從0到1:Linux磁盤I/O性能優化
在Linux 系統的廣袤世界里,磁盤 I/O 性能猶如隱藏在幕后卻掌控全局的關鍵角色,對系統整體性能有著舉足輕重的影響。想象一下,你正在使用一個基于 Linux 系統搭建的網站服務器,用戶點擊頁面后,需要從磁盤中讀取網頁文件、數據庫數據等信息來呈現頁面內容。如果磁盤 I/O 性能不佳,數據讀取緩慢,那么用戶可能需要長時間等待頁面加載,這不僅會嚴重影響用戶體驗,還可能導致用戶流失,對業務造成損失。再比如在數據分析場景中,數據科學家需要處理大量存儲在磁盤上的數據,若磁盤 I/O 性能不給力,數據讀取和寫入時間大幅增加,會極大地延長數據分析周期,使得分析結果無法及時產出,影響決策效率。
當磁盤 I/O 性能不佳時,會引發一系列令人頭疼的問題。系統響應變得遲緩,程序啟動時間大幅延長,文件復制、解壓等操作耗時漫長。在服務器環境中,還可能導致多個進程因為等待磁盤 I/O 操作完成而處于阻塞狀態,使得 CPU 資源閑置,系統整體吞吐量下降,就像一條交通要道上,車輛都堵在收費站等待繳費(磁盤 I/O 操作),導致道路(系統)擁堵,通行效率(性能)降低 。正是因為磁盤 I/O 性能如此重要,且性能不佳會帶來諸多嚴重后果,所以深入了解并優化 Linux 磁盤 I/O 性能顯得尤為迫切,接下來,讓我們一起揭開磁盤 I/O 性能優化的神秘面紗,從原理到實戰,逐步探索其中的奧秘。
Part1.Linux磁盤I/O工作原理
1.1 磁盤的分類與特點
在 Linux 系統中,磁盤主要分為機械磁盤(Hard Disk Drive,HDD)和固態磁盤(Solid State Disk,SSD) ,它們就像兩個性格迥異的 “存儲伙伴”,各自有著獨特的工作原理和性能特點。
機械磁盤的工作原理頗具 “機械感”,它主要由盤片、讀寫磁頭、馬達等機械部件組成。數據存儲在高速旋轉的盤片的環狀磁道上,當需要讀寫數據時,讀寫磁頭就像一個忙碌的 “快遞員”,在盤片表面移動,通過改變磁性來記錄或讀取數據 。不過這個 “快遞員” 的效率會受到盤片轉速和磁頭移動速度的限制,就像在城市中開車送快遞,道路擁堵(機械部件的物理限制)會影響送達速度。例如,普通機械硬盤的盤片轉速常見的有 5400 轉 / 分鐘和 7200 轉 / 分鐘,在讀寫零散小文件時,由于文件所在扇區不連續,磁頭需要不斷尋道,導致讀寫速度很慢,一般順序讀寫速度在 100 - 200MB/s 左右,隨機讀寫速度則更低,可能只有幾十 KB/s 。
固態磁盤則是依靠閃存芯片(NAND Flash)來存儲數據,它的工作方式更加 “電子化”,就像一個反應敏捷的 “電子精靈”,通過電子信號快速讀寫數據,沒有那些慢悠悠的機械部件 。這使得固態硬盤的讀寫速度極快,順序讀寫速度可達 3000MB/s 以上(如 NVMe SSD),隨機讀寫速度也遠超機械硬盤,能夠在幾秒鐘內啟動操作系統,快速加載應用程序和文件 。而且它抗震性強、無機械延遲、噪音小、功耗低,非常適合對速度和響應要求高的場景,如游戲主機、高性能臺式機等 。不過,固態硬盤的閃存芯片有寫入次數限制(P/E 周期),頻繁寫入可能會導致芯片老化,影響使用壽命,并且單位容量價格相對較高 。
對于連續 I/O 和隨機 I/O,不同磁盤有著不同的表現。連續 I/O 時,數據在磁盤上是連續存儲的,就像圖書館里同一類書籍整齊排列在書架上。機械磁盤不需要頻繁尋道,所以連續讀寫能力并不差,甚至在單碟容量提升和組建磁盤陣列的情況下,連續讀寫速度可以比固態硬盤更快;而固態硬盤在連續 I/O 時更是發揮其高速讀寫的優勢,數據傳輸流暢迅速 。在隨機 I/O 場景下,數據存儲位置零散,如同圖書館里的書籍被打亂放置。機械磁盤需要不停地移動磁頭來定位數據,尋道時間長,性能受到很大影響;固態硬盤雖然隨機性能比機械硬盤好很多,但由于存在 “先擦除再寫入” 的限制,隨機讀寫會導致大量的垃圾回收,所以隨機 I/O 性能相比連續 I/O 還是差一些,不過依然比機械磁盤強很多 。
