













詳解Oracle RAC入門和提高
本文將詳細講述Oracle RAC入門和提高,希望對廣大Oracle數據庫管理人員以及致力于學習Oracle數據庫的管理人有所幫助。
Oracle RAC 產品概述
Oracle Real Application Server,真正應用集群,簡稱Oracle RAC ,是Oracle的并行集群,位于不同服務器系統的Oracle實例同時訪問同一個Oracle數據庫,節點之間通過私有網絡進行通信,所有的控制文件、聯機日志和數據文件存放在共享的設備上,能夠被集群中的所有節點同時讀寫。其系統架構如下圖:
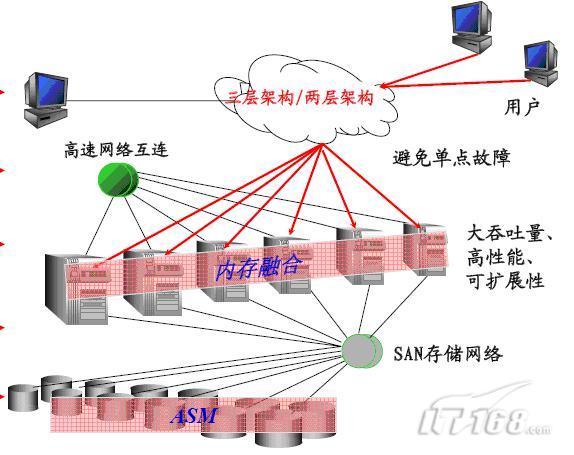
RAC提供的好處包括:
(1)多節點負載均衡;
(2)提供高可用:故障容錯和無縫切換功能,將硬件和軟件錯誤造成的影響最小化,下表是RAC與傳統的雙機熱備方式切換時間的對比:
(3)通過并行執行技術提高事務響應時間----通常用于數據分析系統;
(4)通過橫向擴展提高每秒交易數和連接數 ;----通常對于聯機事務系統;
(5)節約硬件成本,可以用多個廉價PC服務器代替昂貴的小型機或大型機,同時節約相應維護成本;
(6)可擴展性好,可以方便添加刪除節點,擴展硬件資源;
RAC的缺點有:
相對單機,管理更復雜,要求更高;
在系統規劃設計較差時性能甚至不如單節點;
可能會增加軟件成本(如果使用高配置的pc服務器,Oracle一般按照CPU個數收費)
在Oracle9i之前,RAC的名稱是OPS (Oracle parallel Server)。RAC 與 OPS 之間的一個較大區別是,RAC采用了Cache Fusion(高速緩存合并)技術。在 OPS 中,節點間的數據請求需要先將數據寫入磁盤,然后發出請求的節點才可以讀取該數據。使用Cache fusion時,RAC的各個節點的數據緩沖區通過高速、低延遲的內部網絡進行數據塊的傳輸。
Oracle RAC在中國各行各業使用都比較廣泛,包括通信移動、金融服務、社會保障和電子商務等,據Oracle統計,2007財年中國有500多家企業使用Oracle實時應用集群,考慮到未登記信息,實際數字更高于這一數字。典型的用戶包括:中彩在線/OLTP/4節點/10gR2/AIX5.3、淘寶/DataWarehouse/4節點/10gR2/RHEL4、北京社保/6節點 /HP_Alpha/ MA8000、建行證券系統/2節點/IBM_P595/EMC_DMX3、上海電力/2節點/Alpha_GS160、廣東移動、山東網通等。
#p#
Oracle RAC/Clusterware的結構和組件
一、RAC主要組件, 軟硬件兩部分
(1) 服務器 >= 2
(2) 操作系統,推薦使用Oracle認證的系統;版本不要太老,也不要太新
(3) CPU/內存 根據業務需要,內存至少1G
(4) 本地磁盤空間,>=30G
(5) 網卡 >=2 ,推薦4個以上千兆網卡
(6) 私有以太網絡,推薦千兆交換機以上
(7) HBA卡 ,如果是SAN,推薦2個冗余HBA
(8) 共享存儲設備,推薦SAN設備
(9) 存儲管理, ASM/Cluster LV/裸分區/CFS,不推薦用OCFS,卷管理軟件、多路徑軟件等
(10) 第三方集群軟件: 可選
(11) Oracle Clusterware 軟件
(12) Oracle RDBMS 軟件
二、Clusterware主要進程
(1)crsd: 負責管理集群的高可用操作。管理的crs資源包括數據庫、實例、監聽、虛擬IP,ons,gds或者其他,操作包括啟動、關閉、監控及故障切換。改進程由root用戶管理和啟動。crsd如果有故障會導致系統重啟。
(2)cssd,管理各節點的關系,用于節點間通信,節點在加入或離開集群時通知集群。該進程由oracle用戶運行管理。發生故障時cssd也會自動重啟系統。
(3)oprocd – 集群進程管理 —Process monitor for the cluster. 用于保護共享數據IO fencing。
僅在沒有使用vendor的集群軟件狀態下運行
(4)evmd :事件檢測進程,由oracle用戶運行管理
三、Clusterware使用的共享設備
(1) Oracle Cluster Registry(OCR):記錄集群的配置信息;
