













對比SQL中簡單嵌套查詢與非嵌套查詢的異同
本文將討論的是SQL中簡單嵌套查詢與非嵌套查詢的異同,通過這些來更加深刻理解SQL語句。
某天的工作是修復某個項目的bug,接著就發現,其sql極其混亂,有非常多的left join和in操作,還有嵌套查詢(只有一個表的嵌套查詢)。不知道看到過哪里的資料說,嵌套查詢速度慢,于是我把全部嵌套查詢都改成join的形式,嵌套查詢里面的where條件,我都寫到join...on后面去了。突然一個想法冒出來:篩選條件跟在join...on后面 和 跟在整個sql語句***面的where后面有什么區別呢?還有嵌套查詢真的慢么?于是便有下面的測試產生,數據庫環境為MS SQL 2005。
一,inner join
先看看非嵌套查詢:
- a.select * from t1
- inner join t2 on t1.id = t2.id
- inner join t3 on t1.id = t3.id
- where t1.a=1 and t2.b=1 and t3.c=1
- b.select * from t1
- inner join t2 on t1.id = t2.id and t2.b=1
- inner join t3 on t1.id = t3.id
- where t1.a=1 and t3.c=1
- c.select * from t1
- inner join t2 on t1.id = t2.id and t2.b=1
- inner join t3 on t1.id = t3.id and t3.c=1
- where t1.a=1
在上面三個非嵌套查詢,讓“and t2.b=1”和“and t3.c=1”分別在join...on和where之間游走,用Management Studio選中“包含實際的執行計劃”并執行這三條語句,都得出下面這個執行計劃。
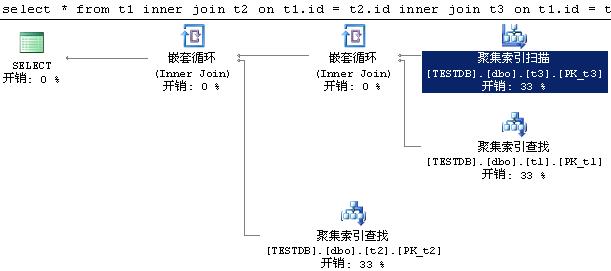
三個“聚集索引掃描”的謂詞從上到下分別是:
1.t3.c=1
2.t1.a=1 (seek謂詞:t1.id=t3.id)
3.t2.b=1 (seek謂詞:t2.id=t3.id)
故可以認為:在MS SQL2005中,條件跟在join...on后面 和 跟在where后面是等價的。
接著看嵌套查詢:
- d.select * from t1
- inner join (select * from t2 where t2.b=1)a on t1.id=a.id
- inner join t3 on t1.id = t3.id
- where t1.a=1 and t3.c=1
- e.select * from t1
- inner join (select * from t2 where t2.b=1)a on t1.id=a.id
- inner join (select * from t3 where t3.c=1)b on t1.id=b.id
- where t1.a=1
- f.elect * from t1
- inner join (select t3.id,t2.b,t3.c from t3 inner join t2 on t2.id = t3.id where t2.b=1 and t3.c=1)a on t1.id=a.id
- where t1.a=1
***句sql語句把t2的查詢變成子查詢,第二句sql語句把t2,t3分別變成子查詢,第三句把t2和t3的查詢合成一個子查詢,再看看實際的執行計劃:
跟上面非嵌套查詢的執行計劃一模一樣。
故可以認為:簡單(注意是簡單的,復雜的情況得另外考慮)嵌套查詢和其相對應的非嵌套查詢形式,執行效率是一樣的(網上一些文章指出這是MS SQL優化器針對這些嵌套查詢進行了優化)。
接著,在上面兩個執行計劃的圖中又發現一個小問題,為什么明明是select t1 inner join t2 inner join t3,執行計劃卻把t1和t3先inner join(t1.id = t3.id)再跟t2 inner join(t2.id = t3.id)起來?
經過三個表,四個表,五個表進行連接測試,發現這些順序都是不確定的。很可能這些順序是根據SQL優化器內的算法所決定的,由于沒有源代碼,所以無從考究。
(感謝Keep Walking的補充:
數量級,索引,統計的不同都可以導致順序變化”。
PS:
1.經測試,在join on后面t1.id = t2.id與t2.id = t1.id等價
如果發現這文章有錯誤,歡迎指出。
原文標題:SQL語句分析:ON與WHERE的比較_簡單嵌套查詢與非嵌套查詢的比較
鏈接:http://www.cnblogs.com/StephenHuang/archive/2010/01/03/1637846.html
【編輯推薦】