1.2 文件系統的運作機制
文件系統是 Linux 系統中管理文件的重要部分,就像一個有序的圖書館管理員,負責整理和保管文件,而索引節點和目錄項則是它管理文件的重要工具。
索引節點(inode),可以看作是文件的 “身份證”,記錄了文件的元數據,如文件大小、訪問權限、修改日期、數據的位置等 。每個文件都有唯一對應的 inode,它和文件內容一樣,會被持久化存儲到磁盤中,所以 inode 也占用磁盤空間 。例如,當我們在 Linux 系統中查看一個文件的屬性時,顯示的文件大小、所有者、權限等信息就來自于 inode 。
目錄項(dentry),則像是文件的 “名片”,記錄了文件的名字、索引節點指針以及與其他目錄項的關聯關系 。多個關聯的目錄項構成了文件系統的目錄結構 。它是由內核維護的一個內存數據結構,也被叫做目錄項緩存 。比如我們在文件管理器中看到的文件和文件夾名稱,這些都是目錄項的體現,通過目錄項,我們可以快速找到對應的 inode,進而訪問文件 。 目錄項和索引節點是多對一的關系,這意味著一個文件可以有多個別名,就像一個人可以有多個昵稱,比如軟鏈接文件,就是多了一個指向相同 inode 的目錄項 。
虛擬文件系統(Virtual File System,VFS)是 Linux 內核中一個非常重要的抽象層,它就像一個萬能的翻譯官,為各種不同的文件系統提供了統一的接口 。由于 Linux 系統支持多種文件系統,如 EXT4、XFS、Btrfs 等,每種文件系統的實現細節都不同,如果沒有 VFS,應用程序和內核就需要針對不同的文件系統編寫不同的代碼,這無疑會大大增加開發和維護的難度 。
 圖片
圖片
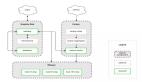
有了 VFS,它定義了一組所有文件系統都支持的數據結構和標準接口,用戶進程和內核中的其他子系統只需要跟 VFS 提供的統一接口進行交互,而不需要關心底層各種文件系統的實現細節 。例如,當我們使用 “open”“read”“write” 等系統調用操作文件時,實際上是通過 VFS 這個翻譯官,將這些操作轉發到底層具體的文件系統去執行 。在系統啟動時,VFS 會被建立,在內存中構建起文件系統的樹形結構,管理著各種文件系統的掛載點、inode 等信息,直到系統關閉時才會消亡 。
通過這張圖可以看到,在 VFS 的下方,Linux 支持各種各樣的文件系統,如 Ext4、XFS、NFS 等等。按照存儲位置的不同,這些文件系統可以分為三類。
- 第一類是基于磁盤的文件系統,也就是把數據直接存儲在計算機本地掛載的磁盤中。常見的 Ext4、XFS、OverlayFS等,都是這類文件系統。
- 第二類是基于內存的文件系統,也就是我們常說的虛擬文件系統。這類文件系統,不需要任何磁盤分配存儲空間,但會占用內存。我們經常用到的 /proc就是一種最常見的虛擬文件系統。
- 第三類是網絡文件系統,也就是用來訪問其他計算機數據的文件系統,比如 NFS、SMB、iSCSI 等。
這些文件系統,要先掛載到 VFS 目錄樹中的某個子目錄(稱為掛載點),然后才能訪問其中的文件。拿第一類,也就是基于磁盤的文件系統為例,在安裝系統時,要先掛載一個根目錄(/),在根目錄下再把其他文件系統(比如其他的磁盤分區、/proc 文件系統、/sys 文件系統、NFS 等)掛載進來。
1.3 I/O 操作的流程剖析
當應用程序進行 I/O 操作時,數據就像一個忙碌的 “旅行者”,在應用程序、緩存、文件系統和磁盤之間進行復雜的傳輸過程。
 圖片
圖片
以讀取文件為例,應用程序發起讀取文件的請求,這個請求首先會到達內核空間 。內核會先檢查頁緩存(Page Cache),頁緩存就像一個高速的臨時倉庫,存儲著最近訪問過的文件片段,這些片段更有可能在近期再次被訪問 。如果所需數據已經在頁緩存中,那就如同在自家附近的小倉庫中找到了需要的物品,直接從頁緩存中將數據復制到應用程序的內存空間中,這個過程非常迅速,不需要訪問慢速的磁盤 。
