













關系數據庫的末日是否已經來臨
最近,大量新的非關系式數據庫如雨后春筍般出現在云里云外。這其中所釋放出的一個關鍵信息是:“如果想獲得豐富而隨需應變的可伸縮性,你需要一個非關系數據庫。”
如果這是真的,那么這是不是一個跡象,表明曾經強大的關系式數據庫終于在它的盔甲上出現了裂縫?關系數據庫的日子是不是到頭了?該隱退了?在本文中,我們將檢視當前這種在特定情況下擺脫關系數據庫的趨勢,并分析這對于關系數據庫的未來意味著什么。
關系數據庫已過而立之年。在此期間,短暫爆發過一些所謂終結關系數據庫的革命。當然,最終都失敗了,絲毫沒有動搖到關系數據庫的主導地位。
先了解一些背景
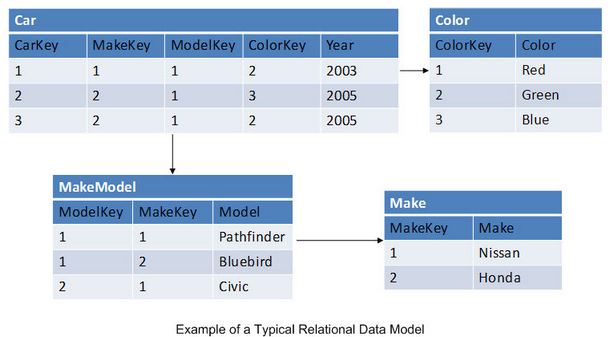
一個關系數據庫基本上就是一個表(實體)集合。表由列和行(變量集)構成。這些表存在約束,相互之間定義了關系。關系數據庫使用SQL進行查詢,結果集通過訪問一個或多個表的查詢生成。單個查詢里被訪問到的多個表,一般是利用在表關系列里定義的范式被“連接”到一起的。 規范化 是關系數據庫使用到的一種數據結構模型,能保證數據一致性并消除數據冗余。
關系數據庫在 關系數據庫管理系統 (RDBMS)的幫助下得以促進。我們今天所使用的絕大部分數據庫系統都是RDBMS,包括 Oracle,SQL Server, MySQL,Sybase,DB2,TeraData等等。
關系數據庫占據統治地位的原因并非微不足道的。它們持續提供了簡單性、健壯性、靈活性以及性能的***組合,并帶來了通用數據管理的兼容性。
不過,為了實現這一切,關系數據庫的內部不得不復雜得難以置信。舉個例子說,一個相對簡單的SELECT語句可能有著上百條執行路徑,優化程序在運行時必須進行評估。這一切都被隱藏起來,對用戶都是不可見的,RDBMS通過使用類似基于代價的算法來決定***響應請求的“執行計劃”。
關系數據庫的問題
盡管RDBMS為數據庫用戶提供了簡單性、健壯性、靈活性、性能、可伸縮性以及兼容性的***組合,但它在其中每個領域里的性能,不一定就優于其他追求某一項好處的獨立替代方案。迄今為止這不是太大的問題,因為RDBMS的普遍優勢已經壓制了開疆拓土的需求。不過,如果你的確存在著通用關系數據庫無法滿足的要求,替代的方案則總可以填補這些壁龕。
今天,形勢略有不同。對于數量不斷增長的應用程序而言,上述的其中一項好處變得越來越重要;雖仍被視為特殊,但正迅速成為主流,以至于對于不斷增長的數據庫用戶來說,其在重要性方面已經開始侵蝕掉其它的好處了。這項好處就是可伸縮性。隨著越來越多如Web服務之類承受大規模工作負荷的應用的發行,其對可伸縮性的需求,首先有可能會改變得非常迅速,其次會變得無比龐大。***種場景下,如果你只有一個龜縮在一所房子內的服務器中的關系數據庫,情況將難以管理。舉個例子,如果你的負載一夜之間增加了2倍,你能用多快的速度去升級硬件?第二種情況下,一般的關系數據庫是也很難管理的。
關系數據庫的確能伸縮自如,但通常只能單臺服務器節點上進行。一旦單節點的能力抵達上限,你就得通過多服務器節點來往外擴展來分發負載。這時候關系數據庫的復雜性就開始影響其潛在的擴展規模了。試圖擴展到成百上千個節點,而不是幾個,將導致不堪復雜性之重負,這一特點使得RDBMS在大型分布式系統平臺市場里的生存能力被大幅削減。
