













關系數據庫的全景圖
這篇文章討論了關系型數據庫內部的索引和事務是如何工作的,而不深入研究特定數據庫的怪癖。我將涵蓋您應該了解的關于RDBMS索引的一切。我將簡要涉及事務和隔離級別,以及它們如何影響對特定事務的推理。
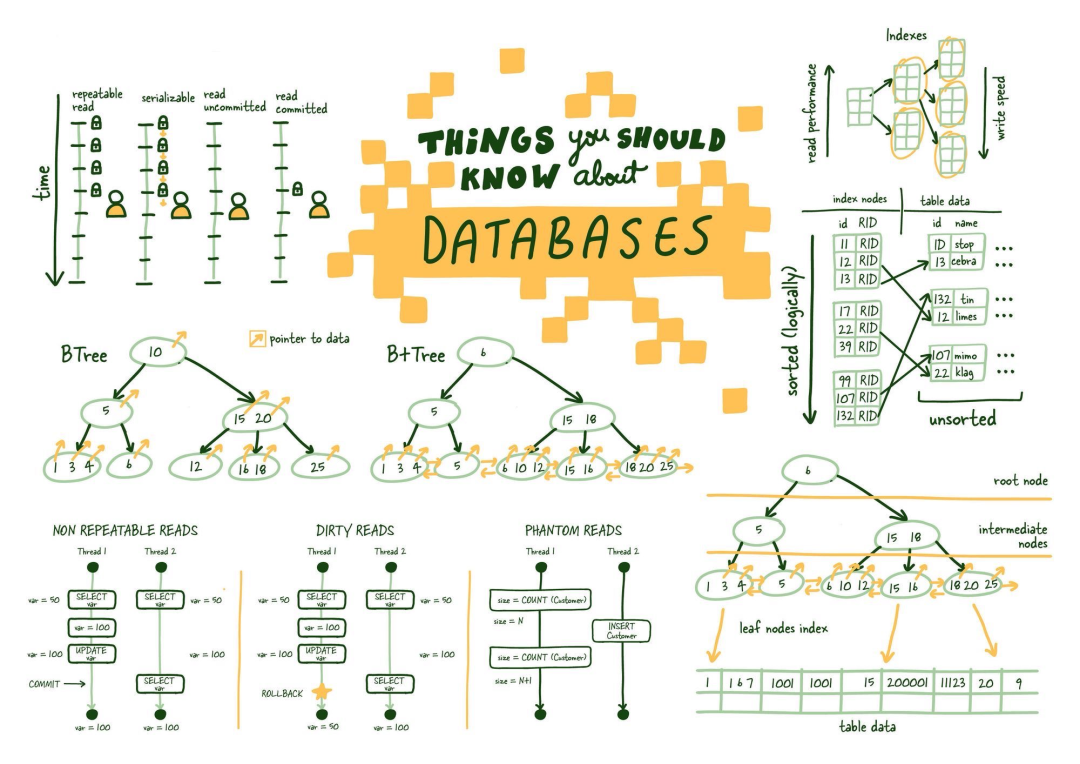
圖1.0 關系型數據庫解釋信息圖
1.什么是RDBMS?
關系型數據庫管理系統(RDBMS)是一種用于管理結構化數據的軟件。它使用表格來存儲數據,并支持SQL(Structured Query Language)進行數據檢索和操作。RDBMS是一種常見的數據庫類型,包括MySQL、PostgreSQL、Oracle、SQL Server等。
2.什么是索引?
索引是一種數據結構,用于降低請求數據的查找時間。索引通過額外的存儲、內存和維護成本(寫入速度較慢)來實現這一點,使我們能夠跳過檢查每個表行的繁瑣任務。
就像教科書后面的索引一樣,它可以幫助你找到正確的頁。我不是書的愛好者,但當我們深入研究數據庫索引時,它是一個很好的引入主題的方式。
3.為什么我們需要索引?
小量的數據是可以管理的,但是當它們變得更大時(比如大城市的出生登記簿),事情就變得不那么簡單了。一切原來快速的東西變得更慢,太慢。
想象一下,如果您不得不在1頁上查找某些內容,與在千頁的名單上查找相比,您的策略會發生什么變化。不,認真地,請花一秒鐘思考一下。
不管您想出什么好策略,某個數據庫幾乎在某個時候都實現了您能想到的所有好策略。隨著它們的增長,系統會收集和存儲更多的數據,最終導致上述問題。
我們需要索引來幫助我們盡快獲取我們需要的相關數據。
4.索引是如何工作的?