要是頁緩存中沒有找到所需數據,就會觸發缺頁錯誤(Page Fault) 。此時,內核就像一個勤勞的快遞員,需要從磁盤中讀取數據 。內核會通過文件系統找到數據在磁盤上的位置,向磁盤發出 I/O 請求 。磁盤接收到請求后,開始工作,機械磁盤需要移動磁頭定位到數據所在的磁道和扇區,固態磁盤則通過電子信號快速讀取數據 。讀取到的數據會被加載到頁緩存中,然后再從頁緩存復制到應用程序的內存空間 。如果頁緩存已滿,內核會按照一定的算法,如最近最少使用(Least Recently Used,LRU)算法,將最近最少使用的頁面刷新到磁盤并從緩存中驅逐,以騰出空間給新頁面 。
寫入操作的流程也類似,應用程序將數據寫入到內核的頁緩存中,標記寫入的頁面為臟頁(Dirty Page) 。此時數據并沒有立即寫入磁盤,而是在內核認為合適的時候,例如系統空閑時或者臟頁數量達到一定閾值時,才會將臟頁的數據真正寫入磁盤,這個過程稱為寫回(Write Back) 。這樣做的好處是可以減少磁盤 I/O 操作的次數,提高系統性能,因為磁盤的寫入速度相對較慢,批量寫入可以提高效率 。不過,如果系統突然崩潰,可能會導致部分已寫入頁緩存但未寫回磁盤的數據丟失 。
頁緩存的存在大大提高了 I/O 操作的性能,它利用了時間局部性原理(最近訪問過的頁面將在近期再次被訪問)和空間局部性原理(物理上相鄰的元素很有可能彼此接近) 。通過預讀(Read - Ahead)機制,內核會提前加載可能會被訪問的數據到頁緩存中,預測它們的訪問并攤銷一些 I/O 成本 。同時,頁緩存還通過延遲寫入和合并相鄰讀取來進一步提升 I/O 性能 。
Part2.衡量磁盤I/O性能的關鍵指標
2.1 IOPS:每秒 I/O 操作次數
IOPS,即 Input/Output Operations Per Second,翻譯過來就是每秒 I/O 操作次數 ,它就像是磁盤的 “忙碌程度計數器”,是衡量磁盤性能的重要指標之一 。這個指標主要用于評估存儲設備在單位時間內能夠處理的 I/O 請求數量,體現了磁盤隨機讀寫的能力 。在實際應用中,IOPS 在隨機 I/O 場景下有著不可替代的重要性 。例如在數據庫事務處理中,數據庫需要頻繁地讀寫大量小數據塊,這些數據塊的存儲位置通常是不連續的,屬于典型的隨機 I/O 操作 。以電商系統的訂單處理為例,當用戶下單時,系統需要將訂單信息寫入數據庫的不同表和字段中,這些寫入操作的位置是隨機分布的 。
如果磁盤的 IOPS 較低,那么在高并發的下單場景下,數據庫處理 I/O 請求的速度就會很慢,導致訂單處理延遲,用戶可能需要長時間等待才能看到下單結果,嚴重影響用戶體驗 。再比如在虛擬化環境中,多個虛擬機同時運行,每個虛擬機都可能產生大量的隨機 I/O 請求 。如果存儲設備的 IOPS 無法滿足這些請求,就會導致虛擬機性能下降,出現卡頓、響應遲緩等問題 。
IOPS 的數值受到多種因素的影響 。從硬件方面來看,磁盤類型是一個關鍵因素,固態硬盤(SSD)由于沒有機械尋道時間,其 IOPS 性能遠遠高于機械硬盤(HDD) 。一般消費級 SSD 的隨機 IOPS 可以達到數萬甚至數十萬,而普通機械硬盤的隨機 IOPS 通常只有幾十到幾百 。此外,硬盤的轉速、緩存大小等也會對 IOPS 產生影響,轉速越高、緩存越大,IOPS 性能相對越好 。在系統層面,隊列深度也會影響 IOPS 。隊列深度是指同時向磁盤提交的 I/O 請求數量 。
當隊列深度增加時,磁盤可以并行處理更多的 I/O 請求,從而提高 IOPS 。不過,當隊列深度超過一定值后,由于磁盤處理能力的限制,IOPS 可能不再提升,甚至會因為資源競爭而下降 。不同的 I/O 請求大小也會影響 IOPS,通常較小的 I/O 請求可以獲得更高的 IOPS,因為它們占用磁盤的時間較短,磁盤可以在單位時間內處理更多的此類請求 。
2.2 吞吐量:數據傳輸速率
