構(gòu)建輕量級XML DOM分析程序
XML正迅快速的成為數(shù)據(jù)存儲和交換的標(biāo)準(zhǔn)格式流行開來了。現(xiàn)在可用的完整的Java XML分析器非常龐大而且功能強大--但是實現(xiàn)這些強大的功能的同時也要消耗等量的資源。
因此使用一個功能強大的XML分析器可能過于浪費。如果配置環(huán)境是一個Java小程序或者是一個J2ME應(yīng)用程序,網(wǎng)絡(luò)帶寬或者系統(tǒng)存儲器的制約可能根本不能夠使用完整的XML分析器。本文將告訴你如何構(gòu)建一個輕量級的XML DOM分析程序。
開始編寫SimpleDOMParser
SimpleDOMParser是一個使用Java寫的高度簡化和超輕量級的XML DOM分析器。 你可以將配置整個分析器配置為一個小于4KB的.jar文件。源程序還不到400行呢。
顯然,使用這么小的代碼,SimpleDOMParser將不支持XML域名空間,不能夠理解多字符集編碼或者以DTD文件或者schema驗證文件;但是SimpleDOMParser能做的就是把符合語法規(guī)則的XML標(biāo)記解析為一個類似于DOM的元素樹,讓你執(zhí)行從XML格式化文本提取的數(shù)據(jù)的公共任務(wù)。
為什么使用DOM作為模型而不是SAX呢?這是因為DOM提供一個比SAX更加易用的程序接口。與SAX不同的是,當(dāng)你把一個XML文件作為一個DOM樹來處理的時候,這個文件內(nèi)的所有的信息都是可以利用的。雖然SAX分析模型能夠提供比DOM模型更加優(yōu)異的性能和利用更少的存儲空間,但是大部分開發(fā)者在使用SAX的時候都會發(fā)現(xiàn)他們自己正在創(chuàng)建一個完整的或者部分的DOM樹。
使用SAX,一個應(yīng)用程序每次只能處理一條標(biāo)記。如果其它的標(biāo)記內(nèi)容在處理的過程中必須被用到,那你就必須在處理的整個過程保持一種全局狀態(tài)。而保持全局狀態(tài)正是DOM模型目的的精髓。但是許多小型的XML應(yīng)用程序不需要完整的DOM模型。因此,SimpleDOMParser提供到標(biāo)記名、層次和內(nèi)容的訪問,但是不涉及完整的W3C DOM的許多用不上的功能。
簡化DOM模型
一個DOM樹是由分析XML文件產(chǎn)生的結(jié)點組成。結(jié)點是一個XML實體的非存儲表現(xiàn)。標(biāo)準(zhǔn)W3C DOM模型有幾種類型的結(jié)點。 舉例來說,一個文本結(jié)點表示在XML文件中的一段文本,一個元素結(jié)點表示XML文件而一個屬性結(jié)點表示一個元素內(nèi)部的屬性名和值。
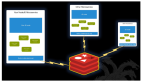
DOM是一個樹,因為除了根或文件結(jié)點以外的每個結(jié)點都有一個父結(jié)點。舉例來說,屬性結(jié)點總是和一個元素結(jié)點相關(guān)聯(lián),而用來封裝元素的起始標(biāo)記和結(jié)束標(biāo)記中的文本是映射到一個文本結(jié)點的。文本結(jié)點是元素結(jié)點的一個子節(jié)點。所以,即使很簡單的XML文件的表現(xiàn)也可能會需要很多種節(jié)點類型。舉例來說,圖1表示下面XML文件的一個W3C DOM樹形表示。
- <parser>SimpleDOMParser</parser>
正如你在圖1中所看見的,DOM模型使用一個document類型節(jié)點來封裝整個XML文件,所以DOM使用三種不同的節(jié)點。通過把所有的DOM節(jié)點類型抽象成為一個單獨的類型SimpleElement來盡可能的簡化DOM模型。一個SimpleElement獲得一個XML元素的關(guān)鍵的信息,比如標(biāo)識名、元素屬性和任何封裝的文本或者XML。此外,SimpleDOMParser不使用任何特殊的節(jié)點類型表示***等級的文檔。結(jié)果是大大地簡化了DOM樹,使之只包含SimpleElement節(jié)點。圖2表示了簡化的DOM樹。
代碼段1給出了SimpleElement類的完整的源程序。
- public class SimpleElement {
- private String tagName;
- private String text;
- private HashMap attributes;
- private LinkedList childElements;
- public SimpleElement(String tagName) {
- this.tagName = tagName;
- attributes = new HashMap();
- childElements = new LinkedList();
- }
- public String getTagName() {
- return tagName;
- }
- public void setTagName(String tagName) {
- this.tagName = tagName;
- }
- public String getText() {
- return text;
- }
- public void setText(String text) {
- this.text = text;
- }
- public String getAttribute(String name) {
- return (String)attributes.get(name);
- }
- public void setAttribute(String name, String value) {
- attributes.put(name, value);
- }
- public void addChildElement(SimpleElement element) {
- childElements.add(element);
- }
- public Object[] getChildElements() {
- return childElements.toArray();
- }
- }
#p#
定義XML語法分析基本元素
為了把一個XML文件處理成為上面提到的簡化的DOM樹模型,我們必須定義一些基本的語法分析規(guī)則。使用這些規(guī)則,語法分析程序就能容易地從輸入的XML文件中提取標(biāo)記或者文本塊。
***個是peek,從輸入的XML文件中返回下一個字符,而實際上則不必從下層流中獲得這個字符。通過保持輸入流的完整性,高級函數(shù)比如readTag和readText(后面將介紹)可以更加容易地根據(jù)它們接下來期待的字符獲取需要的內(nèi)容。
- private int peek() throws IOException {
- reader.mark(1);
- int result = reader.read();
- reader.reset();
- return result;
- }
下一個方法是skipWhitespce,作用是跳過輸入的XML流中的空格、制表符或者回車符。
- private void skipWhitespace() throws IOException {
- while (Character.isWhitespace((char) peek())) {
- reader.read();
- }
- }