隨著數據的索引化,讀取性能會提高,但這會以寫入性能為代價,因為您需要保持索引的最新。因此,經常會提出的一個解決方案問題是按照您希望搜索的方式對數據進行邏輯排序。這意味著如果要按名稱搜索列表,您會按名字對列表進行排序。這種策略有一些問題。我主要將其作為讀者的問題提出:
- 如果要以多種方式搜索數據怎么辦?
- 如何處理將新數據添加到列表中?這是否很快?
- 如何處理更新?
- 這些任務的O標記是多少?
不管您的原始策略如何,我們絕對需要一種方法來維護順序,以便我們可以快速獲取相關的無序數據(很快就會談到這一點)。
5.鏈表
我們希望在互聯網上建立最大的系統設計社區!我們希望您加入我們。您可以在Twitter上找到我們。您也可以在此處聯系作者,提供反饋。
讓我們來看看下面的圖1.1。
+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
+─────+─────────+──────────────+圖1.1 可以快速從磁盤讀取的小表格
底層數據在存儲中分散,沒有順序,似乎是隨機分配的。如今,大多數生產服務器都配備了SSD,但有些情況下,您可能需要使用(HDD)傳統硬盤,但老實說,這樣的情況越來越少,因為SSD的價格大幅下降。
6.SSD與HDD
現在,將這么多數據讀入內存非常快,相對來說也很容易進行掃描。那么,如果我們正在搜索的數據無法完全緩存在內存中,或者從磁盤讀取所有數據所需的時間太長呢?
+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+圖1.2 大表格,無法完全放入內存,分布在磁盤上
這就是大多數開發人員會遇到的問題 - 我以前遇到過這個問題;我們需要一些字典(哈希映射)以及一種無需掃描緩慢的磁盤、讀取大量塊的方式來查找我們需要的數據是否存在。
這些被稱為索引葉節點,它們會指定一個要索引的特定列,它們可以存儲匹配行的位置。
這些索引葉節點是索引列和相應行位于磁盤上的位置之間的映射。這使我們能夠快速找到特定行,如果您引用它,就是索引列。掃描索引可以更快,因為它是要搜索的列的緊湊表示(字節更少),它可以節省您讀取大量塊以查找請求的數據所需的時間,并且更方便緩存,進一步加速整個過程。
數據規模常常適得其反,平衡樹是應對之的第一工具。
這些索引葉節點大小均勻,我們試圖盡可能多地存儲這些葉節點。由于這種結構要求事物在邏輯上進行排序(不是在物理上排列在磁盤上),我們需要解決快速添加和刪除數據的問題;好的老式雙向鏈表管理這一點,更具體地說,是雙向鏈表。
7.數據塊
這里的好處有兩方面:它允許我們前向和后向讀取索引葉節點,以及當我們刪除或添加新行時,快速重建索引結構,因為我們只是修改指針 - 強大的東西。
8.鏈接列表
由于這些葉節點在磁盤上物理上未按順序排列(請記住,指針維護雙向鏈表的排序),我們需要一種方法來獲取正確的索引葉節點。
(1) 平衡樹(B-Tree)
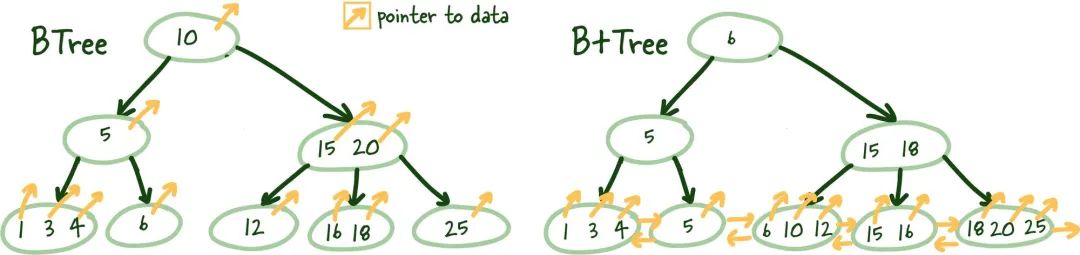
圖1.3 結構差異:B樹與B+樹
這使您可能會想知道,您在學校討厭的B樹中犯了什么大錯誤。我明白這些東西很無聊,但它們很強大,值得理解。
B+樹允許我們構建一個樹結構,其中每個中間節點指向其各自葉節點的最高節點值。這為我們提供了一種找到將指向所需數據的索引葉節點的明確路徑的方法。
這個結構是從底層開始構建的,以便中間節點覆蓋所有葉節點,直到達到頂部的根節點。這個樹結構之所以被稱為“平衡”,是因為整個樹的深度是統一的。
(2) B-樹與B+樹
9.對數可擴展性
我想在這里簡要提一下這個結構的威力。當然,大多數開發人員都意識到數據的指數增長以及理想情況下,您公司的估值。但不幸的是,數據規模常常與您作對,而平衡樹是應對之的第一工具。
根據中間節點可以引用的項目數(M)以及整個樹(N)的深度,我們可以引用M到N個對象。
下表以M值為5來說明了這個概念。
因此,隨著索引葉節點數量呈指數增長,樹的高度相對于索引葉節點數量的增長速度非常慢(對數增長),再加上平衡樹的高度,幾乎可以立即找到指向實際磁盤上的相關索引葉節點。這與數據庫相比是一個非常快的速度。
不是美麗的景象嗎?
