Hadoop之完全分布式集群
作者:kocdaniel
首先準備三臺客戶機(hadoop102,hadoop103,hadoop104),關閉防火墻,修改為靜態ip和ip地址映射
首先準備三臺客戶機(hadoop102,hadoop103,hadoop104),關閉防火墻,修改為靜態ip和ip地址映射
配置集群
編寫集群分發腳本
- 創建一個遠程同步的腳本xsync,并放到當前用戶下新建的bin目錄下,配置到PATH中,使得此腳本在任何目錄下都可以執行
- 腳本實現
- [kocdaniel@hadoop102 ~]$ mkdir bin
- [kocdaniel@hadoop102 ~]$ cd bin/
- [kocdaniel@hadoop102 bin]$ vim xsync
在文件中編寫如下腳本代碼
- #!/bin/bash
- #1 獲取輸入參數個數,如果沒有參數,直接退出
- pcount=$#
- if((pcount==0)); then
- echo no args;
- exit;
- fi
- #2 獲取文件名稱
- p1=$1
- fname=`basename $p1`
- echo fname=$fname
- #3 獲取上級目錄到絕對路徑 –P指向實際物理地址,防止軟連接
- pdir=`cd -P $(dirname $p1); pwd`
- echo pdir=$pdir
- #4 獲取當前用戶名稱
- user=`whoami`
- #5 循環
- for((host=103; host<105; host++)); do
- echo ------------------- hadoop$host --------------
- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
- done
- 修改腳本xsync具有執行權限,并調用腳本,將腳本復制到103和104節點
- [kocdaniel@hadoop102 bin]$ chmod 777 xsync
- [kocdaniel@hadoop102 bin]$ xsync /home/atguigu/bin
集群配置
1.集群部署規劃

由于計算機配置有限,只能使用三臺虛擬機,工作環境中根據需要規劃集群
2.配置集群
切換到hadoop安裝目錄/etc/hadoop/
- 配置core-site.xml
- [kocdaniel@hadoop102 hadoop]$ vim core-site.xml
- # 在文件中寫入如下內容
- <!-- 指定HDFS中NameNode的地址 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop102:9000</value>
- </property>
- <!-- 指定Hadoop運行時產生文件的存儲目錄 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/module/hadoop-2.7.2/data/tmp</value>
- </property>
- HDFS配置文件
配置hadoop-env.sh
- [kocdaniel@hadoop102 hadoop]$ vim hadoop-env.sh
- export JAVA_HOME=/opt/module/jdk1.8.0_144
export JAVA_HOME=/opt/module/jdk1.8.0_144
注意:我們已經在/etc/profile文件中配置了JAVA_HOME,這里為什么還需要配置JAVA_HOME?
答:因為Hadoop運行是守護進程(守護進程是一個在后臺運行并且不受任何終端控制的進程。--摘自百度百科)),正是因為它后臺運行,不接受任何終端控制,所以它讀取不到我們配置好的環境變量,所以這里需要單獨配置一下。
- 配置hdfs-site.xml
- [kocdaniel@hadoop102 hadoop]$ vim hdfs-site.xml
- # 寫入如下配置
- <!-- 配置副本數量為3,默認也為3,所以這個也可以刪掉 -->
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <!-- 指定Hadoop輔助名稱節點主機配置 -->
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoop104:50090</value>
- </property>
- YARN配置文件
配置yarn-env.sh
- [kocdaniel@hadoop102 hadoop]$ vim yarn-env.sh
- export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
- [kocdaniel@hadoop102 hadoop]$ vi yarn-site.xml
- # 增加如下配置
- <!-- Reducer獲取數據的方式 -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <!-- 指定YARN的ResourceManager的地址 -->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>hadoop103</value>
- </property>
- MapReduce配置文件
配置mapred-env.sh
- [kocdaniel@hadoop102 hadoop]$ vim mapred-env.sh
- export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
- # 如果是第一次配置的話,需要先將mapred-site.xml.template重命名為mapred-site.xml
- [kocdaniel@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
- [kocdaniel@hadoop102 hadoop]$ vim mapred-site.xml
