MapReduce Hold不住?
本文系統地介紹和分析比較了業界主流的Yahoo! S4、StreamBase和Borealis三種流式計算系統,希望讀者能從這些系統的設計中領悟到不同場景下流式計算所要解決的關鍵問題。
背景
非實時計算幾乎都基于MapReduce計算框架,但MapReduce并不是***的。對于搜索應用環境中的某些現實問題,MapReduce并不能很好地解決問題。
什么是MapReduce?
MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行運算。
商用搜索引擎,像Google、Bing和Yahoo!等,通常在用戶查詢響應中提供結構化的Web結果,同時也插入基于流量的點擊付費模式的文本廣告。為了在頁面上***位置展現最相關的廣告,通過一些算法來動態估算給定上下文中一個廣告被點擊的可能性。上下文可能包括用戶偏好、地理位置、歷史查詢、歷史點擊等信息。一個主搜索引擎可能每秒鐘處理成千上萬次查詢,每個頁面都可能會包含多個廣告。為了及時處理用戶反饋,需要一個低延遲、可擴展、高可靠的處理引擎。然而,對于這些實時性要求很高的應用,盡管MapReduce作了實時性改進,但仍很難穩定地滿足應用需求。因為Hadoop為批處理作了高度優化,MapReduce系統典型地通過調度批量任務來操作靜態數據;而流式計算的典型范式之一是不確定數據速率的事件流流入系統,系統處理能力必須與事件流量匹配,或者通過近似算法等方法優雅降級,通常稱為負載分流(load-shedding)。當然,除了負載分流,流式計算的容錯處理等機制也和批處理計算不盡相同。
最近Facebook在Sigmod 11上發表了利用HBase/Hadoop進行實時數據處理的論文,通過一些實時性改造,讓批處理計算平臺也具備實時計算的能力。這類基于MapReduce進行流式處理的方案有三個主要缺點。
- 將輸入數據分隔成固定大小的片段,再由MapReduce平臺處理,缺點在于處理延遲與數據片段的長度、初始化處理任務的開銷成正比。小的分段會降低延遲,增加附加開銷,并且分段之間的依賴管理更加復雜(例如一個分段可能會需要前一個分段的信息);反之,大的分段會增加延遲。***的分段大小取決于具體應用。
- 為了支持流式處理,MapReduce需要被改造成Pipeline的模式,而不是Reduce直接輸出;考慮到效率,中間結果***只保存在內存中等。這些改動使得原有的MapReduce框架的復雜度大大增加,不利于系統的維護和擴展。
- 用戶被迫使用MapReduce的接口來定義流式作業,這使得用戶程序的可伸縮性降低。
綜上所述,流式處理的模式決定了要和批處理使用非常不同的架構,試圖搭建一個既適合流式計算又適合批處理計算的通用平臺,結果可能會是一個高度復雜的系統,并且最終系統可能對兩種計算都不理想。
目前流式計算是業界研究的一個熱點,最近Twitter、LinkedIn等公司相繼開源了流式計算系統Storm、Kafka等,加上 Yahoo!之前開源的S4,流式計算研究在互聯網領域持續升溫。不過流式計算并非最近幾年才開始研究,傳統行業像金融領域等很早就已經在使用流式計算系統,比較知名的有StreamBase、Borealis等。
本文簡單介紹幾種業界使用的流式計算系統,希望流式系統的設計者或開發者們能從中獲得啟示。
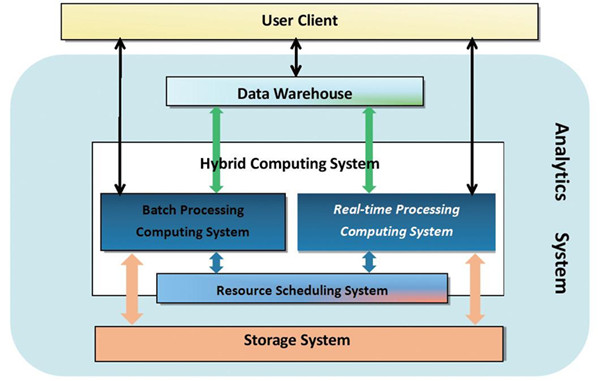
圖1 數據分析系統整體組成示意圖
圖1從整個分析系統的架構角度,給出了實時計算子系統所處的位置。實時計算系統和批處理計算系統同屬于計算這個大的范疇,批處理計算可以是 MapReduce、MPI、SCOPE等,實時計算可以是S4、Storm等,批處理和實時都可以或不依賴統一的資源調度系統。另外,計算系統的輸入、輸出,包括中間過程的輸入、輸出,都與存儲系統交互,可以是塊存儲系統HDFS,也可以是K-V存儲系統Hypertable等。計算層的上層是數據倉庫,或者直接和用戶交互,交互方式可以是SQL-like或者MR-like等。
【編輯推薦】