海量小文件導(dǎo)致高并發(fā)、大流量問題的探討
在互聯(lián)網(wǎng)快速發(fā)展的背景下,特別是Web 2.0,網(wǎng)絡(luò)上的數(shù)據(jù)內(nèi)容呈幾何級的增長,而其中增長最快并且最容易給技術(shù)架構(gòu)帶來挑戰(zhàn)的就是數(shù)目龐大的小文件,如何來解決這種高并發(fā),大流量,小文件,熱點不集中的問題,經(jīng)過我們大量研究,實踐之后,總結(jié)出這種海量小文件,高并發(fā)所存在的關(guān)鍵問題和解決方案。
我們先對比一下在Web 1.0的解決方案和Web 2.0的我們碰到的困難。
Web 1.0解決方案:
1、源數(shù)據(jù)量小,單臺squid即可達到很高的命中率。
2、請求量大,用lvs+squid或者dns輪詢即可解決問題。
3、squid服務(wù)器磁盤IO壓力大,用超大內(nèi)存做Cache。
Web 2.0目前的瓶頸:
1、源數(shù)據(jù)數(shù)量很大,導(dǎo)致squid hash table索引效率不高,Cache命中率低。
為了提高對文件的訪問效率,往往會在前端配置一個稍大容量的緩存。但由于小文件的數(shù)量極其龐大,應(yīng)用對這些文件訪問的隨機性非常高,使得Cache命中率極低,緩存失去了應(yīng)有的作用,導(dǎo)致應(yīng)用需要直接到后端存儲系統(tǒng)上讀取數(shù)據(jù),給存儲系統(tǒng)帶來了極大的壓力。剛開始就是我們也采用了昂貴的高端存儲系統(tǒng)NetApp,但是在用戶高并發(fā)訪問的情況下,存儲系統(tǒng)經(jīng)常出現(xiàn)長時間無響應(yīng)的嚴(yán)重故障。
2、源數(shù)據(jù)容量巨大,海量文件檢索效率低,從而也導(dǎo)致單臺squid命中率很低。
有些頻道數(shù)據(jù)容量會超過200T,單臺squid只是杯水車薪,頻繁的Cache置換更是加劇了Cache效率低下,再加上現(xiàn)有的存儲系統(tǒng)無法有效管理海量小文件,并且在單個目錄下存放文件的數(shù)量有一定的限制,一旦文件數(shù)到達了一定規(guī)模之后,文件的檢索速度就急劇下降。我們只能通過多級目錄來組織存放大量的小文件,隨著目錄深度的增加,文件的檢索開銷進一步增大,檢索效率隨之下降。
3、大量的cache導(dǎo)致的磁盤IO問題。
由于目前單臺Cache容量已經(jīng)達到上百G,文件系統(tǒng)瓶頸、磁盤IO問題也很快凸顯。
4、壓力過大導(dǎo)致的hit ratio抖動。
Cache刪除,寫操作達到一定的比例,同時如果壓力較高,會導(dǎo)致hit ratio呈線性下降。即使Cache沒down,但也因為命中率的下降而失去應(yīng)有的作用。
5、特殊集群下的單臺失效問題。
在類url hash的集群下,單臺cache失效會導(dǎo)致hash rehash,那么整個集群的squid命中率都會被沖擊。
如何來解決這些問題,思路如下:
1、優(yōu)化squid hash table索引算法,需要修改源squid代碼。
2、Cache集群,用類url hash的方法,以增加Cache容量。
◆wccp: cisco的路由器均有此功能
◆carp: ISA,squid自身的7層調(diào)度協(xié)議
◆url hash: nginx haproxy等7層代理
3、選擇合適的文件系統(tǒng)
XFS使用更多的內(nèi)存來作為自己的高速緩存,以盡可能的延遲零散的寫操作,盡可能的執(zhí)行批量寫操作。
4、選擇更合理的磁盤搭配策略,比如Raid策略或者單盤策略等
Raid 5,10帶來了不錯的安全性,但是會導(dǎo)致磁盤IO效率低下,不做Raid的單盤性能最高,更適合單臺服務(wù)器多squid進程模式。
5、集群下的單臺Cache失效的接管,以免單點故障,提高可用性。
針對以上分析,我們大量嘗試了開源的一些產(chǎn)品,像LVS,Nginx,Squid,XFS等。具體的軟件組合和架構(gòu)如下:
