













Linux流量控制的基本實現和具體使用
作者:佚名
本篇文章針對Linux流量控制從兩方面進行的介紹,一是Linux流量控制的基本實現,二是Linux流量控制的具體使用,讓我們一起來看看詳細的內容
一般企業內部網絡有足夠的帶寬可以使用。但是,在企業接入Internet的部分都是一個有限的流量。為了提高網絡的使用質量,保證用戶按照網絡中業務設計的要求來使用整個網絡的帶寬,可以從流量控制服務器的角度分析、優化Linux系統,給企業服務帶來便利和高效。下面一起來看看Linux 流量控制的實現和具體使用情況。
Linux流量控制的基本實現
Linux操作系統中的流量控制器(TC)主要是通過在輸出端口處建立一個隊列來實現流量控制。Linux從2.1.105版內核開始支持流量控制,使用時需要重新編譯內核。Linux流量控制的基本實現可簡單地由圖1來描述。從圖1可以看出,內核是如何處理接收包、如何產生發送包,并送往網絡的。
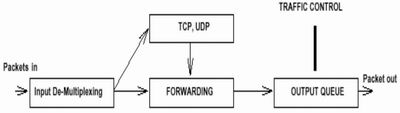
圖1 Linux流量控制的基本實現
接收包進來后,由輸入多路分配器(Input De-Multiplexing)進行判斷選擇:如果接收包的目的是本主機,那么將該包送給上層處理;否則需要進行轉發,將接收包交到轉發塊(Forwarding Block)處理。轉發塊同時也接收本主機上層(TCP、UDP等)產生的包。轉發塊通過查看路由表,決定所處理包的下一跳。然后,對包進行排列以便將它們傳送到輸出接口(Output Interface)。Linux流量控制正是在排列時進行處理和實現的。
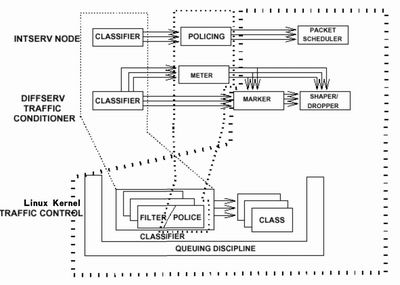
圖2 流量控制基本框架
如圖2所示,Linux流量控制主要由三大部分來實現:
◆ 隊列規則(Queue Discipline)
◆ 分類(Classes)
◆ 過濾器(Filters)
因此,Linux流量控制主要分為建立隊列、建立分類和建立過濾器三個方面。其基本實現步驟為:
(1)針對網絡物理設備(如以太網卡eth0)綁定一個隊列;
(2)在該隊列上建立分類;
(3)為每一分類建立一個基于路由的過濾器。
【編輯推薦】
責任編輯:chenqingxiang















