,模型的熵顯著增加,生成的樣本更加多樣化。例如,在 AIME 2024 的測試中,使用 Clip-Higher 的模型在訓練初期就能生成多種不同的解題路徑。這不僅提高了模型的探索能力,還為模型在復雜任務中的表現提供了更多的可能性。

在應用Clip-Higher策略之前和之后,在AIME測試集上的準確率以及在強化學習訓練過程中actor模型生成概率的熵
動態采樣機制解決了現有 RL 算法中因部分樣本獎勵值固定導致梯度消失的問題。在訓練過程中,DAPO 會動態調整采樣數量,確保每個樣本都攜帶有效的梯度信息。
DAPO 在采樣時會先篩選出那些獎勵值為 0 或 1 的樣本,然后從剩余樣本中進行采樣。這種策略在提高樣本效率的同時,還穩定了梯度更新。

平均上裁剪概率以及準確度為1的提示的比率
篩選的具體算法步驟如下:
1. 對于每個批次的樣本,計算每個樣本的獎勵值。
2. 篩選出獎勵值為 0 或 1 的樣本。
3. 從剩余樣本中進行采樣,直到采樣數量達到預設的閾值。
4. 根據訓練過程中的情況,動態調整采樣數量和篩選條件。
實驗數據顯示,使用動態采樣機制后,模型的訓練收斂速度明顯加快。例如,在 AIME 2024 的測試中,使用動態采樣的模型在相同訓練步驟下,性能比未使用該機制的模型高出 10%。

在基線設置中應用動態采樣前后的訓練進度
Token 級策略梯度損失(Token-level Policy Gradient Loss)
在長 CoT 推理場景下,傳統的樣本級損失計算方式存在弊端。例如,對于長序列樣本,關鍵 token 的更新可能不足,導致模型生成低質量的長文本。
DAPO 引入了 Token 級策略梯度損失,使每個 token 的更新更精準地依賴其對獎勵的貢獻。具體公式如下:

這種損失計算方式使長序列中的每個 token 都能得到有效的更新,從而提高了模型生成文本的質量。

actor模型的概率分布的熵,以及響應長度的變化
過長獎勵塑性(Overlong Reward Shaping)
在 RL 訓練中,截斷樣本可能引入獎勵噪聲,誤導模型。DAPO 引入了過長過濾(Overlong Filtering)和軟過長懲罰(Soft Overlong Punishment)兩種方法來解決這一問題。
過長過濾會忽略截斷樣本的損失,而軟過長懲罰則會根據響應長度動態調整懲罰力度。例如,當響應長度超過預設的最大值時,模型會受到懲罰,從而引導模型生成長度適中的推理過程。軟過長懲罰的具體公式如下:

實驗數據顯示,使用過長獎勵塑性后,模型在 AIME 2024 的測試中表現更加穩定,性能提升了 5%。

在應用“過長獎勵塑形策略”之前和之后,actor模型在AIME上的準確率以及其生成概率的熵
實驗驗證與成果
實驗設置
在 DAPO 的實驗中,研究人員精心選擇了預訓練模型、訓練框架、優化器以及超參數,以確保算法能夠在復雜的推理任務中表現出色。實驗采用的預訓練模型是 Qwen2.5-32B,這是一個具有 320 億參數的大型語言模型,以其強大的語言生成能力而聞名。訓練框架基于 verl,一個高效且靈活的強化學習框架,能夠支持大規模的訓練任務。優化器選擇了 AdamW,這是一種廣泛使用的優化算法,以其良好的收斂性能和穩定性而受到青睞。學習率設置為 1×10^-6,并在前 20 個 rollout 步驟中進行線性 warm-up,以確保模型在訓練初期能夠平穩地更新參數。
為了評估模型的推理能力,研究人員構建了 DAPO-Math-17K 數據集,這是一個包含 17,000 個數學問題的數據集,每個問題都配有整數形式的答案。這個數據集的構建過程非常嚴謹,數據來源包括 AoPS 網站和官方競賽主頁。通過對原始問題答案的轉換,研究人員確保了數據集能夠適配規則獎勵模型,從而為模型提供了準確的獎勵信號。
關鍵實驗結果
DAPO 在 AIME 2024 競賽中的表現尤為引人注目。它在該競賽中取得了 50 分的成績,這一成績不僅超越了先前的頂級模型 DeepSeek-R1-Zero-Qwen-32B(47 分),而且僅用了 50% 的訓練步驟就達到了這一成績。這一結果充分展示了 DAPO 在訓練效率和效果上的顯著優勢。