(2) Voting disk : 即投票盤,保存節點的成員信息,當配置多個投票盤的時候個數必須為奇數,每個節點必須同時能夠連接半數以上的投票盤才能夠存活;
四、安裝路徑的選擇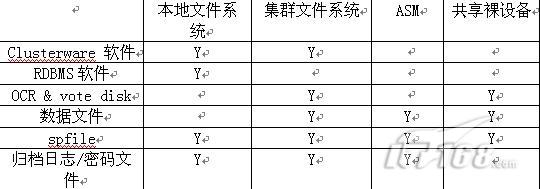
注:
(1)在Oracle RAC中,軟件不建議安裝在共享文件系統上;包括CRS_HOME和ORACLE_HOME,尤其是CRS軟件,推薦安裝在本地文件系統中,這樣在進行軟件升級,以及安裝patch和patchset的時候可以使用滾動升級(rolling upgrade)的方式,減少計劃當機時間。另外如果軟件安裝在共享文件系統也會增加單一故障點。
(2)如果使用ASM存儲,需要為asm單獨安裝ORACLE軟件,獨立的ORACLE_HOME,易于管理和維護,比如當遇到asm的bug需要安裝補丁時,就不會影響RDBMS文件和軟件。
(3)在Oracle 11gR2中將新增存儲選項:acfs (Oracle ASM Cluster File System)
第三方集群
在Oracle9i中,除了Windows和Linux,在安裝RAC之前必須先安裝vendor clusterware,即第三方集群,包括IBM的HACMP, HP的ServiceGuard for oracle RAC, Sun cluster,Veritas SFRAC等,這一類的集群軟件為Oracle RAC提供了下面的功能:
(1)共享的邏輯卷管理或者集群文件系統用于存放數據文件;
(2)提供了統一的集群的成員組管理;
(3)使用更健壯的SCSI-3 PGR機制來防止心跳故障(即裂腦split brain)導致的數據損壞,這種功能一般叫做IO fencing;
(4)提供效率更高的、更低延遲的心跳網絡用于cache fusion,可以相對減少TCP/IP的開銷,包括:
HP SGeRAC: HMP (Hyper Messaging Protocol),
Sun Cluster: RSM (Remote Shared Memory),
Veritas SFRAC: LLT (low-latency transport),
Compac True Cluster: RDG (reliable data grams);
通常如果要使用第三方集群的心跳協議,需要將$ORACLE_HOME/lib/libskgxpX.so文件替換為第三方集群
軟件提供的libskgxpX.so文件(其中X代表Oracle版本號9/10/11),skgxp 是System Kernel Generic Interface Inter-Process Communications的縮寫,是oracle開放的一個應用接口,用于傳輸GCS和GES 的數據。Oracle自帶的libskgxp文件定義的傳輸協議是UDP/IP。
5)提供擴展的容災方案,例如campus cluster/metro cluster/extended RAC;如下圖, 以Veritas的SFRAC為例,它提供兩種Oracle Extended RAC方案,方案一是使用Veritas Volume Manager對底層陣列進行鏡像,提供同城容災級別的實時數據保護;方案二使用GCO/VVR對數據庫進行數據復制,可以實現距離更遠、超過10km廣域網的容災;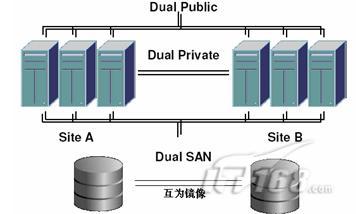
(6)Veritas SFRAC 還提供了以下特性:
補充的Oracle ODM,可以使Oracle同時擁有文件系統的易管理和裸設備的性能;
標準的多路徑軟件(DMP),不需要再安裝其他軟件就可支持絕大多數磁盤陣列,在異構SAN環境中有更好的兼容性;
從Oracle10g起,Oracle提供了自己的集群軟件,叫Oracle clusterware簡稱CRS,這個軟件是安裝oracle rac的前提,而上述第三方集群則成了安裝的可選項。同時提供了另外一個新特性叫做ASM,可以用于RAC下的共享磁盤設備的管理,還實現了數據文件的條帶化和鏡像,以提高性能和安全性 (S.A.M.E: stripe and mirror everything ) ,不再依賴第三方存儲軟件來搭建RAC系統。
那么Oracle是如何識別第三方集群的呢?