為了讓云服務變得可行,供應商不得不突破這種限制,因為一個缺乏伸縮性的數據倉儲的云平臺根據就不能算一個平臺。因此,為了能向客戶提供的一個伸縮自如的空間去存放應用數據,供應商實際上只有一種真正的選擇。他們不得不實現一種新型的關注于可擴性的數據庫系統,而犧牲掉關系數據庫所帶來的其他好處。
這些努力,再加上那些已有的特殊供應商,已經帶來了一種新型的數據庫管理系統。
#p#
新品種
這種新型的數據庫管理系統通常被稱為鍵/值存儲。實際上,尚無正式的名字,因此你可能會看到它被稱為面向文檔的、面向互聯網的、面向屬性的、 分布式數據庫 (盡管這也可以是關系式的)、共享排序數組、 分布式哈希表以及鍵/值數據庫。雖然每個名字都指出了這種新方案的某種特征,但都是基于一個主題的派生,這個主題就是我們將要命名的鍵/值數據庫。
不關你怎么稱呼它,這個“新型”的數據庫其實已經在某些普通關系數據庫不合適的特殊應用里使用了很長時間了。不過如果沒有Web和云應用所帶來的伸縮性的話,它很可能還得繼續呆在深閨大院里。現在的挑戰是我們得弄清楚,究竟是它還是關系數據庫更適合于特定應用。
關系數據庫和鍵/值數據庫從根本上來說是完全不同的,分別被設計用于滿足不同的需求。迄今為止,一項一對一的比較能有助于你理解這種差異性,不過在開始之前,先讓我們來看看下面:
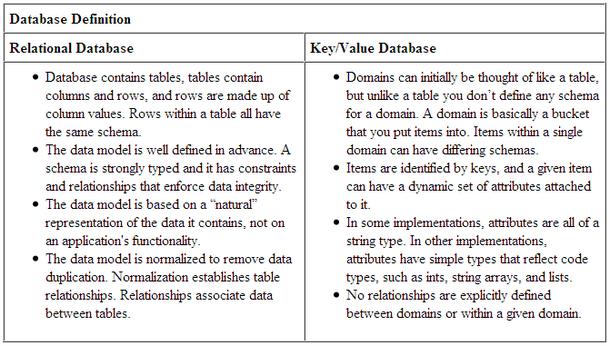
沒有實體連接
鍵/值數據庫是面向項目的,這意味著所有與項目有關的數據都被存儲進該項目中。一個域(你可以把它視為表)可以包含大量不同的項目。比如說,一個域里可以同時包含客戶項目和定單項目。這意味著在一個域內,不同項目間的數據通常是重復的。這在實踐上是可行的,因為磁盤空間相對廉價。但這個模型允許一個單一的項目包含完所有相關數據,就可以通過消除對多表的數據連接的需求來改善可擴性。而在關系數據庫中,那樣的數據需要被連接到一起,以便能重組為相關屬性。
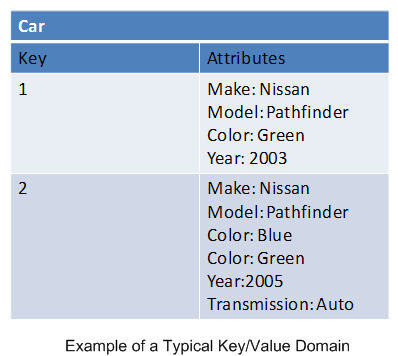
不過雖然在關系數據庫中的需求在鍵/值數據庫已大為減少,有些東西還是不可避免的。那些關系一般存在于核心實體之間。比如說,定單系統會有這樣一些項目,其中包含有客戶、產品及定單的數據。 這些是否在相同或不同的域都是無關緊要的;但是當客戶下單時,你大概不會想把客戶和產品的屬性都放進同一張定單里吧。
相反,定單需要包含相關鍵值指向客戶和產品。盡管這在鍵/值數據庫是完全可行的,這些關系卻不會在數據模型本身內進行定義,因此數據庫管理系統是無法強制要求這些關系的數據一致性的。這意味著你可以刪除客戶及其已訂購產品。確保數據完整性的責任完全落在了應用的身上。
鍵/值存儲:優點
有兩點鍵/值數據庫是明顯優于關系數據庫的。
云的***搭檔
***個好處是它們簡單,并因此比關系數據庫伸縮起來要自如得多。如果你正在打算把一個內部系統聚攏起來,試圖把預期中規模龐大的伸縮需求交給數據倉儲背后那數十上百臺服務器去處理,那么就請考慮一下鍵/值存儲。
由于鍵/值數據庫簡單,且動態可擴,它們也是提供多用戶、web服務的平臺數據存儲的供應商的選擇。這種數據庫提供了相對廉價的設計存儲平臺,并擁有龐大的擴充潛力。用戶通常只需用多少就給多少,而其需求增長時配額能隨之而增。與此同時,供應商能基于總用量動態擴充平臺,整個平臺的大小幾乎不受限制。(譯者:最典型的就是各種所謂支持多少G的郵箱應用了)