10.什么是事務?
事務是您希望將其視為單個單位的工作。因此,它必須完全發生或完全不發生。我認為大多數系統不需要手動管理事務,但也有一些情況下,增加的靈活性對于實現所需的效果非常重要。事務主要涉及ACID中的I,即隔離。
11.什么是ACID?
這些可以自動為您執行,以便您甚至不知道它們正在發生,或者您可以像下面這樣手動創建它們:
-- 手動事務與提交。
BEGIN;
SELECT * FROM people WHERE id =1;
COMMIT or ROLLBACK;圖1.3 如何創建手動事務
我們將重點關注BEGIN和COMMIT或ROLLBACK之間的時間,以及對相同數據進行操作的其他各種事務發生了什么。
(1) 提交/回滾
(2) 讀現象
在這些隔離級別中可能會發生多種讀取現象,了解它們對于調試系統并誠實地幫助理解系統可以容忍什么樣的不一致非常重要。
(3) 不可重復讀
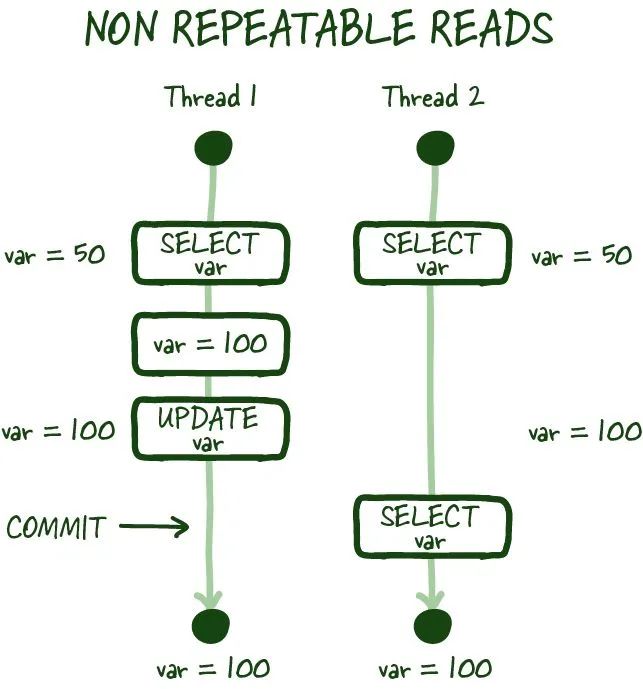
Databases-08.jpeg
就像上圖所示,不可重復讀取是指在事務期間連續兩次讀取數據時,您無法獲取一致的數據視圖。在特定模式下,可以進行并發數據庫修改,并且可能會發生您剛剛讀取的值被修改的情況,從而導致不可重復讀取。
(4) 臟讀
