五款大模型考「山東卷」,Gemini、豆包分別獲文理第一名
果然,高考已經快被 AI 攻克了。
近日,5 款大模型參加了今年山東高考,按照傳統的文理分科方式統計:豆包 Seed 1.6-Thinking 模型以 683 分的成績拿下文科第一,Gemini 2.5 Pro 則憑借 655 分拔得理科頭籌。

測評來自字節跳動 Seed 團隊。他們集結了五款主流推理模型—— Seed 1.6-Thinking、DeepSeek-R1-0528,以及國外大模型 Gemini-2.5-Pro-0605、Claude-Sonnet-4、OpenAI-o3-high-0416,用 2025 年山東高考真題(主科全國 Ⅰ 卷 + 副科自主命題)進行全科閉卷測評,以高考 750 分制對 AI 的「應試能力」展開硬核比拼。
為確保評測的公平性,該團隊通過 API 測試,并參考高考判卷標準。選擇題和填空題由系統機判輔以人工質檢、開放題由兩位有聯考判卷經驗的重點高中老師進行匿名評估,并且后續引入了多輪質檢。
測試全程未做任何 prompting engineering,所有輸入均為高考原題,其中 DeepSeek R1 輸入為題目文本,其余模型則是題目文本和題目截圖。在總分計算上,采用 3(語數外)+3(理綜 / 文綜)的形式對 5 個模型進行排名。
從最終成績單來看,這 5 家大模型的文科成績均超 620 分,如果按照山東高考的賦分制,豆包的 683 分可以沖刺清華、北大;在理科方面,各大模型之間的分數差距則較為明顯,Gemimi 和豆包已達到保底重點 985 的水準,而 Claude 4 和 o3 還不及 600 分。
去年高考全科測評中,大模型們還只能勉強踩到一本線,面對復雜的數學、物理題目時,雖然能產出答案,但思路淺顯、推理鏈條不夠嚴密,常常給人一種「全靠蒙」的感覺。然而短短一年過去,技術更新帶來了質的飛躍,大模型展現出越來越強的邏輯推理和解決深度問題的能力。
一、語數英區分度較小,理科總分不及文科
在語、數、外等基礎學科上,參評模型整體表現優異,均已達到頂尖考生水平,彼此間的區分度相對較小。不過,o3 模型因作文跑題導致語文單科得分偏低,拖累了其總分。
而在小副科上,雖然大模型在理科方面有了長足的進步,但僅從分數上來看仍不及文科。
接下來,我們根據該技術報告中提供的評分明細,詳細解讀一下各大模型的「考試」情況。
評分明細詳見:https://bytedance.sg.larkoffice.com/sheets/QgoFs7RBjhnrUXtCBsYl0Jg2gmg
1. 語文:得作文者得天下
在此次測評中,豆包以 128 分的成績拿下語文單科第一,Gemini 以 2 分之差位列第二,DeepSeek 和 Claude 4 則分別憑借 118 分和 117 分排在第三和第四位,而 o3 則由于作文跑題以 95 分吊車尾。

整體來看,大模型在選擇題和閱讀理解題上表現優異,得分率普遍較高。這類題目本質上是對語言理解、信息抽取和基本邏輯推理能力的考查,而這正是當前大模型最擅長的領域。再加上許多分析題有一定「模板化」答案,大模型可以通過學習語料中的答題模式,形成較強的「套話生成」能力,比如「表達了作者的思鄉之情」。
此外,大模型還非常擅長名句默寫,5 款大模型全部拿到滿分。大語言模型在預訓練階段接觸了海量的古詩詞、課本內容、考試題庫等文本數據,早已「見過」并「記住」了這些常考句子,因此能夠在提示下快速準確「召回」原文。
不過在作文任務中,大模型的表現參差不齊,滿分 60 分,Gemini 能拿到 52 分,豆包拿到了 48 分,o3 卻只得到 20 分。