(1)Web服務(wù)器的選擇,目前,大多數(shù)Web服務(wù)器的處理能力有限,互聯(lián)網(wǎng)廣泛上使用的Web服務(wù)器如Apache,其并發(fā)能力往往在2000以下,這是由Web服務(wù)器自身的設(shè)計模式(如多進程,無IO緩存等)決定的。因此,在較大規(guī)模的訪問情況下,通常會表現(xiàn)出用戶訪問網(wǎng)站慢,Web服務(wù)器負(fù)載高。為什么選擇Nginx?use linux epoll, sendfile and aio to improve the performanc,我們主要利用的是Nginx的第三方模塊ngx_http_upstream_hash_module做反向代理。部分代碼如下:
- upstream img{
- server squid1:81;
- server squid2:81;
- hash $request_uri;
- hash_again 0; # default 0
- hash_method crc32; # default “simple”
- }
- server {
- listen 80;
- server_name images.gx.com;
- location / {
- proxy_pass http://img;
(3)負(fù)載均衡軟件,我們選擇了LVS+HA,用DR模式。目前我們運行環(huán)境中的LVS(2.6的內(nèi)核),普通很穩(wěn)定。我們主要用Heartbeat+ldirectord。
(4) 適合處理小文件的文件系統(tǒng)XFS。XFS最佳表現(xiàn)之一在于:象ReiserFS一樣,它不產(chǎn)生不必要的磁盤活動。XFS設(shè)法在內(nèi)存中緩存盡可能多的數(shù)據(jù),并且,通常僅當(dāng)內(nèi)存不足時,才會命令將數(shù)據(jù)寫到磁盤時。當(dāng)它將數(shù)據(jù)清倉(flushing)到磁盤時,其它IO操作在很大程度上似乎不受影響。
(5)其它優(yōu)化
在客戶端和服務(wù)器做大量有效的緩存策略;用更小的并且可緩存的圖片(單張圖片盡量不要超過200K);盡量減少http請求;開起 keepalive減少tcp連接開銷;優(yōu)化tcp參數(shù);起用多域名分域名策略;減少cookie影響等。
(6)關(guān)于優(yōu)化題外:大配置和架構(gòu)沒有問題的前提下,有money的話應(yīng)該首選硬件優(yōu)化方案而不是軟件細(xì)節(jié)優(yōu)化。

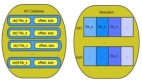
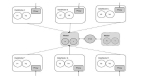
整個架構(gòu)如圖
后端存儲垂直分割的規(guī)則如下(按00-ff散列):
- location ~ ^/[0-1][0-f]/ {
- proxy_pass http://192.168.3.12;
- }
- location ~ ^/[2-3][0-f]/ {
- proxy_pass http://192.168.3.11;
- }
- ……..
以上這個架構(gòu)的優(yōu)化在于:
◆實現(xiàn)了高可用性,最大程度上防止單點,又保證架構(gòu)的伸縮性。
◆在后端服務(wù)器中模擬url hash的算法來找到內(nèi)容所在的squid,提高了命中率。
◆充分發(fā)揮機器的性能,架構(gòu)可擴展性,層次分明。
最后,很重要的二點:
1)要通過性能分析和監(jiān)控,來找到系統(tǒng)瓶頸的臨界點和薄弱點。監(jiān)控分析是一切優(yōu)化的重點,要以數(shù)據(jù)事實來調(diào)整策略。
2)架構(gòu)的負(fù)荷如果已經(jīng)超過設(shè)計負(fù)荷的5~10倍,就要考慮重新設(shè)計系統(tǒng)的架構(gòu),我們這里僅僅討論某一階段的架構(gòu)設(shè)計。
【編輯推薦】