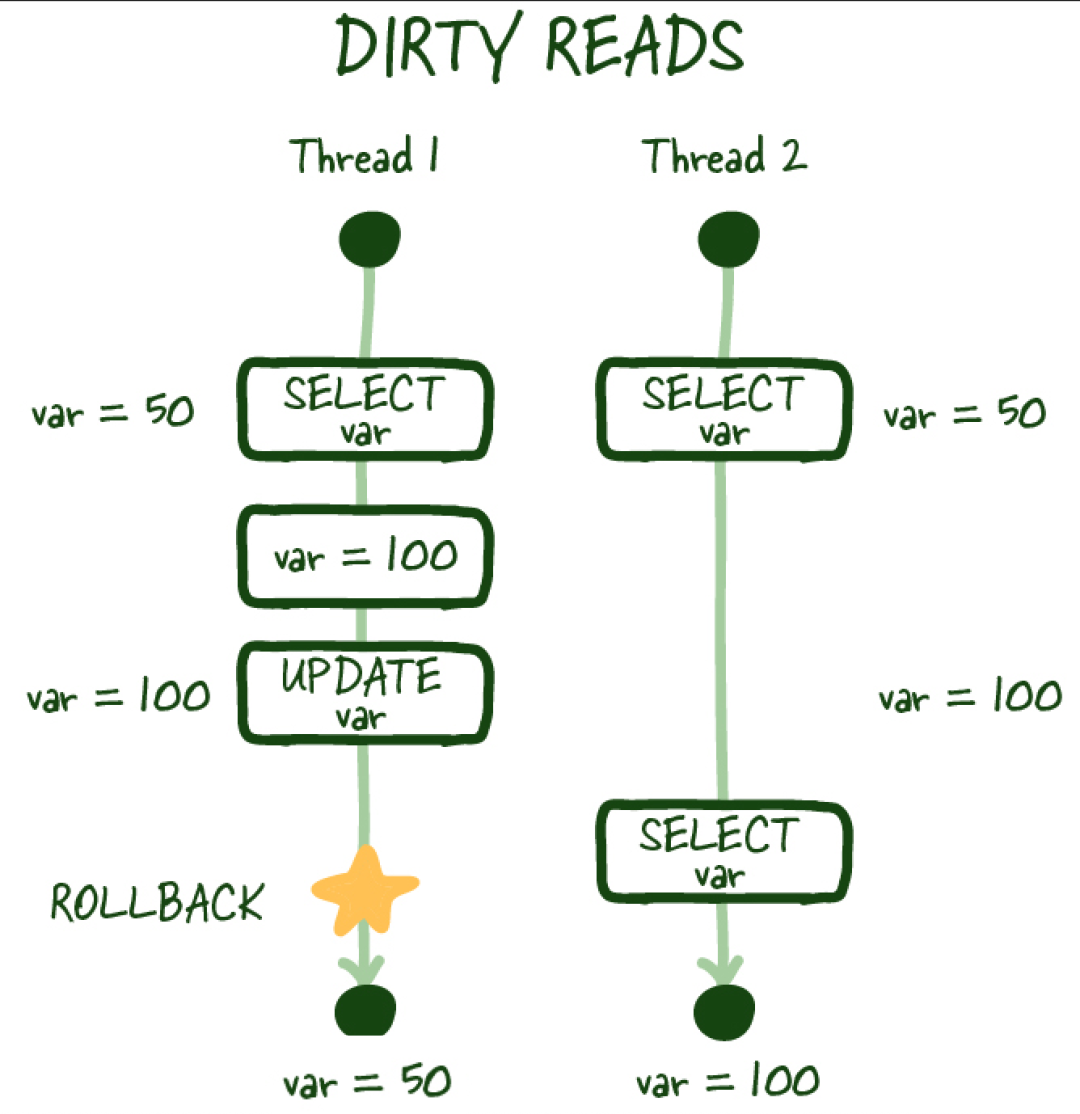
Image.png
類似地,臟讀取是指您執行讀取,另一個事務更新相同行但沒有提交工作,然后執行另一次讀取,您可以訪問未提交(臟)值,這不是持久的狀態更改,也與數據庫的狀態不一致。
(5) 幽靈讀
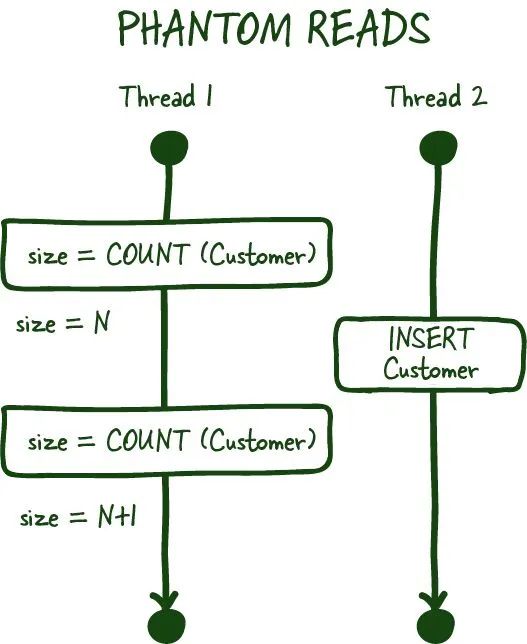
Databases-10.jpeg
幽靈讀取是另一種已提交的讀取現象,它發生在您主要處理聚合時。例如,您要求特定事務中的客戶數量。在連續兩次讀取之間,另一位客戶注冊或刪除他們的帳戶(已提交),這會導致您獲取到兩個不同的值,如果您的數據庫不支持這些事務的范圍鎖,則可能會發生這種情況。
(6) 范圍鎖
(7) 隔離級別
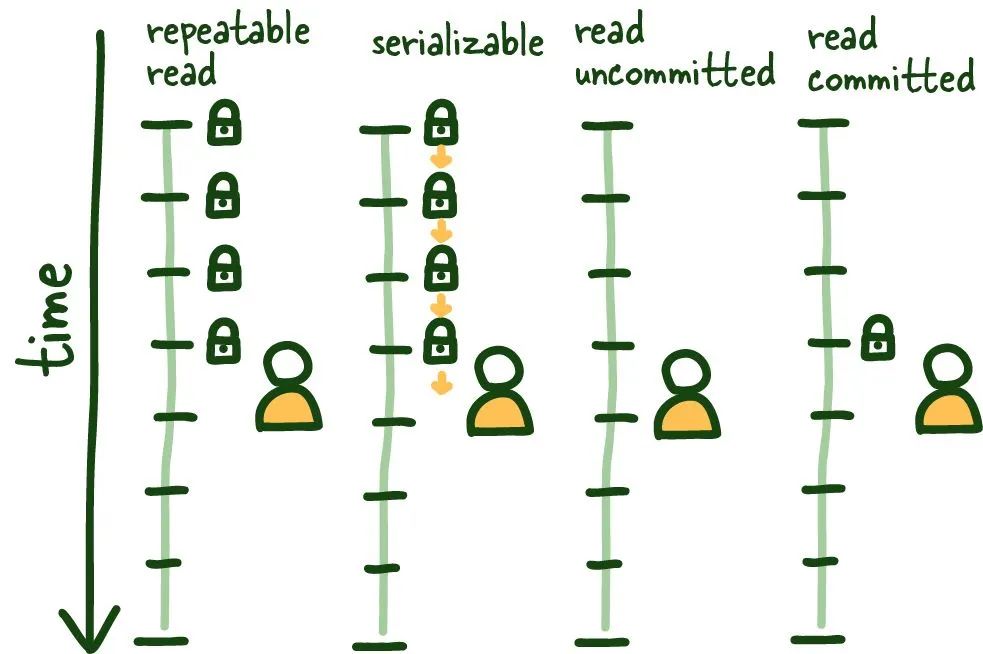
Databases-05-2.jpeg
SQL標準定義了4種標準隔離級別,這些級別可以并且應該在全局配置(如果不能可靠地推斷隔離級別,可能會發生潛在問題)。
(8) 可重復讀
讓我們從可重復讀開始。這很容易理解,并為其他隔離級別奠定了基礎。此隔離級別確保在第一次讀取建立的事務內進行一致讀取。此視圖以多種方式維護;某些方式會影響整個系統的性能,而其他方式不會,但不在本文的范圍內。