編碼得心應手
關系數據庫模型和應用代碼對象模型通常是以不同方式建立起來的,這導致了不兼容性。開發人員通過將代碼映射到關系模型去克服這種不兼容性。這個過程一般被稱為 對象-關系映射,基本上等于是“管道”代碼,沒有直接明確的價值,卻耗費掉了應用開發的大量時間和精力。另一方面,許多鍵/值數據庫在結構中保留的數據,與底層代碼中的對象類的映射關系卻要直接得多,從而顯著減少了開發時間。
其它一些支持這種數據存儲的理由,比如“關系數據庫相比之下更為笨拙(不管這意味這什么)”等,則不太令人信服。不過在跳上這趟鍵/值數據庫的列車之前,請先考慮一下它的缺點。
鍵/值存儲: 缺點
關系數據庫固有的約束保證數據在***層次擁有完整性。違反完整性約束的數據在物理上進不了數據庫中。這些約束在鍵/值數據庫中是不存在的,因此確保設計完整性的責任全部落到了應用程序的肩上。但是程序會經常出現Bug。在一個設計得當的關系數據庫里,Bug通常不會導致數據完整性問題;但是在鍵/值數據庫里的bug就很容易引起數據完整性問題。
關系數據庫另一項關鍵的好處就是它強迫你經過一個數據建模的過程。如果做得好,這個建模過程所創建出的數據庫的邏輯結構,就應該是映射它所要包含的數據,而非映射應用程序的結構。然后數據從某種程度上就變得是獨立于應用的,意味著其他應用同樣也能使用統一數據集,從而應用邏輯的改變不會影響到底層的數據模型。而鍵/值數據庫要實現這一過程的話,就要以類的建模實踐替代關系數據建模,以便在數據的自然結構基礎上創建出通用的類。
還有別忘了兼容性。面向云的數據庫不像關系數據庫,并沒有多少辦法去共享標準。盡管它們都有著類似的概念,卻各有著自己的API、特定的查詢接口及特性。因此,你真的要信任你的供應商,因為就算你對服務不滿意也覆水難收了。還有,由于目前所有的鍵/值數據庫均處于測試階段,這種信任的風險可比對老派的關系數據庫要高的多。
分析上的限制
在云內,鍵/值數據庫一般是多租戶的,這意味這許多用戶和應用將使用同一系統。為了防止任一進程導致共享環境過載,大部分云數據存儲嚴格限制了單一查詢可能導致的總影響效應。舉個例子,在 SimpleDB里,你不能執行過程超過5秒鐘的查詢。而在Google的AppEngine Datastore里,任何查詢結果都不允許超過1000條。
這些限制對于你的面包-奶油式的應用邏輯(添加、更新、刪除、獲取少量內容)而言不成問題。但是當你的應用取得成功的時候會發生什么呢?你已經攫取了許多用戶,獲得了大量數據,現在你想為客戶創造新價值,或者也許還想利用這些數據產生新的收入。你就會發現自己被嚴重限制了,甚至連直接的分析型查詢都很困難。在此類平臺上,類似追蹤(用戶的)使用模式、基于用戶歷史提供建議等事情,即便不是不可能也是非常困難的。
這種情況下,你將不得不實現一個從鍵/值數據庫分離出來的,獨立的分析型數據庫,以便執行那樣的分析。再想想你該在哪里才能做這樣的事情?又該如何去做?是不是應在云上維護它?還是投資于一個現場(譯者:on-site對應于off-site,一般在IT外包中應用)的設施?你和云服務供應商之間的延遲會不會成為問題?你現在的基于云的鍵/值數據庫支持它嗎?如果你的鍵/值數據庫有10億個條目,可是每秒鐘卻只能提供1000條結果,這樣的查詢該執行多久才能完事呢?