在安裝完第三方集群后,會在特定目錄下生成Oracle RAC接口文件,這個文件的作用就是上面的第二點功能:集群成員管理信息(cluster membership 簡稱CM)。在HPUX下該文件是/opt/nmapi/nmapi2/lib/pa20_64,在AIX/Solaris/Linux下這個文件是 /opt/ORCLcluster/lib/libskgxn2.so 。
當安裝CRS的的檢查階段,就會檢測是否有該文件,如果有的話,在安裝CRS過程中生成一個軟連接文件,文件名是ligskgxn2.so,指向上面的libskgxn2.so或pa20_64文件,這個軟連接的位置在CRS_HOME/lib/目錄;如果沒有第三方集群,那么CRS安裝過程中生成自己的libskgxn2.so文件。換句話說,在有第三方集群存在的情況下,CRS的集群成員信息是來自于第三方集群,兩套集群的成員信息保持一致和同步;沒有第三方集群情況時,CRS自己管理成員信息。
通過查詢$CRS_HOME/log/hostname/cssd/ocssd.log可以看到css識別到的第三方集群,下面的例子分別是HACMP、SFRAC、SunCluster、ServiceGuide :
- [CSSD]2008-05-27 15:09:43.456 [1029] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/IBM AIX skgxn)
- [CSSD]2008-12-30 21:44:56.172 [1029] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/Veritas Cluster Server MM
- [CSSD]2007-08-10 02:19:39.572 [3] >TRACE: clssnm_skgxninit: initialized skgxn version (2/2/Oracle Solaris UDLM)
- [CSSD]2006-09-29 18:57:53.323 [5] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/Hewlett-Packard SKGXN 2.0)
在9i/8i中沒有css/crs,該信息可以在后臺進程lmon的trace文件中得到(在bdump中);
在安裝Oracle 9i RAC/8i OPS的過程中,Oracle識別集群方法類似。
在多個平臺上,如果兩個節點沒有正確鏈接libskgxn2文件,可能會導致第二個實例無法mount或出現ORA-600錯誤。
Oracle支持的RAC環境
因為Oracle RAC本身比較復雜,在安裝和管理中可能會遇到各種問題,涉及到OS、RDBMS、Cluster軟件和網絡、主機、存儲等硬件,為了避免不必要的問題發生,在安裝之前,我們需要確認安裝環境是否滿足要求,包括軟件和硬件兩方面,尤其是Vendor clusterware和OS 的版本的兼容性需要注意,可以從metalink中得到最新的Oracle官方認證信息:登陸Metalink.oracle.com 選擇 Certify,選擇by product,選擇real application server,選擇對應平臺就可以得到。下面列出一些關于硬件和平臺支持的常見問題:
官方不支持的:Vmware, Sun LDOM ,Solaris Local Container/Zones
官方支持的: IBM LPAR, IBM VIOS(Virtual IO Server), Solaris Global Containers
RHEL GFS , ISCSI,
私有網絡(心跳線)的支持: 不支持使用交叉線,支持 Infiniband RDS (10gR2之后)
異構環境:支持不同的硬件、但相同的軟件(OS/Oracle)組成的集群,不支持32位與64位系統間的集群
目前支持的NFS的server包括:
EMC Celerra
Fujitsu Filer NR1000 Series
IBM N Series
NetApp FAS, F, G Series
Pillar Data Systems Axiom 500
Sun StorageTek 5000 Series
Oracle Clusterware的心跳
Oracle clusterware 使用兩種心跳設備來驗證成員的狀態,保證集群的完整性;一是對voting disk的心跳,ocssd進程每秒向votedisk寫入一條心跳信息;二是節點間的私有以太網的心跳,兩種心跳機制都有一個對應的超時時間,分別叫做 misscount和disktimeout:
misscount 用于定義節點間心跳通信的超時,單位為秒;
disktimeout ,默認200秒,定義css進程與vote disk連接的超時時間;
reboottime ,發生裂腦并且一個節點被踢出后,這個節點將在reboottime的時間內重啟;默認是3秒;
