













SQL SERVER數據挖掘之理解列的用法
作者:陳希章
本文我們接著上次介紹SQL SERVER數據挖掘,本次介紹數據挖掘之理解列的用法,希望能對您有所幫助。
繼上次我們介紹了:SQL SERVER 數據挖掘之理解內容類型,這次我們介紹SQL SERVER數據挖掘之理解列的用法。
這是一個小的細節問題,我們在定義挖掘模型的時候,會指定不同的列的用法,基本上有如下幾種:
- Ignore(忽略)
- Input(輸入)
- Predict(預測)
- PredictOnly(僅預測)
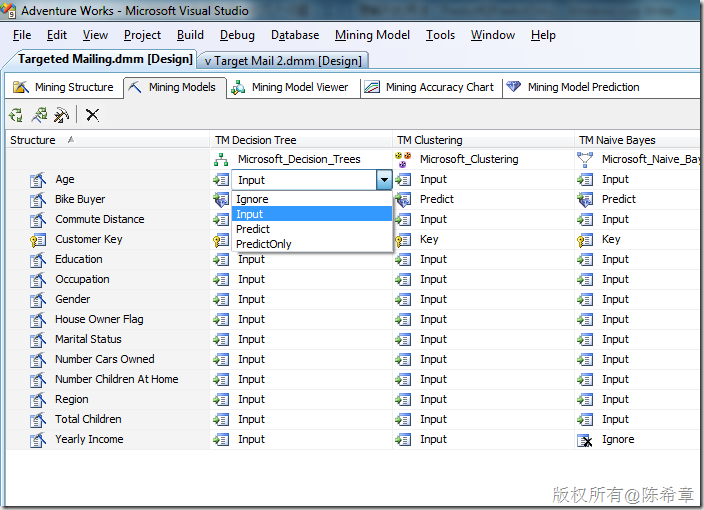
前面兩個很容易理解,“忽略”就是說這個列不在當前算法中使用,例如某些列在某些算法里面不受支持。而“輸入”則是最常見的一種用法,就是說這個列作為算法作為預測分析的輸入數據。
關鍵在于如何理解“預測”與“僅預測”。
預測:這種列的意思是,該列既作為輸入列(輸入的數據),也作為輸出列(預測的結果)。
僅預測:該列只作為輸出列,不能作為輸入列。也就是說它不會作為對其他因素做分析或者預測的因素。
這里面有兩個主要層面的意思:
如果是選擇“預測”這種用法,那么這種列可以作為“輸入”的性質,對其他列(尤其是其他預測列)產生影響。而“僅預測”這種則是說自己只是僅僅作為預測的目的存在,它本身不能作為預測其他列的前提。
所以,如果有多個預測列(這在有的時候也是可能的),那么對于某些列,設置為“預測”而不是“僅預測”應該是很有必要的;而對于在模型中只有***的預測目標列時,可以設置為“僅預測”來提高模型的準確性和效率。
在對新數據做預測的時候,我們也可以看到這樣的意思:
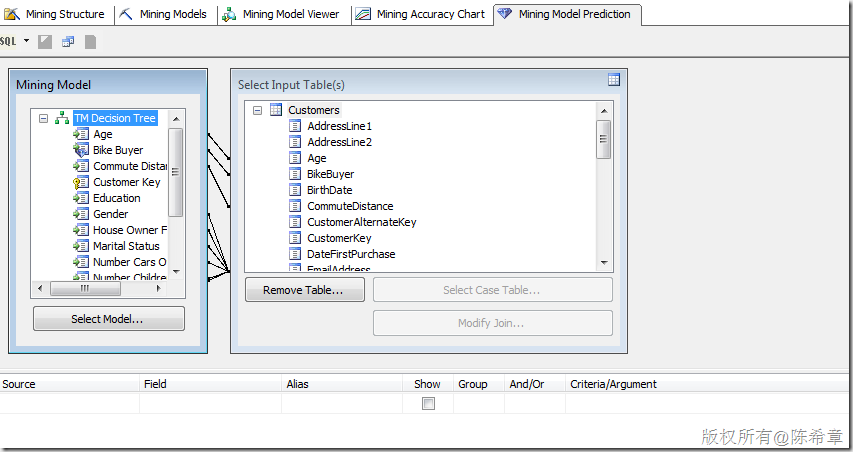
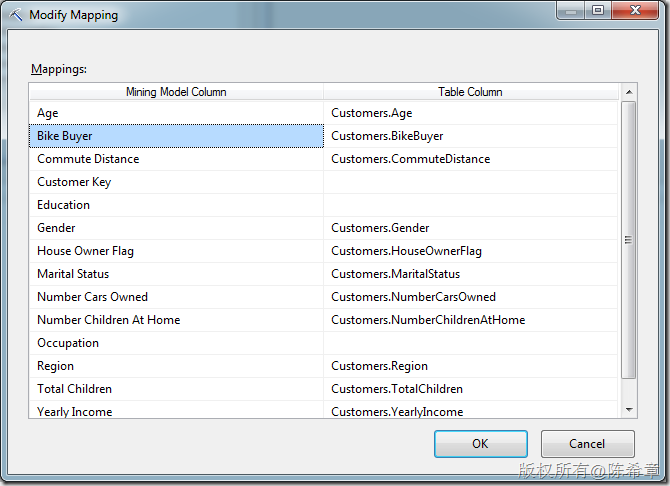
在這種情況下,Bike Buyer這個列,也可以作為輸入進行映射。
關于SQL SERVER數據挖掘之列的用法就介紹到這里,下一篇我們介紹:SQL SERVER數據挖掘之理解聚類算法和順序聚類算法。
【編輯推薦】
責任編輯:趙鵬
來源:
博客園