請參考上面的圖形;一旦我們進行了第一次讀取,該視圖將在事務持續期間被鎖定,因此在此事務的上下文之外發生的任何事情都無關緊要,無論是已提交還是未提交。
這種隔離級別保護我們免受多種已知的隔離問題的影響,主要是不可重復讀和臟讀。它確實有一些輕微的數據不一致,因為它被鎖定在特定數據庫視圖,因此在此鎖定期間的數據不相關;在此期間,保持事務盡可能短是有益的。
(9) 可串行化
這種操作模式可以是最受限制和一致的,因為它只允許一次運行一個查詢。
由于數據庫依次運行查詢,從一個穩定狀態過渡到下一個,因此不再可能發生所有類型的讀取現象。當然,這里還有更多細節,但大致如此。
重要的是要注意,在這種模式下需要一些重試機制,因為由于并發問題,查詢可能會失敗。
較新的分布式數據庫利用此隔離級別以實現一致性保證。 CockroachDB 就是這樣的數據庫的一個例子。值得一看。
(10) 讀已提交
這種隔離模式不同于可重復讀,因為每次讀取都會創建自己的一致(已提交)時間快照。因此,如果我們在同一事務中執行多次讀取,這種隔離級別容易受到幽靈讀的影響。
(11) 讀未提交
另一種是讀未提交隔離級別,它不維護任何事務鎖定,并可以看到正在發生的未提交數據,從而導致臟讀。在某些系統中,這是噩夢中的東西。
這就是關于數據庫的你應該了解的事情。