歸根結底,雖然規模是一項考慮因素,不要把它排在你將數據轉換成為資產的能力的前頭。如果你的用戶,因為競爭對手擁有更酷更人性化的特性而跑掉,這世上的一切伸縮性都將一無是處。
#p#
云服務競爭者
一些網絡服務供應商現在提供了基于即用即付的多租戶鍵/值數據庫。大部分都符合我們這里討論到的標準,但是每一個都有其獨特之處,與迄今描述的一般標準有所不同。現在讓我們看看這些特定的數據庫,分別是SimpleDB, Google AppEngine Datastore和SQL Data Services。
亞馬遜: SimpleDB
SimpleDB 是一個亞馬遜網絡服務平臺的一個面向屬性的鍵/值數據庫。SimpleDB仍處于公眾測試階段;當前,用戶能在線注冊其“免費”版 --免費的意思是說直到超出使用限制為止。
SimpleDB有幾方面的限制。首先,一次查詢最多只能執行5秒鐘。其次,除了字符串類型,別無其它數據類型。一切都以字符串形式被存儲、獲取和比較,因此除非你把所有日期都轉為ISO8601,否則日期比較將不起作用。第三,任何字符串長度都不能超過1024字節,這限制了你在一個屬性中能存儲的文本的大小(比如說產品描述等)。不過,由于該模式動態靈活,你可以通過追加“產品描述1”、“產品描述2”等來繞過這類限制。一個項目最多可以有 256個屬性。由于處在測試階段,SimpleDB的域不能大于10GB,整個庫容量則不能超過1TB。
SimpleDB的一項關鍵特性是它使用一種最終一致性模型。這個一致性模型對并發性很有好處,但意味著在你改變了項目屬性之后,那些改變有可能不能立即反映到隨后的讀操作上。盡管這種情況實際發生的幾率很低,你也得有所考慮。比如說,在你的演出訂票系統里,你不會想把***一張音樂會門票賣給5個人,因為在售出時你的數據是不一致的。
Google AppEngine Data Store
Google AppEngine Datastore 是在BigTable之上建造出來的,是Google的內部存儲系統,用于處理結構化數據。AppEngine Datastore其自身及其內部都不是直接訪問BigTable的實現機制,可被視為BigTable之上的一個簡單接口。
AppEngine Datastore所支持的項目的數據類型要比SimpleDB豐富得多,也包括了包含在一個項目內的數據集合的列表型。
如果你打算在Google AppEngine之內建造應用的話,幾乎可以肯定要用到這個數據存儲。然而,不像SimpleDB,使用谷歌網絡服務平臺之外的應用,你并不能并發地與AppEngine Datastore進行接口 (或通過BigTable)。
微軟: SQL數據服務
SQL數據服務 是微軟 Azure 網絡服務平臺的一部分。該SDS服務也是處于測試階段,因此也是免費的,但對數據庫大小有限制。 SQL數據服務其自身實際上是一項處在許多SQL服務器之上的應用,這些SQL服務器組成了SDS平臺底層的數據存儲。你不需要訪問到它們,雖然底層的數據庫可能是關系式的;SDS是一個鍵/值型倉儲,正如我們迄今所討論過的其它平臺一樣。
微軟看起來不同于前三個供應商,因為雖然鍵/值存儲對于可擴性而言非常棒,相對于RDBMS,在數據管理上卻很困難。微軟的方案似乎是入木三分,在實現可擴性和分布機制的同時,隨著時間的推移,不斷增加特性,在鍵/值存儲和關系數據庫平臺的鴻溝之間搭起一座橋梁。
