介紹索引訪問方法及索引優化
索引是一個單獨的、物理的數據庫結構,它是某個表中一列或若干列值的集合和相應的指向表中物理標識這些值的數據頁的邏輯指針清單。索引提供指向存儲在表的指定列中的數據值的指針,然后根據您指定的排序順序對這些指針排序。數據庫使用索引的方式與您使用書籍中的索引的方式很相似:它搜索索引以找到特定值,然后順指針找到包含該值的行。
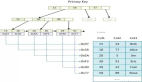
要了解索引訪問方法,首先要知道索引的結構。
1.表和索引的結構
頁
頁是sql server存儲數據的基本單位,大小為8kb,可以存儲表數據、索引數據、執行計劃數據、分配位圖、可用空間信息。頁是sql server可以讀寫的最小I/O單位。即便是讀取一行數據,它也要把整個頁加載到緩存并從緩存中讀取數據。
區
區是由8個連續頁組成的分配單元。
堆
堆是指不含聚集索引的表,它的數據不按任何順序進行存儲。
聯系一個堆中的數據的唯一結構是被稱為索引分配映射(IAM)的一個位圖頁,當掃描對象時,SQl server使用IAM頁來遍歷該對象的數據。
聚集索引:
它的葉級表中維護所有數據,按照索引鍵列的順序存儲在索引的葉級。在索引頁級別的上層,索引還維護著其他級別,每個級別都概況了它下面的級別,非葉級索引上的每一行指向它下一級別的整個頁。
堆上的非聚集索引:
與聚集索引的唯一區別是非聚集索引的葉級頁只包含索引鍵列和指向特定數據行的行定位符,稱為RID。當通過索引查找到特定的數據行后,Sqlserver必須在seek操作之后執行RID lookup操作,該操作用于讀取包含數據行的頁。
聚集表上的非聚集索引:
指向特定數據行的行定位符是聚集鍵的值,不是RID。
2.索引訪問方法
表掃描/無序聚集索引掃描
當表中沒有索引時,連續的掃描表中的所有數據頁。SQl server將根據該表的IAM頁指示磁盤取數臂按物理順序掃描屬于該表的區。
當表包含聚集索引時,所采取的方法將是無序聚集索引掃描。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders
索引:
- CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
表Orders結構:
- orderid,custid,empid,shipperid,orderdate,filler
覆蓋非聚集索引掃描
Sql server 只訪問索引數據就可以找到滿足查詢所需的全部數據,不需要訪問完整的數據行。
示例sql:
- select orderid from dbo.Orders
索引:
- ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [PK_Orders] PRIMARY KEY NONCLUSTERED
- (
- [orderid] ASC
- )
有序聚集索引掃描
按照鏈接列表對聚集索引葉級執行的完整掃描 操作。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders order by orderdate
索引:
- CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
不同于無序索引掃描,有序掃描的性能取決于索引的碎片級別。
有序覆蓋非聚集索引掃描
與有序聚集索引掃描類似,但是覆蓋非聚集索引掃描時,因為它涉及更少的頁,它的成本肯定比聚集索引索引掃描要低。
示例sql:
- select orderid, orderdate from dbo.Orders order by orderid
非聚集索引索引查找+有序局部掃描+lookups
通常用于小范圍查詢,且用到的非聚集索引沒有覆蓋該查詢。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where orderid between 101 and 200
無序非聚集索引掃描 + lookups
通常符合以下情況時,優化器會選擇此種訪問方法:
- 該查詢的選擇性足夠高
- 最適合某查詢的索引并不覆蓋該查詢
- 索引沒有按順序維護被查找鍵
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where custid = ‘’
聚集索引查找+有序局部掃描
對于按聚集索引的***個鍵列進行篩選的范圍查詢,優化器通常使用這種方法。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where orderdate = ‘20060212’
這種方法的好處是不涉及lookups.
覆蓋非聚集索引查找+有序局部掃描
訪問方法與上一個類似,唯一的區別是非聚集索引。相對于上一個訪問方法,這個方法的好處在于非聚集索引的的葉級頁比聚集索引的葉級頁能夠容納更多的行。
示例sql:
- select shipperid,orderdate, custid from dbo.Orders
- Where shipperid='C' and orderdate >='20060101' and orderdate <'20070101'
- CREATE NONCLUSTERED INDEX idx_nc_sid_od_cid
- ON dbo.Orders(shipperid, orderdate, custid);
3.索引優化等級
需要優化的sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where orderid > 999001
1.這個表沒有任何索引:該計劃將使用表掃描
2.接下來優化,創建一個非聚集覆蓋索引,且不把篩選列(orderid)作為***個篩選列:
- CREATE INDEX idx_nc_od_i_oid_cid_eid_sid
- ON performance.dbo.Orders(orderdate)
- include(orderid,custid,empid,shipperid);
優化器將采用覆蓋非聚集索引掃描
3.下一步優化:創建一個不覆蓋該查詢的非聚集索引
- CREATE NONCLUSTERED INDEX idx_nc_od_i_oid
- ON dbo.Orders(orderdate)
- INCLUDE(orderid);
優化器將采用非聚集索引掃描+lookup,這個查詢依賴于選擇性。選擇性越高,性能越高。
4.繼續優化:在orderid上創建非聚集非覆蓋索引,
- CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid
- ON dbo.Orders(orderid);
優化器將采用非聚集索引查找+lookup
5.繼續優化:在orderid上創建聚集索引
- CREATE UNIQUE CLUSTERED INDEX idx_cl_oid ON dbo.Orders(orderid);
這個計劃主要不涉及lookup,
6.繼續優化:
***優化應該是把orderid作為鍵列,并把其他列定義為包含性非鍵列的非聚集覆蓋索引。
- CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid_i_od_cid_eid_sid
- ON dbo.Orders(orderid)
- INCLUDE(orderdate, custid, empid, shipperid);
這個計劃的邏輯與上一個類似,只是非聚集覆蓋索引有序局部掃描讀取的頁更少。
【編輯推薦】