吞吐量,簡單來說就是單位時間內成功傳輸的數據量 ,它就像是數據傳輸的 “高速公路”,反映了磁盤在單位時間內能夠傳輸數據的能力,是衡量磁盤性能的另一個重要指標 ,單位通常是字節每秒(B/s)、千字節每秒(KB/s)或兆字節每秒(MB/s) 。在順序 I/O 場景中,吞吐量起著至關重要的作用 。比如在視頻流服務中,服務器需要將大量的視頻數據連續不斷地傳輸給用戶 。假設一個高清視頻的碼率為 10Mbps(約 1.25MB/s),如果磁盤的吞吐量足夠高,能夠快速讀取視頻文件并傳輸給用戶,那么用戶就能流暢地觀看視頻,不會出現卡頓、加載緩慢等問題 。
相反,如果磁盤吞吐量不足,視頻數據傳輸不及時,就會導致視頻播放中斷,用戶體驗極差 。再比如在數據備份場景中,需要將大量的文件從一個存儲設備復制到另一個存儲設備,這個過程涉及到大量的順序讀寫操作 。如果磁盤吞吐量高,就能快速完成數據備份,節省時間;否則,備份過程可能會持續很長時間,影響業務的正常運行 。
影響吞吐量的因素有很多 。磁盤的類型和接口速度是重要因素之一,SSD 的順序讀寫速度比 HDD 快很多,因此在順序 I/O 場景下,SSD 的吞吐量通常更高 。例如,SATA 接口的 SSD 順序讀取速度一般在 500 - 600MB/s 左右,而 NVMe 接口的 SSD 順序讀取速度可以達到 3000MB/s 以上 。此外,數據塊大小也會對吞吐量產生影響,較大的數據塊可以減少 I/O 操作的次數,從而提高吞吐量 。在網絡存儲環境中,網絡帶寬也會限制吞吐量,如果網絡帶寬不足,即使磁盤本身的吞吐量很高,數據傳輸速度也會受到限制 。
2.3 延遲:I/O 操作的響應時間
I/O 延遲,指的是從應用程序發出 I/O 請求開始,到接收到 I/O 操作完成的響應所經歷的時間 ,它就像是快遞的 “送貨時長”,是衡量磁盤性能的關鍵指標之一,直接反映了磁盤處理 I/O 請求的速度 。I/O 延遲對應用程序的性能有著深遠的影響 。在實時交易系統中,如股票交易軟件,每一次交易操作都需要快速讀取和寫入數據 。如果 I/O 延遲過高,從用戶下單到系統確認交易的時間就會變長,可能會導致交易失敗或者錯過最佳交易時機 。再比如在游戲場景中,游戲需要實時加載各種資源,如地圖、角色模型等 。如果 I/O 延遲大,游戲畫面的加載就會緩慢,出現卡頓現象,嚴重影響玩家的游戲體驗 。
I/O 延遲產生的原因主要有以下幾個方面 。磁盤的物理特性是一個重要因素,對于機械硬盤來說,尋道時間和旋轉延遲是導致 I/O 延遲的主要原因 。尋道時間是指磁頭移動到數據所在磁道所需的時間,旋轉延遲是指盤片旋轉將數據所在扇區移動到磁頭下方所需的時間 。由于機械硬盤的機械運動速度有限,這兩個時間加起來通常會導致較高的 I/O 延遲 。而固態硬盤雖然沒有機械運動部件,但也存在閃存芯片的讀寫延遲以及內部控制器的處理時間 。
此外,系統的負載情況也會影響 I/O 延遲 。當系統中有大量的 I/O 請求同時發生時,磁盤需要排隊處理這些請求,等待時間就會增加,從而導致 I/O 延遲上升 。文件系統的設計和實現也會對 I/O 延遲產生影響,例如文件系統的元數據管理方式、緩存機制等 。
Part3.實用的磁盤I/O性能測試工具
在優化 Linux 磁盤 I/O 性能的過程中,選擇合適的性能測試工具至關重要。這些工具就像是精準的 “性能探測器”,能夠幫助我們深入了解磁盤 I/O 的性能狀況,為優化提供有力的數據支持。接下來,讓我們一起探索兩款常用的磁盤 I/O 性能測試工具。
3.1 fio:靈活的 I/O 測試工具
fio 是一款功能極其強大且靈活的 I/O 測試工具,堪稱 I/O 測試領域的 “瑞士軍刀”,它支持多種操作系統,包括 Linux、Windows 等 ,并且可以模擬多種不同的 I/O 模式 ,是系統管理員和存儲工程師評估存儲性能的得力助手 。在 Linux 系統中,可以通過包管理器輕松安裝,對于 Debian/Ubuntu 系統,使用命令 “sudo apt - get install fio”;對于 CentOS 系統,則使用 “sudo yum install fio” 。