其中misscount默認值見下表
用下面的命令查看上述參數的實際值:
- 1. # crsctl get css misscount
- 2. # grep misscount $CRS_HOME/log/hostname/cssd/ocssd.log
- [CSSD]2008-11-27 22:29:42.397 [1] >TRACE: clssnmInitNMInfo: misscount set to 600
在下面兩種情況發生時,css會踢出節點來保證數據的完整,:
(1) Private Network IO time > misscount,會發生split brain即裂腦現象,產生多個“子集群”(subcluster) ,這些子集群進行投票來選擇哪個存活,踢出節點的原則按照下面的原則:
節點數目不一致的,節點數多的subcluster存活;節點數相同的,node ID小的節點存活。
(2) Vote Disk IO Time > disktimeout ,踢出節點原則如下:失去半數以上vote disk連接的節點將在reboottime的時間內重啟;例如有5個vote disk,當由于網絡或者存儲原因某個節點與其中>=3個vote disk連接超時時,該節點就會重啟。當一個或者兩個vote disk損壞時則不會影響集群的運行。
可以手工修改這三個參數的值,單位都是秒:(謹慎使用)
- $CRS_HOME/bin/crsctl set css misscount
- $CRS_HOME/bin/crsctl set css reboottime [-force]
- $CRS_HOME/bin/crsctl set css disktimeout [-force]
- 或者重新設置成默認值:crsctl unset css misscount
Clusterware的私有網絡
在Oracle 10g/11g中,Oracle的私有網絡(private network)包括clusterware的私有網絡和數據庫實例的私有網絡:
clusterware的私有網絡主要包括css數據的傳送,即用一種特殊的ping命令來檢測其他機器的狀態;
數據庫實例的私有網絡,包括RDMS和ASM的,用于cache fusion(GCS/GES)數據的傳輸。
當我們只使用一個私有網卡的時,同時傳送上面兩類的數據。如果我們在安裝時指定了兩個私有網卡,首先使用如下面$CRS_HOME/bin/oifcfg getif命令來得到所有網絡接口列表,這些信息保存在ocr中:
- # oifcfg getif
- en0 10.200.56.0 global public
- en3 192.168.3.0 global cluster_interconnect
- en5 192.168.5.0 global cluster_interconnect
情況會有所不同,clusterware的私有網絡,目前(10g/11g)只能使用一個網絡接口,對應于/etc/hosts中定義的private hostname的那個網卡,可以通過查看ocssd的log來確定:
當/etc/hosts 中定義private hostname為192.168.3.233時看到 :
- [ CSSD]2009-01-16 17:34:12.406 [1029] >TRACE: clssgmPeerListener: Listening on (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.3.233)(PORT=45527))
這個是與其他節點css進行通信的信息:
- [ CSSD]2009-01-16 17:36:27.463 [1029] >TRACE: clssgmConnectToNode:
- node 2 clsc (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.3.234)(PORT=37732)) - size 64 ver 1
當/etc/hosts 中定義private hostname為192.168.5.233時,css使用了另外一個網絡:
- [ CSSD]2009-01-16 18:59:56.411 [1029] >TRACE: clssgmPeerListener:
- Listening on (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.5.233)(PORT=50415))
Oracle實例的私有網絡
Oracle實例的心跳網絡使用方式的優先級從高到低如下:
(1) 如果使用了第三方集群的IPC,替換了對應$ORACLE_HOME/lib/libskgxnX.so文件,那么數據庫實例的cache fusion會使用對應的網絡協議,而忽略ocr中和數據庫初始化參數中cluster_interconnects的配置,下面的例子當中就使用了 VCSIPC,可以從對應的alert log中驗證:
