詳解什么是 Oracle RAC 腦裂

什么是腦裂?
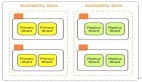
裂腦通常用于描述集群中的兩個或多個節點彼此失去連接但隨后繼續彼此獨立運行(包括獲取邏輯或物理資源)的場景,錯誤假設其他進程(es ) 不再運作或使用上述資源。簡單來說,“大腦分裂”意味著有 2 個或更多不同的節點集或“隊列”,兩個隊列之間沒有通信。
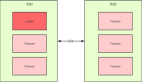
例如:假設在以下情況下有 3 個節點。1. 節點 1,2 可以相互通信。2. 但是 1 和 2 不能和 3 對話,反之亦然。然后有兩個同類群組:{1, 2} 和 {3}。

腦裂發生的原因
腦裂事件后的最大風險是破壞系統狀態的可能性。損壞的三個典型原因:1. 在發生裂腦事件之前曾經合作的進程獨立地修改相同的邏輯共享狀態,從而導致系統狀態視圖發生沖突。這通常被稱為“多主機問題”。2. 在Split-Brain 事件之后接受新請求,然后在可能損壞的系統狀態上執行(因此可能進一步損壞系統狀態)。3. 當分布式系統的進程“重新加入”在一起時,它們可能對系統狀態或資源所有權有沖突的看法。在解決沖突的過程中,信息可能會丟失或損壞。
簡單來說,在腦裂的情況下,從某種意義上說,有兩個(或更多)獨立的集群在同一個共享存儲上工作。這有可能導致數據損壞。
集群件如何解決“腦裂”的情況?
在腦裂的情況下,投票磁盤將用于確定哪些節點存活以及哪些節點將被驅逐。共同投票結果將是:
- 具有更多集群節點的組(隊列)存活
- 如果每個組中可用的節點數量相同,則具有較低節點成員的組(隊列)將存活。
- 已經進行了一些改進,以確保負載較低的節點在系統負載高引起驅逐的情況下仍然存在。
通常,當發生裂腦時,會在 ocssd.log 中看到類似以下的消息:
[ CSSD]2011-01-12 23:23:08.090 [1262557536] >TRACE: clssnmCheckDskInfo: Checking disk info
[ CSSD]2015-01-12 23:23:08.090 [1262557536] >ERROR: clssnmCheckDskInfo: Aborting local node to avoid splitbrain.
[ CSSD]2015-01-12 23:23:08.090 [1262557536] >ERROR: : my node(2), Leader(2), Size(1) VS Node(1), Leader(1), Size(2)
[ CSSD]2015-01-12 23:23:08.090 [1262557536] >ERROR:
###################################
[ CSSD]2015-01-12 23:23:08.090 [1262557536] >ERROR: clssscExit: CSSD aborting
###################################
以上消息表明從節點 2 到節點 1 的通信不工作,因此節點 2 只能看到 1 個節點,但節點 1 工作正常,它可以看到集群中的兩個節點。為避免腦裂,節點 2 自行中止。
為確保數據一致性,RAC 數據庫的每個實例都需要與其他實例保持心跳。心跳由 LMON、LMD、LMS 和 LCK 等后臺進程維護。這些進程中的任何一個遇到 IPC 發送超時都會導致通信重新配置和實例驅逐以避免腦裂。控制文件與集群件層中的投票磁盤類似,用于確定哪些實例存活以及哪些實例驅逐。投票結果類似于集群件投票結果。結果,將驅逐 1 個或多個實例。
實例警報日志中的常見消息類似于:
alert log of instance 1:
---------
Mon Dec 07 19:43:05 2011
IPC Send timeout detected.Sender: ospid 26318
Receiver: inst 2 binc 554466600 ospid 29940
IPC Send timeout to 2.0 inc 8 for msg type 65521 from opid 20
Mon Dec 07 19:43:07 2011
Communications reconfiguration: instance_number 2
Mon Dec 07 19:43:07 2011
Trace dumping is performing id=[cdmp_20091207194307]
Waiting for clusterware split-brain resolution
Mon Dec 07 19:53:07 2011
Evicting instance 2 from cluster
Waiting for instances to leave:
2
alert log of instance 2:
---------
Mon Dec 07 19:42:18 2011
IPC Send timeout detected. Receiver ospid 29940
Mon Dec 07 19:42:18 2011
Errors in file
/u01/app/oracle/diag/rdbms/bd/BD2/trace/BD2_lmd0_29940.trc:
Trace dumping is performing id=[cdmp_20091207194307]
Mon Dec 07 19:42:20 2011
Waiting for clusterware split-brain resolution
Mon Dec 07 19:44:45 2011
ERROR: LMS0 (ospid: 29942) detects an idle connection to instance 1
Mon Dec 07 19:44:51 2011
ERROR: LMD0 (ospid: 29940) detects an idle connection to instance 1
Mon Dec 07 19:45:38 2011
ERROR: LMS1 (ospid: 29954) detects an idle connection to instance 1
Mon Dec 07 19:52:27 2011
Errors in file
/u01/app/oracle/diag/rdbms/bd/BD2/trace/PVBD2_lmon_29938.trc
(incident=90153):
ORA-29740: evicted by member 0, group incarnation 10
Incident details in:
/u01/app/oracle/diag/rdbms/bd/BD2/incident/incdir_90153/BD2_lmon_29938_i90153.trc
在上面的示例中,實例 2 LMD0 (pid 29940) 是 IPC 發送超時的接收方。?