# 使用fio進行磁盤I/O測試
fio --name=test --ioengine=libaio --iodepth=4 --rw=readwrite --bs=4k --size=1G --numjobs=1fio 之所以如此強大,是因為它擁有豐富的參數選項,能夠滿足各種復雜的測試需求 。比如 “--name” 用于定義作業名稱,方便在測試結果中區分不同的測試任務;“--ioengine” 用于指定 I/O 引擎,常見的有 sync、mmap、pvsync、libaio 等,不同的 I/O 引擎適用于不同的測試場景 。“--rw” 用來指定讀寫方式,如 randread(隨機讀)、randwrite(隨機寫)、read(順序讀)、write(順序寫)等 。“--bs” 表示塊大小,“--size” 指定測試文件大小,“--numjobs” 設置工作線程數,“--runtime” 規定測試運行時間,“--time_based” 確定測試運行模式(時間模式或者 I/O 模式),“--direct” 決定是否使用直接 I/O 。“--iodepth” 代表 I/O 隊列深度,“--group_reporting” 用于指定是否按照組進行測試結果的報告,“--output - format” 可以指定測試結果的輸出格式,如 json、csv、xml 等 。
下面通過幾個具體的例子來看看如何使用 fio 進行常見 I/O 場景測試 。假設我們要測試磁盤的順序讀性能,可以使用這樣的命令:“fio --name = seq_read --ioengine = libaio --iodepth = 1 --rw = read --bs = 4k --size = 1G --numjobs = 1” 。在這個命令中,“--name = seq_read” 設定作業名稱為 seq_read ;“--ioengine = libaio” 選擇異步 I/O 引擎 libaio ,它能提供高效的異步 I/O 操作,適合模擬實際應用中的異步讀寫場景 ;“--iodepth = 1” 設置 I/O 隊列深度為 1 ,表示每個工作線程同時只進行 1 個 I/O 操作 ;“--rw = read” 指定測試類型為順序讀 ;“--bs = 4k” 將塊大小設置為 4KB ,這是一個常見的塊大小,很多文件系統和應用程序在處理小文件時會使用這個大小 ;“--size = 1G” 表示測試文件大小為 1GB ;“--numjobs = 1” 代表使用 1 個工作線程 。執行這個命令后,fio 會按照設定的參數進行順序讀測試,并輸出詳細的測試結果,包括 IOPS、帶寬、延遲等信息 。
再比如,要測試磁盤的隨機讀寫混合性能,命令可以是:“fio --name = rand_rw_mix --ioengine = libaio --iodepth = 16 --rw = randrw --rwmixread = 70 --bs = 4k --size = 2G --numjobs = 4 --runtime = 60 --group_reporting” 。這里 “--rw = randrw” 指定為隨機讀寫混合模式 ,“--rwmixread = 70” 表示讀操作占 70% ,寫操作占 30% ,這樣可以模擬一些實際應用中讀寫比例不同的場景 ,如數據庫的讀寫操作 ;“--iodepth = 16” 增大了 I/O 隊列深度,以測試磁盤在高并發 I/O 請求下的性能 ;“--numjobs = 4” 使用 4 個工作線程并發進行測試 ;“--runtime = 60” 設置測試運行時間為 60 秒 ;“--group_reporting” 使測試結果按照組進行報告,方便查看和分析多個工作線程的整體性能 。通過這些不同參數的組合,fio 能夠模擬出各種各樣復雜的 I/O 場景,為我們深入了解磁盤性能提供了有力的支持 。
