通過分區(qū)(Partition)提升MySQL性能
什么是數(shù)據(jù)庫分區(qū)?
數(shù)據(jù)庫分區(qū)是一種物理數(shù)據(jù)庫設(shè)計(jì)技術(shù),DBA和數(shù)據(jù)庫建模人員對(duì)其相當(dāng)熟悉。雖然分區(qū)技術(shù)可以實(shí)現(xiàn)很多效果,但其主要目的是為了在特定的SQL操作中減少數(shù)據(jù)讀寫的總量以縮減響應(yīng)時(shí)間。
分區(qū)主要有兩種形式://這里一定要注意行和列的概念(row是行,column是列)
1. 水平分區(qū)(Horizontal Partitioning)這種形式分區(qū)是對(duì)表的行進(jìn)行分區(qū),通過這樣的方式不同分組里面的物理列分割的數(shù)據(jù)集得以組合,從而進(jìn)行個(gè)體分割(單分區(qū))或集體分割(1個(gè)或多個(gè)分區(qū))。所有在表中定義的列在每個(gè)數(shù)據(jù)集中都能找到,所以表的特性依然得以保持。
舉個(gè)簡單例子:一個(gè)包含十年發(fā)票記錄的表可以被分區(qū)為十個(gè)不同的分區(qū),每個(gè)分區(qū)包含的是其中一年的記錄。(朋奕注:這里具體使用的分區(qū)方式我們后面再說,可以先說一點(diǎn),一定要通過某個(gè)屬性列來分割,譬如這里使用的列就是年份)
2. 垂直分區(qū)(Vertical Partitioning) 這種分區(qū)方式一般來說是通過對(duì)表的垂直劃分來減少目標(biāo)表的寬度,使某些特定的列 被劃分到特定的分區(qū),每個(gè)分區(qū)都包含了其中的列所對(duì)應(yīng)的行。
舉個(gè)簡單例子:一個(gè)包含了大text和BLOB列的表,這些text和BLOB列又不經(jīng)常被訪問,這時(shí)候就要把這些不經(jīng)常使用的text和BLOB了劃分到另一個(gè)分區(qū),在保證它們數(shù)據(jù)相關(guān)性的同時(shí)還能提高訪問速度。
在數(shù)據(jù)庫供應(yīng)商開始在他們的數(shù)據(jù)庫引擎中建立分區(qū)(主要是水平分區(qū))時(shí),DBA和建模者必須設(shè)計(jì)好表的物理分區(qū)結(jié)構(gòu),不要保存冗余的數(shù)據(jù)(不同表中同時(shí)都包含父表中的數(shù)據(jù))或相互聯(lián)結(jié)成一個(gè)邏輯父對(duì)象(通常是視圖)。這種做法會(huì)使水平分區(qū)的大部分功能失效,有時(shí)候也會(huì)對(duì)垂直分區(qū)產(chǎn)生影響。
在MySQL 5.1中進(jìn)行分區(qū)
MySQL5.1中最激動(dòng)人心的新特性應(yīng)該就是對(duì)水平分區(qū)的支持了。這對(duì)MySQL的使用者來說確實(shí)是個(gè)好消息,而且她已經(jīng)支持分區(qū)大部分模式:
Range(范圍) – 這種模式允許DBA將數(shù)據(jù)劃分不同范圍。例如DBA可以將一個(gè)表通過年份劃分成三個(gè)分區(qū),80年代(1980’s)的數(shù)據(jù),90年代(1990’s)的數(shù)據(jù)以及任何在2000年(包括2000年)后的數(shù)據(jù)。
Hash(哈希) – 這中模式允許DBA通過對(duì)表的一個(gè)或多個(gè)列的Hash Key進(jìn)行計(jì)算,***通過這個(gè)Hash碼不同數(shù)值對(duì)應(yīng)的數(shù)據(jù)區(qū)域進(jìn)行分區(qū),。例如DBA可以建立一個(gè)對(duì)表主鍵進(jìn)行分區(qū)的表。
Key(鍵值) – 上面Hash模式的一種延伸,這里的Hash Key是MySQL系統(tǒng)產(chǎn)生的。
List(預(yù)定義列表) – 這種模式允許系統(tǒng)通過DBA定義的列表的值所對(duì)應(yīng)的行數(shù)據(jù)進(jìn)行分割。例如:DBA建立了一個(gè)橫跨三個(gè)分區(qū)的表,分別根據(jù)2004年2005年和2006年值所對(duì)應(yīng)的數(shù)據(jù)。
Composite(復(fù)合模式) - 很神秘吧,哈哈,其實(shí)是以上模式的組合使用而已,就不解釋了。舉例:在初始化已經(jīng)進(jìn)行了Range范圍分區(qū)的表上,我們可以對(duì)其中一個(gè)分區(qū)再進(jìn)行hash哈希分區(qū)。
分區(qū)帶來的好處太多太多了,有多少?俺也不知道,自己猜去吧,要是覺得沒有多少就別用,反正俺也不求你用。不過在這里俺強(qiáng)調(diào)兩點(diǎn)好處:
