MapReduce運行原理
MapReduce是一種編程模型,用于大規(guī)模數(shù)據(jù)集(大于1TB)的并行運算。MapReduce采用”分而治之”的思想,把對大規(guī)模數(shù)據(jù)集的操作,分發(fā)給一個主節(jié)點管理下的各個分節(jié)點共同完成,然后通過整合各個節(jié)點的中間結(jié)果,得到最終結(jié)果。簡單地說,MapReduce就是”任務(wù)的分解與結(jié)果的匯總”。
MapReduce架構(gòu)
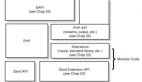
先來看一下MapReduce1.0的架構(gòu)圖
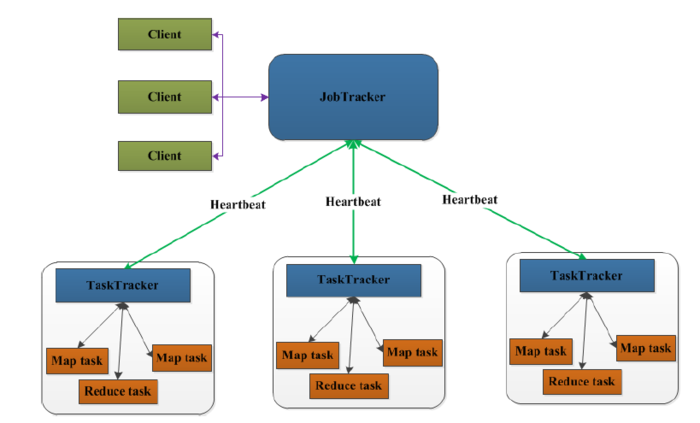
上圖中的TaskTracker對應(yīng)HDFS中的DataNode,
在MapReduce1.x中,用于執(zhí)行MapReduce任務(wù)的機器角色有兩個:一個是JobTracker;另一個是TaskTracker,JobTracker是用于調(diào)度工作的,TaskTracker是用于執(zhí)行工作的。一個Hadoop集群中只有一臺JobTracker。
流程分析
- 在客戶端啟動任務(wù),客戶端向JobTracker請求一個Job ID。
- 將運行任務(wù)所需要的程序文件復(fù)制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客戶端計算所得的輸入劃分信息。這些文件都存放在JobTracker專門為該任務(wù)創(chuàng)建的文件夾中。文件夾名Job ID。
- JobTracker接收到任務(wù)后,將其放在一個隊列里,等待調(diào)度器對其進行調(diào)度,當作業(yè)調(diào)度器根據(jù)自己的調(diào)度算法調(diào)度到該任務(wù)時,會根據(jù)輸入劃分信息創(chuàng)建N個map任務(wù),并將map任務(wù)分配給N個TaskTracker(DataNode)執(zhí)行。
- map任務(wù)不是隨隨便便地分配給某個TaskTracker的,這里有個概念叫:數(shù)據(jù)本地化(Data-Local)。意思是:將map任務(wù)分配給含有該map處理的數(shù)據(jù)塊的TaskTracker上,同時將程序JAR包復(fù)制到該TaskTracker上來運行,這叫“運算移動,數(shù)據(jù)不移動”。而分配reduce任務(wù)時并不考慮數(shù)據(jù)本地化。
- TaskTracker每隔一段時間會給JobTracker發(fā)送一個Heartbeat(心跳),告訴JobTracker它依然在運行,同時心跳中還攜帶著很多的信息,比如當前map任務(wù)完成的進度等信息。當JobTracker收到作業(yè)的***一個任務(wù)完成信息時,便把該作業(yè)設(shè)置成“成功”。當JobClient查詢狀態(tài)時,它將得知任務(wù)已完成,便顯示一條消息給用戶。
以上是在客戶端、JobTracker、TaskTracker的層次來分析MapReduce的工作原理的,下面我們再細致一點,從map任務(wù)和reduce任務(wù)的層次來分析分析吧。
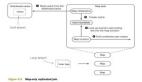
MapReduce運行流程
以wordcount為例,運行的詳細流程圖如下
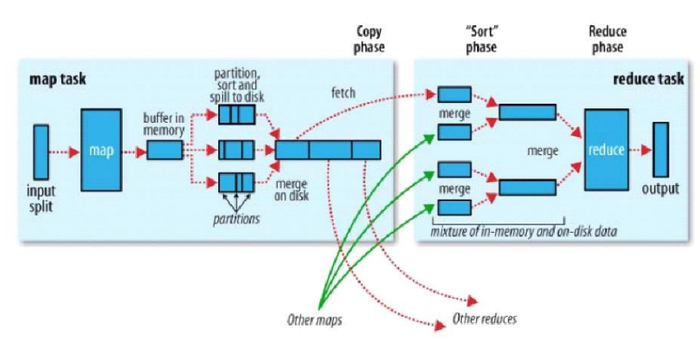
1.split階段
首先mapreduce會根據(jù)要運行的大文件來進行split,每個輸入分片(input split)針對一個map任務(wù),輸入分片(input split)存儲的并非數(shù)據(jù)本身,而是一個分片長度和一個記錄數(shù)據(jù)位置的數(shù)組。輸入分片(input split)往往和HDFS的block(塊)關(guān)系很密切,假如我們設(shè)定HDFS的塊的大小是64MB,我們運行的大文件是64x10M,mapreduce會分為10個map任務(wù),每個map任務(wù)都存在于它所要計算的block(塊)的DataNode上。