3.2 iostat:系統 I/O 統計信息查看工具
iostat 是 Linux 系統中一個非常實用的工具,它就像是系統 I/O 的 “健康檢測儀”,主要用于監控系統設備的 I/O 負載情況 ,能夠提供關于磁盤使用情況、讀寫操作和等待時間等豐富的 I/O 性能狀態數據 。iostat 命令首次運行時,會顯示自系統啟動開始的各項統計信息,之后運行則顯示自上次運行該命令以后的統計信息 。我們可以通過指定統計的次數和時間來獲取所需的統計信息 。在大多數 Linux 發行版中,iostat 命令包含在 sysstat 包中 。對于 Debian/Ubuntu 系統,可以使用 “sudo apt - get install sysstat” 命令進行安裝;對于 CentOS 系統,使用 “sudo yum install sysstat” 來安裝 。
# 安裝iostat(以CentOS為例)
sudo yum install sysstat
# 使用iostat查看磁盤I/O性能
iostat -mx 1使用 iostat 查看磁盤 I/O 統計信息的方法較為簡單 。基本命令格式為 “iostat [OPTION] [INTERVAL] [COUNT]” ,其中 “OPTION” 是選項參數,用于指定輸出的特定信息,“INTERVAL” 指定數據刷新間隔,單位為秒,“COUNT” 指定顯示數據的次數 。例如,要查看系統所有磁盤設備每秒的 I/O 情況,并以擴展格式顯示詳細信息,可以使用命令 “iostat -x 1” 。這里 “-x” 選項表示顯示擴展統計信息,它會展示諸如每秒合并的讀請求數量(rrqm/s)、每秒合并的寫請求數量(wrqm/s)、每秒讀取的操作數(r/s)、每秒寫入的操作數(w/s)、每次請求的平均等待時間(await)、磁盤當前的使用率(% util)等詳細數據 ,“1” 表示每秒更新一次數據 。
執行該命令后,會實時輸出磁盤 I/O 的各項統計信息,通過這些信息,我們可以直觀地了解磁盤的工作狀態 。比如,如果看到 “% util” 接近 100% ,說明磁盤產生的 I/O 請求太多,I/O 系統已經滿負荷,該磁盤可能存在瓶頸 ;如果 “await” 遠大于平均每次設備 I/O 操作的服務時間(svctm),說明 I/O 隊列太長,I/O 響應太慢,可能需要進行優化 。
如果只想查看指定磁盤設備(如 sda)的I/O統計信息,可以使用 “iostat -d -x sda 2” 命令 。“-d”選項表示僅顯示設備(磁盤)使用狀態,“-x” 依然是顯示擴展信息,“sda” 指定要監控的磁盤設備,“2”表示每2秒刷新一次數據 。這樣就能專注于特定磁盤的性能監控,方便我們對單個磁盤進行詳細的分析和排查問題 。此外,還可以結合其他選項來滿足不同的需求,比如“-k”選項使某些使用 block 為單位的列強制使用 Kilobytes 為單位顯示,“-m”選項則是以兆字節每秒為單位顯示傳輸速率,讓我們能更直觀地理解數據的大小和傳輸速度 。
Part4.Linux磁盤I/O性能優化實戰策略
4.1 應用程序層面的優化
在應用程序層面,優化 I/O 請求模式是提升磁盤 I/O 性能的關鍵策略之一 。盡量使用順序 I/O 代替隨機 I/O,因為順序 I/O 就像在一條暢通無阻的高速公路上行駛,數據讀取或寫入的位置是連續的,避免了磁盤磁頭頻繁尋道的開銷 。例如,在數據寫入場景中,按順序將數據寫入文件,而不是隨機地在文件的不同位置進行寫入操作 。對于數據庫應用,可以通過合理設計表結構和索引,使得數據的讀寫操作盡可能順序化 。以電商數據庫中的訂單表為例,按照訂單時間順序存儲訂單數據,在查詢一段時間內的訂單時,就可以利用順序 I/O 快速讀取數據 。