應用于DAPO的漸進技術的主要成果

在Qwen2.5-32B基礎模型上,DAPO的2024年AIME分數超過了之前使用50%訓練步數的最先進水平DeepSeekR1-Zero-Qwen-32B。X軸表示梯度更新步數
從學習曲線來看,DAPO 在訓練過程中展現出了快速的性能提升。在訓練初期,模型的準確率迅速上升,這得益于 DAPO 算法在策略更新和獎勵分配上的創新設計。隨著訓練的進行,模型的準確率逐漸趨于穩定,但始終保持著較高的水平。
通過表格形式的分析,我們可以看到 DAPO 的每個技術組件都對模型性能的提升做出了顯著貢獻。例如,Clip-Higher 策略為模型帶來了 8 分的性能提升,動態采樣機制帶來了 6 分的提升,Token 級策略梯度損失帶來了 4 分的提升,而過長獎勵塑性則帶來了 2 分的提升。這些技術組件的協同作用,使得 DAPO 在復雜的推理任務中表現出色。
在訓練過程中,DAPO 的各項指標也展現出了良好的趨勢。生成文本的長度隨著訓練的進行而穩步增加,這表明模型在不斷探索更復雜的推理路徑。獎勵分數的穩定提升則表明模型在逐漸適應訓練分布,能夠生成更符合要求的推理過程。生成概率均值和熵的變化趨勢也反映了模型在訓練過程中的穩定性和多樣性。

響應長度、獎勵分數、生成熵以及DAPO平均概率的度量曲線,展示了強化學習訓練的動態過程,并作為關鍵的監控指標來識別潛在問題
模型推理動態演變
在強化學習訓練過程中,DAPO 模型的推理模式發生了顯著的動態變化。以具體的數學問題求解為例,模型從初期缺乏反思行為,逐漸發展到后期能夠主動進行步驟驗證與回溯。這種轉變不僅提升了模型的推理準確性,還展示了 DAPO 算法在激發和塑造模型推理能力方面的強大作用。

強化學習中反思行為的出現
例如,在解決一個復雜的幾何問題時,模型在訓練初期可能只是簡單地列出已知條件和目標,而沒有進行深入的分析和驗證。然而,隨著訓練的進行,模型開始在推理過程中加入更多的驗證步驟,如檢查中間結果的合理性、回溯錯誤的推理路徑等。這種動態演變不僅提高了模型的推理能力,還為研究人員提供了深入理解模型學習過程的窗口。
從生成文本長度、獎勵分數、生成概率均值與熵等指標的變化趨勢來看,這些動態變化反映了模型學習狀態與性能提升的軌跡。生成文本長度的增加表明模型能夠生成更復雜的推理過程,獎勵分數的提升則表明模型的推理結果更加符合要求。生成概率均值和熵的變化則反映了模型在訓練過程中的穩定性和多樣性,這些指標的健康變化為模型的性能提升提供了有力支持。