在創(chuàng)建了如上所述的這兩個方法后,我們就可以寫一個函數(shù)從輸入文件中檢索XML標(biāo)記。
- private String readTag() throws IOException {
- skipWhitespace();
- StringBuffer sb = new StringBuffer();
- int next = peek();
- if (next != '<') {
- throw new IOException
- ("Expected > but got " + (char) next);
- }
- sb.append((char)reader.read());
- while (peek() != '>') {
- sb.append((char)reader.read());
- }
- sb.append((char)reader.read());
- return sb.toString();
- }
和peek方法聯(lián)合使用,readTag函數(shù)只獲得一個標(biāo)記的內(nèi)容,而讓別的函數(shù)去處理其他的內(nèi)容。 ***的一個方法是readText函數(shù),用來讀取XML標(biāo)記之間的文本。
- private String readText() throws IOException {
- int[] cdata_start = {'<', '!',
- '[', 'C', 'D', 'A', 'T', 'A', '['};
- int[] cdata_end = {']', ']', '>'};
- StringBuffer sb = new StringBuffer();
- int[] next = new int[cdata_start.length];
- peek(next);
- if (compareIntArrays(next, cdata_start) == true) {
- // CDATA
- reader.skip(next.length);
- int[] buffer = new int[cdata_end.length];
- while (true) {
- peek(buffer);
- if (compareIntArrays
- (buffer, cdata_end) == true) {
- reader.skip(buffer.length);
- break;
- } else {
- sb.append((char)reader.read());
- }
- }
- } else {
- while (peek() != '<') {
- sb.append((char)reader.read());
- }
- }
- return sb.toString();
- }
這次使用的peek方法是前面那個從基本的XML文檔返回一個字符串序列的peek方法的變體。這個peek變體讓語法分析程序判斷它將分析的文本是否被裝入一個CDATA塊。compareIntArrays函數(shù)是一個執(zhí)行兩個整數(shù)數(shù)組的深度比較的簡單程序。
#p#
定義XML語法分析基本元素
為了把一個XML文件處理成為上面提到的簡化的DOM樹模型,我們必須定義一些基本的語法分析規(guī)則。使用這些規(guī)則,語法分析程序就能容易地從輸入的XML文件中提取標(biāo)記或者文本塊。
***個是peek,從輸入的XML文件中返回下一個字符,而實際上則不必從下層流中獲得這個字符。通過保持輸入流的完整性,高級函數(shù)比如readTag和readText(后面將介紹)可以更加容易地根據(jù)它們接下來期待的字符獲取需要的內(nèi)容。
- private int peek() throws IOException {
- reader.mark(1);
- int result = reader.read();
- reader.reset();
- return result;
- }
下一個方法是skipWhitespce,作用是跳過輸入的XML流中的空格、制表符或者回車符。
- private void skipWhitespace() throws IOException {
- while (Character.isWhitespace((char) peek())) {
- reader.read();
- }
- }
在創(chuàng)建了如上所述的這兩個方法后,我們就可以寫一個函數(shù)從輸入文件中檢索XML標(biāo)記。
- private String readTag() throws IOException {
- skipWhitespace();
- StringBuffer sb = new StringBuffer();
- int next = peek();
- if (next != '<') {
- throw new IOException
- ("Expected > but got " + (char) next);
- }
- sb.append((char)reader.read());
- while (peek() != '>') {
- sb.append((char)reader.read());
- }
- sb.append((char)reader.read());
- return sb.toString();
- }
和peek方法聯(lián)合使用,readTag函數(shù)只獲得一個標(biāo)記的內(nèi)容,而讓別的函數(shù)去處理其他的內(nèi)容。 ***的一個方法是readText函數(shù),用來讀取XML標(biāo)記之間的文本。
- private String readText() throws IOException {
- int[] cdata_start = {'<', '!',
- '[', 'C', 'D', 'A', 'T', 'A', '['};
- int[] cdata_end = {']', ']', '>'};
- StringBuffer sb = new StringBuffer();
- int[] next = new int[cdata_start.length];
- peek(next);
- if (compareIntArrays(next, cdata_start) == true) {
- // CDATA
- reader.skip(next.length);
- int[] buffer = new int[cdata_end.length];
- while (true) {
- peek(buffer);
- if (compareIntArrays
- (buffer, cdata_end) == true) {
- reader.skip(buffer.length);
- break;
- } else {
- sb.append((char)reader.read());
- }
- }
- } else {
- while (peek() != '<') {
- sb.append((char)reader.read());
- }
- }
- return sb.toString();
- }
這次使用的peek方法是前面那個從基本的XML文檔返回一個字符串序列的peek方法的變體。這個peek變體讓語法分析程序判斷它將分析的文本是否被裝入一個CDATA塊。 compareIntArrays函數(shù)是一個執(zhí)行兩個整數(shù)數(shù)組的深度比較的簡單程序。
【編輯推薦】