o3 的高考作文
究其原因,我們發現大模型寫作常停留在觀點清晰、結構完整的「合格」層面,缺乏真正深入的問題思辨和有力的邏輯推進,比如 DeepSeek 寫的作文雖然符合主題,也言之有理,但華麗詞藻下沒有精彩點,缺少溫度和共情。
格式規范方面,目前還存在一些小問題,比如豆包洋洋灑灑寫了 1800 字,超出了答題卡預留的書寫區域,o3 使用了不屬于考試規范內的作文格式,更像是模型根據主題進行分析的過程及總結。
2. 數學:去年還不及格,今年竟能考 140+
深度思考能力讓大模型的數學成績突飛猛進,相比去年普遍不及格的狀況,今年不少大模型能考到 140 分以上的高分,比如 DeepSeek R1、豆包、Gemini 就分別以 145、141、140 的分數位列前三。
這個結果與我們之前的測評比較接近,但并不完全一致,主要是解答題過程存在差別,這也說明大模型的回答存在一定隨機性。
具體來看,DeepSeek 除了在第 6 題上失分(該題全員失分)外,其余表現都挑不出毛病;豆包和 Gemini 則是在壓軸大題第三問上出了錯;Claude 4 和 o3 在倒數第二題丟了分,但 Claude 4 額外在兩道多選題上出現漏選,導致排名墊底。
其實,讓大模型們集體翻車的新一卷第 6 題并不難,主要丟分原因在于這道題目帶有方框、虛線、箭頭、漢字等元素混合的圖像信息,模型難以準確識別,這也表明大模型在圖像識別和理解上仍有提升空間。

新一卷單選第 6 題
在難度最高的壓軸大題上,眾多模型無法一次性完美解答,容易出現漏掉證明過程、推導不嚴謹的扣分情況。
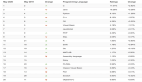
3. 英語:全員超過 140,幾乎拉不開差距
大模型做起英語卷子簡直是得心應手,五家大模型全部上 140 分,除了 Gemini 在一道選擇題上出錯外,其他主要扣分點都集中在寫作上。

上圖是基于官方測評表格數據翻譯和優化排版的圖片
有意思的是,Gemini 在分析過程中實際上已經識別出正確答案,但在后續推理中引入了無根據的假設,忽略了與上下文的關聯性,造成了最終的錯選。
至于作文題,滿分 15 分,五家大模型的得分可分為兩檔。
豆包、Gemini 和 Claude 4 是「12 分檔」,它們都完整回應了所有要求,結構清晰,語言流暢準確,內容上也都很充實。其中豆包提供了具體的接力賽例子,Gemini 給出了雙版本方案,Claude 4 更是提出了「為不同水平學生提供平等機會」這樣有深度的觀點。
o3 和 DeepSeek 為「11 分檔」。o3 雖然創意不錯,將欄目描述得很有游戲化特色,但使用了「him」等不嚴謹的代詞,影響了語言的準確性。DeepSeek 的主要問題是句式單一,重復使用「would」使得文章略顯乏味,同時結尾格式也未完全遵照題目要求。
4. 政史地強得可怕,理科讀圖題失分較多
高考文綜一向以題量大、材料多著稱,哪怕是人類考生,拿到高分也不容易。
在本次 2025 年山東文綜卷挑戰中,表現最出色的就是豆包,以 270 分的高分遙遙領先,尤其在地理(94)和歷史(92)兩個學科上,雙雙突破 90 分大關。這可能得益于豆包大模型在處理結構化資料和邏輯推演方面的優化,例如地理題中對空間關系和圖文結合的理解,歷史題中對因果鏈條和材料主旨的把握。

o3 各科得分較為均衡,雖略遜于豆包但無明顯弱項,體現出其較高的整體調優水平。Claude 4 在地理上也拿下 92 分,表現亮眼,但政治分數最低,主要失分點在于回答分析題時教材觀點關聯不足。Gemini 與 Claude 4 總分接近,沒有短板,但也缺乏突出的強項。
相比之下,DeepSeek 的成績并不理想,文綜總分僅 225 分,其中最拖后腿的就是歷史,僅為 67 分,最大的失分點是第 18 題,由于出現模型故障,沒有識別出材料,12 分全丟了。
與文科相較,大模型的理科總分并不算特別耀眼,和清北線有距離,是保底 985 的水平。Gemini 以 248 分的成績位居榜首,比第二名豆包高出 13 分,比第三名 Claude 4 則高出了整整 37 分。

測試結果
當然,這也是因為生物、化學涉及較多讀圖題, 在測評時輸入的圖片比較模糊,在一定程度上限制了多模態模型的發揮,導致失分較多。
在獲得更高清版本的高考試題圖后,Seed 團隊采用圖文交織的方式,重新對生物和化學進行了推理測試,發現豆包在生化兩科上的總分可再提升近 30 分,如此一來,理科總分就達到 676 分。這也說明,結合文本和圖片進行全模態推理可以更大程度激發模型的潛力。