- db_name = r10g
- open_cursors = 300
- pga_aggregate_target = 1237319680
- Fri Mar 13 14:00:35 2009
- Oracle instance running with ODM: Veritas 6.0 ODM Library, Version 1.1
- cluster interconnect IPC version:
- VERITAS IPC 5.1.0.0 15:16:24 Feb 12 2009
- IPC Vendor 86 proto 76
- Version 1.0
- PMON started with pid=2, OS id=4399196
- DIAG started with pid=3, OS id=3936288
(2) 如果沒有使用第三方IPC,則優先使用數據庫初始化參數的cluster_interconnects配置,這個參數的格式為if1:if2:...:ifn,可以不同于crs的私有網絡,需要注意的是,該參數不支持多個網卡的故障切換;
(3) 沒有上面兩個配置,數據庫會使用oifcfg列出的心跳的網絡,在對應的告警日志中可以得到:
- Interface type 1 en6 192.168.61.0 configured from OCR for use as a cluster interconnect
- Interface type 1 en0 10.182.0.0 configured from OCR for use as a public interface
- . . . .
- Cluster communication is configured to use the following interface(s) for this instance
- 192.168.61.0
(4) 沒有1和2的配置,并且oifcfg也沒有配置cluster_interconnect,則數據庫會使用共有網絡進行心跳信息的傳輸,這種配置其實是配置失敗的情況,數據庫雖然能夠啟動,但急需DBA修正,在告警日志中可以看到:
- WARNING: No cluster interconnect has been specified. Depending on
- the communication driver configured Oracle cluster traffic
- may be directed to the public interface of this machine.
- Oracle recommends that RAC clustered databases be configured
- with a private interconnect for enhanced security and
- performance.
對于一個已經有的系統,可以用下面幾種方法確認數據庫實例的心跳配置,包括網卡名稱,IP地址,使用的網絡協議:
(1) 最簡單的方法:可以在數據庫的后臺報警日志中得到。具體參見上面列出的告警日志;
(2) 使用oradebug ;
- SQL> oradebug setmypid
- SQL> oradebug ipc
- SQL> oradebug tracefile_name
找到對應trace文件的這一行:socket no 10 IP 10.0.0.1 UDP 49197
(3) 從數據字典中得到(V$CLUSTER_INTERCONNECTS 和 V$CONFIGURED_INTERCONNECTS),或查詢x$ksxpia
- SQL> SELECT * FROM V$CLUSTER_INTERCONNECTS; ----Oracle 11g 開始支持此試圖
- NAME IP_ADDRESS IS_ SOURCE
- ------------------------------ ---------------- --- -------------------------------
- en3 192.168.2.31 NO Oracle Cluster Repository
- en5 192.168.3.231 NO Oracle Cluster Repository
- SQL> SELECT * FROM V$CONFIGURED_INTERCONNECTS;
- NAME IP_ADDRESS IS_ SOURCE
- ------------------------------ ---------------- --- -------------------------------
- en3 192.168.2.31 NO Oracle Cluster Repository
