教你識透Facebook的網站框架LAMP
了解facebook網站框架技術-LAMP:
一、設計原則:
盡可能的使用開源軟件,并且在需要優化的時候進行優化
Unix 哲學。包括,模塊化原則;整合化原則;清晰化原則等
任何組件具備擴展性
最小化故障影響
簡化,簡化,簡化!
二、架構概覽
Facebook 是 LAMP 的堅定支持者,也差不多是用 LAMP (或許用 LAM2P 更適合) 實現的最大的動態站點。
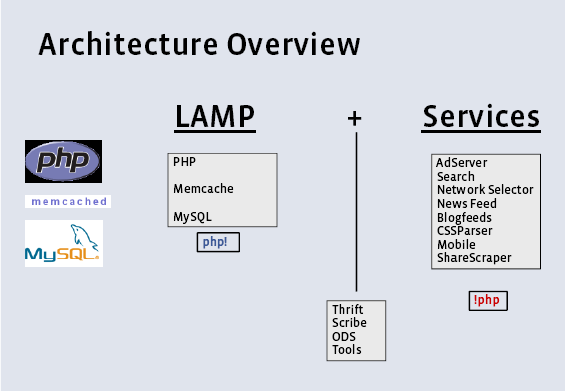
基礎組件加上服務,中間用自己實現的一些工具進行粘合。其中關于運維細節的事情基本不會說出來的,這是很多公司的軟實力所在。
三、MySQL 經驗
主要用于做 Key-Value 類型的存儲操作,數據隨機分布在多臺邏輯實例上,訪問多數基于全局 ID 。
邏輯實例分散在多臺物理主機上(超過1800臺),負載均衡在物理層進行。
不做讀復制。
盡量不做邏輯數據遷移(成本太高)。
不做 JOIN 操作 (豆瓣在 QCon 上也闡述了這一點)。數據是隨機分布的,關聯操作反而帶來了極大的復雜度。
對于數據訪問,主要的操作集中在最新的數據上,針對這部分做優化,舊的數據進行歸檔。
在中心 DB 絕不存儲非靜態數據。
使用服務或者 Memcached 進行全局查詢。
四、Memcached 經驗
一個比較有價值的是關于個人頁面數據的獲取的描述。這個就完全是需要做單頁面 Benchmark 的細致活兒了,可能還需要產品經理能夠理解工程師的"抵抗"。
獲取個人信息數據:通過Cache,隱性通過用戶所在的 DB 獲取(基于 User-ID 獲知 DB)
獲取朋友連接信息:通過Cache,否則的話通過DB(基于 User-ID 獲知 DB)
并行抓取每個朋友的 10個照片相冊 ID ,從Cache抓取,如果失效,再從 DB 抓取(基于相冊 ID)
并行抓取最近相冊中的照片數據
運行PHP 把整個業務邏輯跑出來
返回數據給用戶
然后是對 Facebook 非 LAMP 體系的東西做了一番介紹,基本上也開源了。最后參考兩個架構圖。
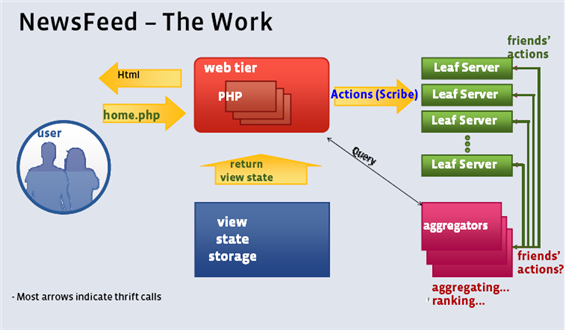
Facebook NewsFeed 的架構示意圖
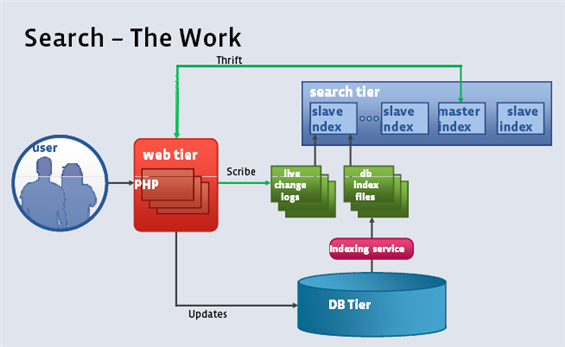
Facebook 搜索功能的架構示意圖
【編輯推薦】