性能的提升(Increased performance) - 在掃描操作中,如果MySQL的優(yōu)化器知道哪個(gè)分區(qū)中才包含特定查詢中需要的數(shù)據(jù),它就能直接去掃描那些分區(qū)的數(shù)據(jù),而不用浪費(fèi)很多時(shí)間掃描不需要的地方了。需要舉個(gè)例子?好啊,百萬行的表劃分為10個(gè)分區(qū),每個(gè)分區(qū)就包含十萬行數(shù)據(jù),那么查詢分區(qū)需要的時(shí)間僅僅是全表掃描的十分之一了,很明顯的對(duì)比。同時(shí)對(duì)十萬行的表建立索引的速度也會(huì)比百萬行的快得多得多。如果你能把這些分區(qū)建立在不同的磁盤上,這時(shí)候的I/O讀寫速度就“不堪設(shè)想”(沒用錯(cuò)詞,真的太快了,理論上100倍的速度提升啊,這是多么快的響應(yīng)速度啊,所以有點(diǎn)不堪設(shè)想了)了。
對(duì)數(shù)據(jù)管理的簡化(Simplified data management) - 分區(qū)技術(shù)可以讓DBA對(duì)數(shù)據(jù)的管理能力提升。通過優(yōu)良的分區(qū),DBA可以簡化特定數(shù)據(jù)操作的執(zhí)行方式。例如:DBA在對(duì)某些分區(qū)的內(nèi)容進(jìn)行刪除的同時(shí)能保證余下的分區(qū)的數(shù)據(jù)完整性(這是跟對(duì)表的數(shù)據(jù)刪除這種大動(dòng)作做比較的)。
此外分區(qū)是由MySQL系統(tǒng)直接管理的,DBA不需要手工的去劃分和維護(hù)。例如:這個(gè)例如沒意思,不講了,如果你是DBA,只要你劃分了分區(qū),以后你就不用管了就是了。
站在性能設(shè)計(jì)的觀點(diǎn)上,俺們對(duì)以上的內(nèi)容也是相當(dāng)感興趣滴。通過使用分區(qū)和對(duì)不同的SQL操作的匹配設(shè)計(jì),數(shù)據(jù)庫的性能一定能獲得巨大提升。下面咱們一起用用這個(gè)MySQL 5.1的新功能看看。
下面所有的測試都在Dell Optiplex box with a Pentium 4 3.00GHz processor, 1GB of RAM機(jī)器上(炫耀啊……),F(xiàn)edora Core 4和MySQL 5.1.6 alpha上運(yùn)行通過。
如何進(jìn)行實(shí)際分區(qū)
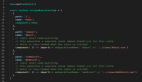
看看分區(qū)的實(shí)際效果吧。我們建立幾個(gè)同樣的MyISAM引擎的表,包含日期敏感的數(shù)據(jù),但只對(duì)其中一個(gè)分區(qū)。分區(qū)的表(表名為part_tab)我們采用Range范圍分區(qū)模式,通過年份進(jìn)行分區(qū):
|
注意到了這里的***一行嗎?這里把不屬于前面年度劃分的年份范圍都包含了,這樣才能保證數(shù)據(jù)不會(huì)出錯(cuò),大家以后要記住啊,不然數(shù)據(jù)庫無緣無故出錯(cuò)你就爽了。那下面我們建立沒有分區(qū)的表(表名為no_part_tab):
|
下面咱寫一個(gè)存儲(chǔ)過程(感謝Peter Gulutzan給的代碼,如果大家需要Peter Gulutzan的存儲(chǔ)過程教程的中文翻譯也可以跟我要,chenpengyi◎gmail.com),它能向咱剛才建立的已分區(qū)的表中平均的向每個(gè)分區(qū)插入共8百萬條不同的數(shù)據(jù)。填滿后,咱就給沒分區(qū)的克隆表中插入相同的數(shù)據(jù):
|
表都準(zhǔn)備好了。咱開始對(duì)這兩表中的數(shù)據(jù)進(jìn)行簡單的范圍查詢吧。先分區(qū)了的,后沒分區(qū)的,跟著有執(zhí)行過程解析(MySQL Explain命令解析器),可以看到MySQL做了什么:
- mysql> select count(*) from no_part_tab where
- -> c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
- +———-+
- | count(*) |
- +———-+
- | 795181 |
- +———-+
- 1 row in set (38.30 sec)
- mysql> select count(*) from part_tab where
- -> c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
- +———-+
- | count(*) |
- +———-+
- | 795181 |
- +———-+
- 1 row in set (3.88 sec)
- mysql> explain select count(*) from no_part_tab where
- -> c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: no_part_tab
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 8000000
- Extra: Using where
- 1 row in set (0.00 sec)
- mysql> explain partitions select count(*) from part_tab where
- -> c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: part_tab