- en5 192.168.3.231 NO Oracle Cluster Repository
- en0 10.200.59.231 YES Oracle Cluster Repository
- SQL> select * from x$ksxpia ;
- ADDR INDX INST_ID PUB_KSXPIA PICKED_KSXPIA NAME_KSXPIA IP_KSXPIA
- ---------------- ---------- ---------- ---------- --------------- --------------- ----------------
- 00000001104AAF28 0 1 N OCR en6 192.168.61.121
- 00000001104AAF28 1 1 Y OCR en0 10.182.6.211
為了避免心跳網絡成為系統的單一故障點,簡單地我們可以使用操作系統綁定的網卡來作為Oracle的心跳網絡,以AIX為例,我們可以使用etherchannel技術,假設系統中有ent0/1/2/3四塊網卡,我們綁定2和3作為心跳:
- #mkdev -c adapter -s pseudo -t ibm_ech -a adapter_names='ent2,ent3' ## 將生成網卡設備ent4
- #/usr/lib/methods/defif
- #lsdev -Cc adapter | grep ent
- #lsattr -El ent4
- #ifconfig en4 inet 192.168.3.231 netmask 255.255.255.0 up
- 在Solaris上可以使用dladm來創建鏈路聚合:
- # dladm create-aggr -d bge2 -d bge3 1
- # ifconfig aggr1 plumb 192.168.3.231 netmask 255.255.255.0 up
- # dladm show-aggr
- # ifconfig -a
同樣在HPUX和Linux對應的技術分別叫APA和bonding。
UDP私有網絡的調優
當使用UDP作為數據庫實例間cashe fusion的通信協議時,在操作系統上需要調整相關參數,以提高UDP傳輸效率,并在較大數據時避免出現超出OS限制的錯誤:
(1) UDP數據包發送緩沖區:大小通常設置要大于(db_block_size * db_multiblock_read_count )+4k,
(2) UDP數據包接收緩沖區:大小通常設置10倍發送緩沖區;
(3) UDP緩沖區最大值:設置盡量大(通常大于2M)并一定要大于前兩個值;
各個平臺對應查看和修改命令如下:
Solaris 查看
- ndd /dev/udp udp_xmit_hiwat udp_recv_hiwat udp_max_buf ;
- 修改 ndd -set /dev/udp udp_xmit_hiwat 262144
- ndd -set /dev/udp udp_recv_hiwat 262144
- ndd -set /dev/udp udp_max_buf 2621440
AIX 查看
- no -a |egrep “udp_|tcp_|sb_max”
- 修改 no -p -o udp_sendspace=262144
- no -p -o udp_recvspace=1310720
- no -p -o tcp_sendspace=262144
- no -p -o tcp_recvspace=262144
- no -p -o sb_max=2621440
Linux 查看
- 文件/etc/sysctl.conf
- 修改 sysctl -w net.core.rmem_max=2621440
- sysctl -w net.core.wmem_max=2621440
- sysctl -w net.core.rmem_default=262144
- sysctl -w net.core.wmem_default=262144
HP-UX 不需要
HP TRU64 查看 /sbin/sysconfig -q udp
修改: 編輯文件/etc/sysconfigtab
inet: udp_recvspace = 65536
udp_sendspace = 65536
Windows 不需要
常見安裝、管理錯誤
1. 安裝CRS失敗,或執行root.sh報錯,可能原因:
(1) 節點間的時間不同步,解決方法:使用ntp服務
(2) Linux下啟用了默認的防火墻,導致執行root.sh報錯:
Failure at final check of Oracle CRS stack.
10
解決方法:禁用iptables ,注釋/etc/pam.d/other ;
- # service iptables stop; # chkconfig iptables off.