2.map階段
map階段就是程序員編寫的map函數(shù)了,因此map函數(shù)效率相對好控制,而且一般map操作都是本地化操作也就是在數(shù)據(jù)存儲節(jié)點上進行。本例的map函數(shù)如下:
- publicclassWCMapperextendsMapperLongWritable,Text,Text,IntWritable{@Override
- protectedvoidmap(LongWritablekey,Textvalue,Contextcontext)throwsIOException,InterruptedException{
- Stringstr=value.toString();
- String[]strs=StringUtils.split(str,'');for(Strings:strs){
- context.write(newText(s),newIntWritable(1));
- }
- }
- }
根據(jù)空格切分單詞,計數(shù)為1,生成key為單詞,value為出現(xiàn)1次的map供后續(xù)計算。
3.shuffle階段
shuffle階段主要負責將map端生成的數(shù)據(jù)傳遞給reduce端,因此shuffle分為在map端的過程和在reduce端的執(zhí)行過程。
先看map端:
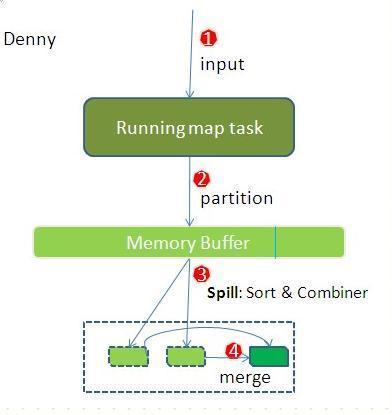
- map首先進行數(shù)據(jù)結(jié)果數(shù)據(jù)屬于哪個partition的判斷,其中一個partition對應(yīng)一個reduce,一般通過key.hash()%reduce個數(shù)來實現(xiàn)。
- 把map數(shù)據(jù)寫入到Memory Buffer(內(nèi)存緩沖區(qū)),到達80%閥值,開啟溢寫進磁盤過程,同時進行key排序,如果有combiner步驟,則會對相同的key做歸并處理,最終多個溢寫文件合并為一個文件。
reduce端:
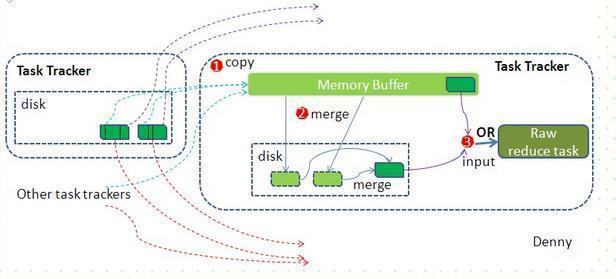
reduce節(jié)點從各個map節(jié)點拉取存在磁盤上的數(shù)據(jù)放到Memory Buffer(內(nèi)存緩沖區(qū)),同理將各個map的數(shù)據(jù)進行合并并存到磁盤,最終磁盤的數(shù)據(jù)和緩沖區(qū)剩下的20%合并傳給reduce階段。
4.reduce階段
reduce對shuffle階段傳來的數(shù)據(jù)進行***的整理合并
- publicclassWCReducerextendsReducerText,IntWritable,Text,IntWritable{@Override
- protectedvoidreduce(Textkey,IterableIntWritablevalues,Contextcontext)throwsIOException,InterruptedException{intsum=0;for(IntWritablei:values){
- sum+=i.get();
- }
- context.write(key,newIntWritable(sum));
- }
- }
MapReduce的優(yōu)缺點
優(yōu)點:
- 易于編程;
- 良好的擴展性;
- 高容錯性;
4.適合PB級別以上的大數(shù)據(jù)的分布式離線批處理。
缺點:
- 難以實時計算(MapReduce處理的是存儲在本地磁盤上的離線數(shù)據(jù))
- 不能流式計算(MapReduce設(shè)計處理的數(shù)據(jù)源是靜態(tài)的)
- 難以DAG計算MapReduce這些并行計算大都是基于非循環(huán)的數(shù)據(jù)流模型,也就是說,一次計算過程中,不同計算節(jié)點之間保持高度并行,這樣的數(shù)據(jù)流模型使得那些需要反復(fù)使用一個特定數(shù)據(jù)集的迭代算法無法高效地運行。