圖文交織輸入示例
此外,我們還發現在物理壓軸題中,多個模型發生使用超綱知識解答的情況,但因為測試全程未做任何 prompting engineering,模型可能并不知道有解題方法限制。
二、一年提100多分,大模型何以從學渣變學霸?
去年,有科技媒體組織大模型參加了河南高考,文科最高成績為 562 分,理科則為 469.5 分。短短一年時間,大模型在文理科成績上均提高了 100 多分。
多款大模型之所以能在今年的山東高考中表現不凡,自然離不開其在推理能力和多模態處理方面持續不斷的技術創新與深度優化。而這種技術演進,在 Gemini、OpenAI 系列模型和豆包等「考生」中體現得尤為明顯。
今年 3 月,谷歌推出了 Gemini 2.5 Pro。它能在輸出前通過思維鏈進行深度推理,顯著提升數學、科學與代碼推理水平,并在多項 benchmark 中取得領先成績?。同時,它能夠理解海量數據集,并處理來自不同信息源(包括文本、音頻、圖像、視頻,甚至整個代碼庫)的復雜問題。
OpenAI 的 o3 是 OpenAI 最強大的推理模型,可以在響應之前進行更長時間的思考,并首次將圖像融入其思維鏈中,通過使用工具轉換用戶上傳的圖像,使其能夠進行裁剪、放大和旋轉等簡單的圖像處理技術,更重要的是,這些功能是原生的,無需依賴單獨的專用模型。這就意味著,模型在面對復雜數學、科學、編程任務時具備更像人類的分步思考能力,還能理解圖像,可以在各種圖文題和復雜題目場景下調動更全面感知與推演能力。
豆包大模型則在半個月前宣布了 1.6 系列的上新,Seed-1.6 模型采用了多模態能力融合的預訓練策略,將其分為純文本預訓練、多模態混合持續訓練(Multimodal Mixed Continual Training, MMCT)、長上下文持續訓練(Long-context Continual Training, LongCT)三個階段。
這不僅強化了文本理解,還引入了視覺模態,能對圖表、圖像等信息進行解析,提供更加全面的推理。而且它支持高達 256K 的上下文長度,可以處理更為復雜的問題。
基于高效預訓練的 base 模型,團隊在 Post-training 階段研發了融合 VLM 各項能力、能通過更長思考過程實現極致推理效果的 Seed1.6-Thinking,也就是本次挑戰高考山東卷的選手。
Seed1.6-Thinking 訓練過程中采用了多階段的 RFT 和 RL 迭代優化,每一輪 RL 以上一輪 RFT 為起點,在 RFT 候選的篩選上使用多維度的 reward model 選擇最優回答。同時加大了高質量訓練數據規模(包括 Math、Code、Puzzle 和 Non-reasoning 等數據),提升了模型在復雜問題上的思考長度,并且在模型能力維度上深度融合了 VLM,給模型帶來清晰的視覺理解能力。
三、明年,我們還需要讓大模型參加高考嗎?
「AI 參加高考」已經成為了一年一度的熱點話題。在圖像識別、自然語言處理技術還不夠強大的年代,「標準化考試」的確是檢驗 AI 技術進步的一種方式。
正因此,每一年的「AI 趕考」都會引發大眾對 AI 能力邊界、未來教育模式以及人類智能獨特性的討論。在這個過程中,大眾討論的核心逐漸從「能不能做題」轉為「能做到什么程度」、「AI 能否理解深層含義和情感」等。
而這個周期性的議題在 2025 年迎來了里程碑式轉折,大模型在文本理解和生成、多模態理解、推理層面都有了顯著進步。AI 開始學會理解題目背后的深層邏輯和價值觀,開始理解特定學科領域的圖像信息,生成的答復也有了思想深度。
這種進步當然體現在了高考成績上:從去年勉強過一本線,到 2025 年沖擊清北、保底 985,大模型僅用一年時間就完成了從「普通本科」到「雙一流」的蛻變。這讓我們也意識到,高考這個曾經檢驗大模型「智力」水平的「試金石」,似乎變得不再具備挑戰性。
明年,像 Gemini、豆包這些大模型或許沒必要再做高考試卷,不妨告別標準化考試的框架,更深度地融入到科學研究、藝術創作、編程開發等真正創造「生產力」的領域,解決真實世界中那些沒有標準答案的復雜難題,讓人類少一些重復勞動。
我們有理由相信,在不久的將來,大模型會成為各個領域的行家里手。