(3) 裸設備的權限問題,可能因為操作系統重新啟動后權限發生變化。(RHEL4)
解決方法: 把 chown oracle:dba /dev/raw/raw* 命令加入到/etc/rc.local中,每次開機自動執行
或者修改文件/etc/udev/permissions.d/50-udev.permissions
第113行raw/*:root:disk:0660 改成 raw/*:oracle:dba:0660
(4) Solaris使用了包括cylinder 0的磁盤分區來存儲OCR或者vote disk。
解決辦法:相關分區不應該包括cylinder 0,可以從1開始。
(5) 使用的公網IP地址不可路由,
解決方法:添加相關網關
(6) 在/etc/hosts 中沒有loopback地址,即127.0.0.1 localhost
(7) 主機名含有大些字母、減號或者下劃線等特殊字符;
(8) HPUX中oracle不要使用gnu的bash,修改使用默認shell;
(9) 檢查操作系統、第三方集群是否是oracle官方支持的,是否需要補丁,比如在AIX5.3+HACMP上安裝
Oracle 10g/11g RAC,oslevel就需要06及以上;
(10) AIX平臺,需要將共享設備的reserve_policy (reserve_lock) 屬性修改為no_reserve(no);
(11) 所有節點看到的OCR和vote設備的路徑名應該一致,如果不一致,可以用軟連接解決;
(12) 心跳設備問題或者ocr/votedisk 訪問問題,unix/linux查看有無/tmp/crsctl.*文件,得到錯誤信息;
(13) 在CRS舊的安裝的環境中重新安裝失敗
解決方法: dd清除ocr和vote disk,并使用下面語句清理舊的crs配置文件
- rm -rf /usr/tmp/.oracle /var/tmp/.oracle /tmp/.oracle /etc/oracle/* /var/opt/oracle/*
- rm -rf /etc/init.cssd /etc/init.crs* /etc/init.evmd /etc/init.d/init.cssd /etc/init.d/init.crs
- rm -rf /etc/init.d/init.crsd /etc/init.d/init.evmd /etc/rc3.d/K96init.crs /etc/rc3.d/S96init.crs
- rm -rf /etc/rc.d/rc2.d/K96init.crs /etc/rc.d/rc2.d/S96init.crs
2 客戶端有時候報錯:
ORA-12545: Connect failed because target host or object does not exist
ORA-12545: 因目標主機或對象不存在, 連接失敗
解決方法:設置local_listener初始化參數
3 如果選擇節點界面出不來。
(1)HACMP環境中需要檢查oracle 用戶必須在 hagsuser組里.
(2)如果是hacmp5.4,需要打Oracle補丁6718715;
(3)可以使用集群配置文件cluster CONFIGURATION FILE ,內容模板如下:
- MyCluster
- rac01 rac01-priv rac01-vip
- rac02 rac02-priv rac02-vip
- rac03 rac03-priv rac03-vip
- rac04 rac04-priv rac04-vip
4. AIX上數據庫啟動報錯
- ora-27504 IPC error creating OSD context
- ora-27300 OS system dependent operation:sendmsg failed with status:59
- ora-27301 OS failure message:Message too long
- ora-27302 failure occurred at:sskgxpsnd1
原因:沒有設置網絡參數udp_recvspace/udp_sendspace
5. Windows平臺,ORA-600 [kccsbck_first]
解決方法:關閉Media Sense(媒體感知)
6. 系統循環重啟:
可能是CRS導致,如果因為crs,首先設置 crsctl disable crs 來禁止oracle crs的自動啟動。
查看OS、crsd和cssd的對應日志,看/tmp/下是否有crs文件 (ls -lrt /tmp/crsctl*),確定crs失敗原因。
7. 第二個節點的數據實例無法mount,掛起或者報錯,
原因1:使用了vendor clusterware ,libskgxn2.so文件鏈接錯誤,
解決方法:比較兩個節點的ORACLE_HOME/lib/libskgxn2和CRS_HOME/lib/libskgxn2*都是否相同,
如果不同需要重新link
原因2:任何平臺Oracle 9i,沒有設置網絡參數udp參數
導致udp_sendspace或者udp_recvspace小于 db_block_size * db_file_multiblock_read_count
解決方法:設置對應參數,如AIX上設置udp_recvspace = 65536 udp_sendspace = 65536
原因3:AIX/HACMP/Oracle9i,在hacmp中定義了service IP
解決方法:在初始化參數中定義cluster_interconnects
原因4:任何平臺,設置了錯誤的cluster_interconnects
解決方法:檢查并糾正此參數,
8. 建庫時不能識別裸設備;
原因1:Oracle,10.2.0.3 ,很多平臺(比如aix和linux)有rawutl相關bug,
解決辦法:還原10.2.0.1中的rawutl工具,該程序在 $ORACLE_HOME/bin目錄中。
原因2:Oracle9i,AIX平臺,需要設置環境變量export PGSD_SUBSYS=grpsvcs
9. evm資源自動報錯oac_init:2: Could not connect to server, clsc retcode = 9
解決方法:關閉 “UDP ICMP rejections”
- /etc/rc.d/init.d/iptables stop ;chkconfig iptables off
【編輯推薦】