- # 在文件中增加如下配置
- <!-- 指定MR運行在Yarn上 -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
3.將配置好的文件利用集群分發腳本同步到hadoop103和hadoop104節點
- [kocdaniel@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/
- 最好在同步完成之后檢查一下同步結果,避免錯誤
單點啟動
1.如果是第一次啟動,需要格式化namenode,否則跳過此步
- [kocdaniel@hadoop102 hadoop-2.7.2]$ hadoop namenode -format
- 格式化需要注意的問題:
- 只有第一次啟動需要格式化,以后不要總是格式化,否則會出現namenode和datanode的集群id不一致的情況,導致datanode啟動失敗
- 正確的格式化姿勢:
- 在執行第一次格式化時會在hadoop安裝目錄下產生data文件夾,里面會生成namenode的信息
- 在啟動namenode和datanode后,還會在同樣的目錄下產生logs的日志文件夾
- 所以在格式化之前需要先將這兩個文件夾刪除,然后再格式化,最后啟動namenode和datanode
2.在hadoop102上啟動namenode
- [kocdaniel@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start namenode
- [kocdaniel@hadoop102 hadoop-2.7.2]$ jps
- 3461 NameNode
3.在hadoop102、hadoop103以及hadoop104上分別啟動DataNode
- [kocdaniel@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
- [kocdaniel@hadoop102 hadoop-2.7.2]$ jps
- 3461 NameNode
- 3608 Jps
- 3561 DataNode
- [kocdaniel@hadoop103 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
- [kocdaniel@hadoop103 hadoop-2.7.2]$ jps
- 3190 DataNode
- 3279 Jps
- [kocdaniel@hadoop104 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
- [kocdaniel@hadoop104 hadoop-2.7.2]$ jps
- 3237 Jps
- 3163 DataNode
4.訪問hadoop102:50070查看結果
- 但是以上單點啟動有一個問題:
每次都一個一個節點啟動,如果節點數增加到1000個怎么辦?
配置ssh免密登錄
1.配置ssh
ssh 另一個節點的ip 就可以切換到另一臺機器,但是得輸入密碼
2.免密ssh配置
免密登錄原理
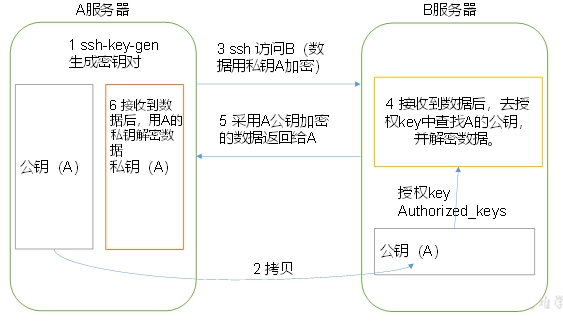
- 在配置namenode的主機hadoop102上生成私鑰和公鑰
切換目錄到/home/用戶名/.ssh/
- [kocdaniel@hadoop102 .ssh]$ ssh-keygen -t rsa
- - 然后敲(三個回車),就會生成兩個文件id_rsa(私鑰)、id_rsa.pub(公鑰)
- - 將公鑰拷貝到要免密登錄的目標機器上
- ```shell
- [kocdaniel@hadoop102 .ssh]$ ssh-copy-id hadoop103
- [kocdaniel@hadoop102 .ssh]$ ssh-copy-id hadoop104
- # 注意:ssh訪問自己也需要輸入密碼,所以我們需要將公鑰也拷貝給102
- [kocdaniel@hadoop102 .ssh]$ ssh-copy-id hadoop102
- ```
- 同樣,在配置resourcemanager的主機hadoop103上執行同樣的操作,然后就可以群起集群了
群起集群
1.配置slaves
- 切換目錄到:hadoop安裝目錄/etc/hadoop/
- 在目錄下的slaves文件中添加如下內容
- [kocdaniel@hadoop102 hadoop]$ vim slaves
- # 注意結尾不能有空格,文件中不能有空行
- hadoop102
- hadoop103
- hadoop104
- 同步所有節點的配置文件
- [kocdaniel@hadoop102 hadoop]$ xsync slaves
2.啟動集群
- 同樣,如果是第一次啟動,需要格式化
- 啟動HDFS
- [kocdaniel@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
- # 查看啟動結果,和集群規劃(配置文件中)的一致
- [atguigu@hadoop102 hadoop-2.7.2]$ jps
- 4166 NameNode
- 4482 Jps
- 4263 DataNode
- [atguigu@hadoop103 hadoop-2.7.2]$ jps
- 3218 DataNode
- 3288 Jps
- [atguigu@hadoop104 hadoop-2.7.2]$ jps
- 3221 DataNode
- 3283 SecondaryNameNode
- 3364 Jps
- 啟動YARN
- # 注意:NameNode和ResourceManger如果不是同一臺機器,不能在NameNode上啟動 YARN,應該在ResouceManager所在的機器上啟動YARN
- [kocdaniel@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
3.web端查看相關信息
責任編輯:華軒
來源:
segmentfault