百度Hadoop分布式系統揭秘:4000節點集群
作者:chinacloud
在 NoSQL 方面,之前了解到百度對 Hadoop 和 hypertable 都有研究,而且 hypertable 方面更是作為其主要贊助商之一,但之前和百度的一些朋友了解到百度內部對 hypertable 倒是使用不多,相反在 Hadoop 方面倒是有比較大的應用實例。下面一篇文章描述了百度內部4000個結點的 Hadoop 集群的一些技術細節。
在 NoSQL 方面,之前了解到百度對 Hadoop 和 hypertable 都有研究,而且 hypertable 方面更是作為其主要贊助商之一,但之前和百度的一些朋友了解到百度內部對 hypertable 倒是使用不多,相反在 Hadoop 方面倒是有比較大的應用實例。下面一篇文章描述了百度內部4000個結點的 Hadoop 集群的一些技術細節。
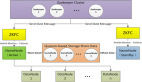
百度的高性能計算系統(主要是后端數據訓練和計算)目前有4000節點,超過10個的集群,最大的集群規模在1000個節點以上。每個節點由8核 CPU以及16G內存以及12TB硬盤組成,每天的數據生成量在3PB以上。規劃當中的架構將有超過1萬個節點,每天的數據生成量在10PB以上。

底層的計算資源管理層采用了Agent調度不同類型的計算分別給MPI結構的算法和Map-Reduce和DAG算法應用等。而通過調度的分配,可以讓HPC高性能計算集群和大規模分布式集群各得其所的計算相應數據。

百度通過HCE對streaming作業的排序,壓縮,解壓縮,內存控制進行了優化并提供了C++版的MapReduce接口。




百度HCE語言的有關內容,HCE是基于C++的Hadoop環境,是一個全功能C++環境,可以避開Java語言對于釋放內存和資源申請的弊端,并在調用數據時繞開Java語言的所有關節,極大的提升算法效率。

百度的調度器是在capacity-scheduler的基礎上根據自身業務改進的。

百度計劃對shuffle流程進行大幅改造
原文鏈接:http://www.cnblogs.com/chinacloud/archive/2010/11/08/1871592.html
【編輯推薦】
責任編輯:艾婧
來源:
chinacloud