一種反思性行為出現的例子
開源生態構建與實踐
開源內容全景概覽
DAPO 開源項目為研究人員和開發者提供了豐富的資源,包括算法代碼、訓練基礎設施以及數據集。這些資源的開源,不僅降低了參與 LLM 強化學習研究的門檻,還為社區的協作和創新提供了堅實的基礎。
開源項目基于 verl 框架實現,具有高效、靈活的特點。項目結構清晰,關鍵模塊如算法實現、數據處理腳本等都易于定位和使用。這使得研究人員可以快速上手,進行算法的修改和擴展。
環境搭建與模型推理示例
為了幫助研究人員和開發者快速搭建實驗環境,DAPO 提供了詳細的環境配置指南。推薦使用 conda 創建獨立的 Python 環境,并安裝所需的依賴包。在安裝過程中,需要注意一些常見的問題,如依賴包版本不匹配等,并根據實際情況進行調整。
模型推理代碼示例也提供了詳細的說明,關鍵參數如溫度值、top_p 等的作用和設置建議都得到了清晰的解釋。通過這些示例,研究人員可以在本地順利運行模型,并對模型的推理過程和結果進行直觀的感受。
以具體的數學問題求解為例,模型的輸入輸出示例展示了模型生成推理過程的特點和優勢。例如,在解決一個復雜的代數問題時,模型不僅能夠生成正確的答案,還能詳細地列出解題步驟,展示其推理過程的邏輯性和連貫性。
AIME 2024 評估部署
為了評估 DAPO 模型在 AIME 2024 上的表現,研究人員提供了詳細的部署指南。利用 Ray Serve 和 vLLM,研究人員可以方便地部署模型,并進行高效的評估。
從 Hugging Face 加載模型和從本地加載模型的方法都有詳細的說明,評估腳本的參數說明和運行示例也提供了清晰的指導。通過這些指南,研究人員可以準確地復現評估過程,并根據評估結果分析模型的優勢和改進空間。
評估指標的計算方式和結果解讀方法也得到了詳細的介紹。例如,準確率的計算不僅考慮了最終答案的正確性,還考慮了解題步驟的合理性。通過這些詳細的評估指標,研究人員可以全面地了解模型的性能。
訓練復現路徑指引
DAPO 提供了完整的訓練復現腳本,包括簡化版和完整版。這些腳本的功能、適用場景和運行前提條件都得到了詳細的說明。在不同版本的 verl 下,訓練過程的驗證情況也得到了清晰的闡述,為研究人員順利復現訓練過程提供了可靠的保障。
研究人員還可以利用開源的數據集和訓練代碼,開展定制化的訓練實驗。例如,通過加載和預處理 DAPO-Math-17k 數據集,研究人員可以根據自己的需求配置訓練參數,探索個性化的 LLM 強化學習解決方案。
代碼示例展示了如何加載和預處理數據集,以及如何配置訓練參數以適應不同的實驗需求。通過這些示例,研究人員可以更好地理解訓練過程,并進行有效的實驗設計。
以上項目可見參考資料處。
技術影響與展望
對 LLM 強化學習領域的推動作用
DAPO 算法在提升 LLM 推理能力方面,不僅拓展了模型可解決任務的邊界,還加速了推理模型的研發迭代進程。DAPO 對現有 LLM 強化學習技術體系的補充和完善,為后續研究方向提供了重要的啟示。
結合當前 LLM 的發展趨勢,DAPO 為構建更智能、更可靠的推理模型奠定了基礎。它推動了自然語言處理領域在復雜任務求解方面邁向新的高度,使 LLM 能夠在更多的領域發揮重要作用。
潛在應用場景拓展
DAPO 在多個領域的應用前景廣闊。在數學教育領域,它可以作為個性化數學問題求解輔導工具,幫助學生更好地理解和解決復雜的數學問題。在代碼生成與優化領域,DAPO 可以自動生成復雜的算法,并對代碼邏輯進行驗證,提高開發效率和代碼質量。
此外,DAPO 在科學研究輔助和商業智能決策方面也具有巨大的潛力。例如,在物理模擬中,DAPO 可以進行參數優化,提高模擬的準確性和效率。在市場趨勢分析中,DAPO 可以根據歷史數據預測未來的市場變化,為決策提供支持。
基于 DAPO 算法的現有成果和局限,未來的研究方向包括進一步優化長 CoT 推理中的獎勵建模、增強模型對不同類型推理任務的泛化能力、探索更高效的采樣策略以降低計算成本等。跨學科協作在推動 LLM 強化學習發展中具有重要意義,研究人員可以結合數學、物理學等領域的專業知識,共同攻克 LLM 推理面臨的深層次挑戰,開拓創新的研究路徑。