- partitions: p1
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 798458
- Extra: Using where
- 1 row in set (0.00 sec)
從上面結(jié)果可以容易看出,設(shè)計(jì)恰當(dāng)表分區(qū)能比非分區(qū)的減少90%的響應(yīng)時(shí)間。而命令解析Explain程序也告訴我們在對(duì)已分區(qū)的表的查詢過程中僅對(duì)***個(gè)分區(qū)進(jìn)行了掃描,其他都跳過了。
嗶厲吧拉,說阿說……反正就是這個(gè)分區(qū)功能對(duì)DBA很有用拉,特別對(duì)VLDB和需要快速反應(yīng)的系統(tǒng)。
對(duì)Vertical Partitioning的一些看法
雖然MySQL 5.1自動(dòng)實(shí)現(xiàn)了水平分區(qū),但在設(shè)計(jì)數(shù)據(jù)庫的時(shí)候不要輕視垂直分區(qū)。雖然要手工去實(shí)現(xiàn)垂直分區(qū),但在特定場合下你會(huì)收益不少的。例如在前面建立的表中,VARCHAR字段是你平常很少引用的,那么對(duì)它進(jìn)行垂直分區(qū)會(huì)不會(huì)提升速度呢?咱們看看測試結(jié)果:
- mysql> desc part_tab;
- +——-+————-+——+—–+———+——-+
- | Field | Type | Null | Key | Default | Extra |
- +——-+————-+——+—–+———+——-+
- | c1 | int(11) | YES | | NULL | |
- | c2 | varchar(30) | YES | | NULL | |
- | c3 | date | YES | | NULL | |
- +——-+————-+——+—–+———+——-+
- 3 rows in set (0.03 sec)
- mysql> alter table part_tab drop column c2;
- Query OK, 8000000 rows affected (42.20 sec)
- Records: 8000000 Duplicates: 0 Warnings: 0
- mysql> desc part_tab;
- +——-+———+——+—–+———+——-+
- | Field | Type | Null | Key | Default | Extra |
- +——-+———+——+—–+———+——-+
- | c1 | int(11) | YES | | NULL | |
- | c3 | date | YES | | NULL | |
- +——-+———+——+—–+———+——-+
- 2 rows in set (0.00 sec)
- mysql> select count(*) from part_tab where
- -> c3 > date ‘1995-01-01′ and c3 < date ‘1995-12-31′;
- +———-+
- | count(*) |
- +———-+
- | 795181 |
- +———-+
- 1 row in set (0.34 sec)
在設(shè)計(jì)上去掉了VARCHAR字段后,不止是你,俺也發(fā)現(xiàn)查詢響應(yīng)速度上獲得了另一個(gè)90%的時(shí)間節(jié)省。所以大家在設(shè)計(jì)表的時(shí)候,一定要考慮,表中的字段是否真正關(guān)聯(lián),又是否在你的查詢中有用?
補(bǔ)充說明
這么簡單的文章肯定不能說全MySQL 5.1 分區(qū)機(jī)制的所有好處和要點(diǎn)(雖然對(duì)自己寫文章水平很有信心),下面就說幾個(gè)感興趣的:
◆支持所有存儲(chǔ)引擎(MyISAM, Archive, InnoDB, 等等)
◆ 對(duì)分區(qū)的表支持索引,包括本地索引local indexes,對(duì)其進(jìn)行的是一對(duì)一的視圖鏡像,假設(shè)一個(gè)表有十個(gè)分區(qū),那么其本地索引也包含十個(gè)分區(qū)。
◆關(guān)于分區(qū)的元數(shù)據(jù)Metadata的表可以在INFORMATION_SCHEMA數(shù)據(jù)庫中找到,表名為PARTITIONS。
◆All SHOW 命令支持返回分區(qū)表以及元數(shù)據(jù)的索引。
◆對(duì)其操作的命令和實(shí)現(xiàn)的維護(hù)功能有(比對(duì)全表的操作還多):
|
站在性能主導(dǎo)的觀點(diǎn)上來說,MySQL 5.1的分區(qū)功能能給數(shù)據(jù)性能帶來巨大的提升的同時(shí)減輕DBA的管理負(fù)擔(dān),如果分區(qū)合理的話。如果需要更多的資料可以去http://dev.mysql.com/doc/refman/5.1/en/partitioning.html或 http://forums.mysql.com/list.php?106獲得相關(guān)資料。
【編輯推薦】