非云服務競爭者
在云之外,也有一些可以獨立安裝的鍵/值數據庫軟件產品。大部分都還很年輕,不是alpha版就是beta版,但大都是開源的;通過看看它的代碼,比起在非開源供應商那里,你也許更能意識到潛在的問題和限制。
CouchDB
CouchDB 是一個免費、開源、面向文檔的數據庫。它來自于鍵/值存儲,使用JSON(譯者:JavaScript Object Notation,一種輕量級的數據交換格式)來定義項目的模式。CouchDB允許通過JavaScript動態創建“視圖”,意在跨越面向文檔型數據庫與關系數據庫之間的鴻溝。這些視圖將文檔數據映射在類似表的結構上,可被索引和查詢。
現在,CouchDB 還不是真正的分布式數據庫。它的復制功能允許數據在服務器間同步,但這并非建設高可擴性的環境所需的那種分布類型。毫無疑問,CouchDB團隊將朝此目標繼續努力。
Project Voldemort
Project Voldemort 是分布式的鍵/值數據庫,旨在橫向擴展于大量的服務器中。它產生自LinkedIn所完成的工作,據報告在那兒為幾個有著極高可擴性要求的系統所使用。Project Voldemort也使用了Amazon的最終一致性模型。
Project Voldemort還很新;它的網站前幾周才剛開張。
Mongo
Mongo是由Geir Magnusson和Dwight Merriman (提到DoubleClick你可能就想到他)在10gen開發出來的數據庫系統。跟CouchDB一樣,Mongo是一個面向文檔的JSON數據庫,除了它是被設計為一個真正的對象數據庫,而不是一個純粹的鍵/值存儲這一點之外。起初,10gen關注于整合出一個完整的網絡服務棧;然而最近,它已經把重點轉移到Mongo數據庫上了。其beta測試版計劃在二月中發布。
Drizzle
Drizzle可被認為是鍵/值存儲要解決的問題的反向方案。Drizzle誕生于MySQL(6.0)關系數據庫的拆分。在過去幾個月里,它的開發者已經移走了大量非核心的功能(包括視圖、觸發器、已編譯語句、存儲過程、查詢緩沖、ACL以及一些數據類型),其目標是要建立一個更精簡、更快的數據庫系統。Drizzle 仍能存放關系數據;正如MySQL/Sun的Brian Aker所說那樣:“沒理由潑洗澡水時連孩子也倒掉”。它的目標就是,針對運行于16核(或以上)系統上的以網絡和云為基礎的應用,建立一個半關系型數據庫平臺。
決策
最終,有四條理由支持你為應用選擇非關系式的鍵/值數據庫平臺:
1. 你的數據很大程度上是面向文檔的,使得它比關系數據庫更自然地適合于鍵/值數據模型。
2. 你的開發環境嚴重地面向對象時,鍵/值數據庫能盡量減少對“管道”代碼的需求。
3. 數據存儲很廉價,易于集成進供應商的網絡服務平臺。
4. 你優先考慮的是隨需應變的高端可擴性 -- 也就是說,那種通過簡單的擴充所無法獲得的大規模、分布式的可擴性。
但是在作決定的時候,要記得這種數據庫的限制,以及從關系式大路出走時所面臨的風險。
對于其他需求而言,你也許在RDBMS那里能得到***的滿足。因此,關系數據庫的死期是不是到了?顯然不是。嗯,至少還沒有。
原文:Is the Relational Database Doomed?
【編輯推薦】