減少不必要的 I/O 操作也是提高性能的重要方法 。在程序中避免頻繁地打開和關閉文件,因為每次打開和關閉文件都涉及到系統資源的分配和釋放,會增加 I/O 開銷 。可以將多次小的 I/O 操作合并為一次大的 I/O 操作,減少 I/O 請求的次數 。比如在日志記錄場景中,不要每次有新的日志信息就立即寫入文件,而是先將日志信息緩存起來,當緩存達到一定數量或一定時間間隔后,再一次性寫入文件 。
使用異步 I/O(Asynchronous I/O)可以顯著提升 I/O 性能 。異步 I/O 允許應用程序在發起 I/O 請求后,不需要等待 I/O 操作完成就可以繼續執行其他任務,就像在餐廳點餐時,點完餐可以先去做其他事情,而不是一直等待食物上桌 。在 Linux 系統中,可以使用 libaio 庫來實現異步 I/O 。以 C 語言為例,通過調用 libaio 庫中的函數,如 io_submit、io_getevents 等,可以實現高效的異步 I/O 操作 。在高并發的 Web 服務器應用中,使用異步 I/O 可以讓服務器在處理 I/O 操作的同時,繼續響應其他客戶端的請求,大大提高服務器的并發處理能力 。
合理運用緩存技術也能有效減少磁盤I/O操作 。在應用程序內部構建緩存機制,將經常訪問的數據存儲在內存緩存中,當再次需要訪問這些數據時,直接從緩存中獲取,避免了磁盤I/O 。例如,在 Web 應用中,可以使用 Memcached或Redis等內存緩存系統,緩存網頁片段、數據庫查詢結果等數據 。當用戶請求相同的數據時,應用程序首先檢查緩存,如果緩存中有數據,就直接返回給用戶,減少了從磁盤讀取數據的時間 。同時,還可以利用操作系統的頁緩存,通過適當的文件訪問模式和系統調用,讓操作系統更好地管理頁緩存,提高數據訪問效率 。
4.2 文件系統層面的優化
選擇合適的文件系統是文件系統層面優化的基礎 。不同的文件系統有著各自獨特的特性,適用于不同的應用場景 。EXT4 是 Linux 系統中廣泛使用的文件系統,它具有成熟穩定、兼容性好的特點 ,在小文件處理方面表現出色,適合一般的桌面應用和小型服務器場景 。比如在個人電腦的 Linux 系統中,使用 EXT4 文件系統來存儲日常的文檔、圖片、視頻等文件,能夠滿足用戶的基本需求 。XFS 文件系統則更適合大文件和高并發的應用場景 ,它具有高性能、可擴展性強的優點,支持超大文件和大容量存儲設備 。
在大型數據中心中,用于存儲海量數據的服務器,如視頻存儲服務器,采用 XFS 文件系統可以充分發揮其優勢,快速處理大量的大文件讀寫請求 。Btrfs 文件系統則提供了一些高級功能,如快照、數據壓縮、錯誤檢測與修復等 ,適用于對數據管理和可靠性有較高要求的場景 ,如企業級數據存儲和備份系統 。
調整文件系統的掛載選項和參數可以進一步優化性能 。在掛載文件系統時,可以使用 “noatime” 和 “nodiratime” 選項 。“noatime” 禁止更新文件的訪問時間戳,“nodiratime” 禁止更新目錄的訪問時間戳 。這兩個選項可以減少文件系統的 I/O 操作,因為每次文件或目錄被訪問時,默認情況下會更新其訪問時間戳,這會產生額外的 I/O 開銷 。例如,對于一些只需要讀取數據,而不需要關注文件訪問時間的應用場景,如靜態文件服務器,可以在掛載文件系統時使用這兩個選項,提高系統性能 。
對于使用 EXT4 文件系統的設備,可以使用 tune2fs 命令來調整文件系統的參數 。比如使用 “tune2fs -o journal_data_writeback /dev/sda1” 命令,可以將文件系統的日志模式設置為 data=writeback,這種模式下,數據的寫入操作會更加激進,性能更高,但在系統崩潰時可能會導致數據丟失的風險增加 ,適用于對性能要求較高且對數據一致性要求相對較低的場景 。還可以合理設置文件系統的日志大小,使用 “mkfs.ext4 -J size=1g /dev/sda1” 命令可以在創建 EXT4 文件系統時,將日志大小設置為 1GB ,根據實際需求調整日志大小,可以平衡文件系統的性能和數據安全性 。
4.3 磁盤層面的優化