算法局限性
盡管 DAPO 算法取得了顯著的成果,但它在不同場景下仍存在一定的局限性。例如,在處理極長推理鏈條任務時,可能會面臨計算資源瓶頸。當推理鏈條長度超過模型能夠有效處理的范圍時,模型的性能可能會顯著下降。實驗數據顯示,在處理長度超過 20,000 token 的任務時,模型的準確率下降了約 15%。此外,對特定領域知識的深度依賴可能導致模型在泛化到其他領域時遇到困難。例如,在數學競賽任務中表現出色的模型,在處理化學分子結構預測任務時,可能需要額外的領域知識適配。
數據質量的要求和模型訓練的穩定性也是需要進一步研究和改進的方向。例如,數據集中的噪聲數據可能會對模型的訓練效果產生負面影響,而訓練過程中的參數調整不當也可能導致模型性能波動。
總結與感想
DAPO 算法的出現為 LLM 強化學習領域帶來了新的活力。它不僅在技術上取得了突破,還通過開源的方式,為研究人員和開發者提供了寶貴的資源和實踐指南。通過本文的詳細解析,我們可以看到 DAPO 在提升 LLM 推理能力方面的顯著優勢,以及其在多個領域的廣泛應用前景。
DAPO 的技術創新點,如 Clip-Higher 策略、動態采樣機制、Token 級策略梯度損失和過長獎勵塑性等,不僅有效解決了現有強化學習算法在長 CoT 推理場景下的諸多問題,還顯著提升了模型的訓練效率和性能。這些技術的引入,使得 DAPO 能夠在更少的訓練步驟內達到更高的準確率,為 LLM 強化學習的發展提供了新的思路和方法。
實驗結果進一步驗證了 DAPO 的有效性。在 AIME 2024 競賽中,DAPO 基于 Qwen2.5-32B 模型取得了 50 分的成績,超越了先前的頂級模型,并且僅用了 50% 的訓練步驟。這一成果不僅展示了 DAPO 在推理任務中的強大能力,也證明了其在訓練效率和效果上的顯著優勢。通過詳細的實驗數據分析,我們可以看到 DAPO 的各項指標在訓練過程中表現良好,生成文本長度、獎勵分數、生成概率均值與熵等指標的變化趨勢,都反映了模型學習狀態與性能提升的軌跡。
DAPO 算法在推動 LLM 強化學習領域的發展方面具有重要意義。它不僅為構建更智能、更可靠的推理模型奠定了基礎,還為自然語言處理領域在復雜任務求解方面的發展提供了新的方向。DAPO 在數學教育、代碼生成與優化、科學研究輔助和商業智能決策等領域的潛在應用前景廣闊。
然而,DAPO 算法也存在一定的局限性。在處理極長推理鏈條任務時,可能會面臨計算資源瓶頸;對特定領域知識的深度依賴可能導致模型在泛化到其他領域時遇到困難。此外,數據質量的要求和模型訓練的穩定性也是需要進一步研究和改進的方向。未來的研究可以聚焦于進一步優化獎勵建模、增強模型泛化能力、探索更高效的采樣策略等方面,以克服這些局限性,推動 LLM 強化學習技術的持續進步。
綜上所述,DAPO 算法的出現不僅為 LLM 強化學習領域帶來了新的技術突破,也為開源社區提供了寶貴的資源和實踐指南。我們可以看到 DAPO 在提升 LLM 推理能力、促進技術開源共享與推動應用拓展方面的關鍵作用。隨著技術的不斷發展和社區的共同努力,DAPO 有望在更多領域發揮更大的價值。
參考資料
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale
https://arxiv.org/pdf/2503.14476
- GitHub - BytedTsinghua-SIA/DAPO: An Open-source RL System from ByteDance Seed and Tsinghua AI
Rhttps://github.com/BytedTsinghua-SIA/DAPO
- DAPO: an Open-Source LLM Reinforcement Learning System at Scale