在磁盤層面,升級硬件是提升 I/O 性能最直接有效的方法之一 。將機械硬盤升級為固態硬盤(SSD)能帶來質的飛躍 。SSD 憑借其快速的讀寫速度、極低的尋道時間和高隨機 I/O 性能,成為對 I/O 性能要求苛刻場景的首選 。在數據中心中,許多高性能數據庫服務器紛紛采用 SSD 作為存儲設備 。以 Oracle 數據庫為例,將原本使用機械硬盤的存儲系統更換為 SSD 后,數據庫的查詢響應時間大幅縮短,事務處理能力顯著提升 。在一些對數據讀寫速度要求極高的實時分析系統中,SSD 的優勢也得以充分體現,能夠快速處理大量的實時數據,為決策提供及時準確的支持 。
優化磁盤陣列配置也能顯著提高性能 。RAID(Redundant Arrays of Independent Disks)技術通過將多個磁盤組合成一個邏輯單元,實現數據冗余、提高數據訪問速度以及增強數據保護能力 。不同的 RAID 級別適用于不同的場景 。RAID 0采用條帶化技術,將數據分散存儲在多個磁盤上,讀寫性能極高,但沒有數據冗余,一旦其中一個磁盤出現故障,整個陣列的數據都會丟失 ,適用于對數據安全性要求不高,但對讀寫速度要求極高的場景,如視頻編輯工作站,在處理大型視頻文件時,可以利用 RAID 0的高速讀寫性能快速加載和保存視頻數據 。RAID 1 是鏡像模式,將數據完全復制到多個磁盤上,具有很高的數據冗余能力,任何一塊磁盤的故障都不會影響數據的訪問,但寫入性能相對較低,因為每次寫操作都需要同時寫入多個磁盤 ,常用于對數據安全性要求極高的場景,如銀行的核心業務系統,確保客戶數據的安全可靠 。
RAID 5結合了數據分條和分布式奇偶校驗技術,讀性能接近 RAID 0,寫性能處于平均水準,允許一塊磁盤損壞,利用剩下的數據和奇偶校驗信息可以恢復被損壞的數據 ,適用于對性能和安全都有一定要求的場景,如企業的文件服務器,既能保證數據的安全性,又能滿足日常文件讀寫的性能需求 。RAID 10則是 RAID 0和 RAID 1的組合體,首先創建多個RAID 1 鏡像對,然后將這些鏡像對條帶化成 RAID 0 陣列,讀寫性能都非常高,且具有較高的容錯能力 ,適用于對性能和數據安全性都有極高要求的場景,如大型電商網站的數據庫主庫,在高并發的業務場景下,既能保證數據的安全,又能快速響應大量的讀寫請求 。
調整 I/O 調度器也是優化磁盤性能的重要手段 。Linux 系統提供了多種 I/O 調度器,如 noop、deadline、cfq(完全公平隊列)等 。noop 調度器實現了一個簡單的 FIFO 隊列,像電梯一樣對 I/O 請求進行組織,將新請求合并到最近的請求之后 ,它非常適合 SSD 等快速存儲設備,因為 SSD 的讀寫速度快,尋道時間幾乎可以忽略不計,noop 調度器簡單高效的特性能夠充分發揮 SSD 的優勢 。在使用 SSD 的服務器中,將 I/O 調度器設置為 noop,可以減少調度器的開銷,提高 I/O 性能 。
deadline 調度器通過時間以及硬盤區域進行分類,確保在一個截止時間內服務請求,默認讀期限短于寫期限,防止寫操作因為不能被讀取而餓死 ,它對數據庫環境非常友好,在數據庫服務器中,使用 deadline 調度器可以保證數據庫的 I/O 請求能夠得到及時處理,減少 I/O 延遲,提高數據庫的性能 。
cfq 調度器試圖均勻地分布對 I/O 帶寬的訪問,避免進程被餓死并實現較低的延遲 ,它是一種比較通用的調度器,對于通用的服務器和桌面系統是一個不錯的選擇 ,在日常辦公的 Linux 桌面系統中,cfq 調度器能夠公平地分配 I/O 資源,保證各個應用程序都能獲得合理的 I/O 帶寬 。可以通過修改 “/sys/block/sdX/queue/scheduler” 文件來調整 I/O 調度器,例如 “echo noop > /sys/block/sda/queue/scheduler” 命令可以將 sda 磁盤的 I/O 調度器設置為 noop 。