













大數(shù)據(jù):“人工特征工程+線性模型”的盡頭
標(biāo)簽:大數(shù)據(jù)機(jī)器學(xué)習(xí)特征工程11年的時(shí)候我加入百度,在鳳巢使用機(jī)器學(xué)習(xí)來(lái)做廣告點(diǎn)擊預(yù)測(cè)。當(dāng)時(shí)非常驚訝于過(guò)去兩年內(nèi)訓(xùn)練數(shù)據(jù)如此瘋狂的增長(zhǎng)。大家都在熱情的談特征,每次新特征的加入都能立即得到AUC的提升和收入的增長(zhǎng)。大家堅(jiān)信特征才是王道,相信還會(huì)有源源不斷的特征加入,數(shù)據(jù)規(guī)模還會(huì)成倍的增長(zhǎng)。我也深受感染,堅(jiān)定的相信未來(lái)兩年數(shù)據(jù)至少還會(huì)長(zhǎng)十倍,因此一切的工作都圍繞這個(gè)假設(shè)進(jìn)行。現(xiàn)在兩年過(guò)去了,回過(guò)頭來(lái)看,當(dāng)時(shí)的預(yù)測(cè)是正確的嗎?
數(shù)據(jù)的飛速增長(zhǎng),給模型訓(xùn)練帶來(lái)極大壓力。事實(shí)上,11年的時(shí)候模型訓(xùn)練已經(jīng)是新特征上線的主要障礙了。憑著年輕的沖動(dòng),和對(duì)分布式系統(tǒng)和數(shù)值算法優(yōu)化的一點(diǎn)點(diǎn)知識(shí),我頭腦一熱就開(kāi)始設(shè)計(jì)下一代模型訓(xùn)練系統(tǒng)了。目標(biāo)是在同樣的資源下,能容納當(dāng)前十倍的數(shù)據(jù)。項(xiàng)目是在情人節(jié)立項(xiàng),取了一個(gè)好玩的名字,叫darlin【吐槽1】,這個(gè)系統(tǒng)應(yīng)該是百度使用率***的機(jī)器學(xué)習(xí)訓(xùn)練系統(tǒng)之一了。一個(gè)重要問(wèn)題是,它會(huì)像前任一樣在兩年后成為性能瓶頸嗎?
目前看來(lái),以上兩個(gè)問(wèn)題的答案都是否定的。
【吐槽1】意思是distributed algorithm for linear problems。更好玩的是,計(jì)算核心模塊叫heart,絡(luò)通訊模塊叫telesthesia。數(shù)據(jù)是用類(lèi)似bigtable的格式,叫cake,因?yàn)榍衅饋?lái)很像蛋糕。開(kāi)發(fā)的時(shí)候開(kāi)玩笑說(shuō),以后上線了就會(huì)時(shí)不時(shí)聽(tīng)人說(shuō)“darlin”,是 不是會(huì)很有意思?可惜全流量上線后我就直奔CMU了,沒(méi)享受到這個(gè)樂(lè)趣:)
我們首先討論特征。特征是機(jī)器學(xué)習(xí)系統(tǒng)的原材料,對(duì)最終模型的影響是毋庸置疑的。如果數(shù)據(jù)被很好的表達(dá)成了特征,通常線性模型就能達(dá)到滿意的精度。一個(gè)使用機(jī)器學(xué)習(xí)的典型過(guò)程是:提出問(wèn)題并收集數(shù)據(jù),理解問(wèn)題和分析數(shù)據(jù)繼而提出抽取特征方案,使用機(jī)器學(xué)習(xí)建模得到預(yù)測(cè)模型。第二步是特征工程,如果主要是人來(lái)完成的話,我們稱(chēng)之為人工特征工程(human feature engineering)。舉個(gè)例子,假設(shè)要做一個(gè)垃圾郵件的過(guò)濾系統(tǒng),我們先收集大量用戶郵件和對(duì)應(yīng)的標(biāo)記,通過(guò)觀察數(shù)據(jù)我們合理認(rèn)為,標(biāo)題和正文含有“交友“、”發(fā)票“、”免費(fèi)促銷(xiāo)“等關(guān)鍵詞的很可能是垃圾郵件。于是我們構(gòu)造bag-of-word特征。繼而使用線性logisitic regression來(lái)訓(xùn)練得到模型,最終把模型判斷成是垃圾郵件的概率大于某個(gè)值的郵件過(guò)濾掉。
就這樣搞定啦?沒(méi)有。特征工程是一個(gè)長(zhǎng)期的過(guò)程。為了提升特征質(zhì)量,需要不斷的提出新特征。例如,通過(guò)分析bad case,不久我們便發(fā)現(xiàn),如果郵件樣式雜亂含有大量顏色文字和圖片,大概率是垃圾郵件。于是我們加入一個(gè)樣式特征。又通過(guò)頭腦風(fēng)暴,我們認(rèn)為如果一個(gè)長(zhǎng)期使用中文的人收到俄語(yǔ)的郵件,那估計(jì)收到的不是正常郵件,可以直接過(guò)濾掉。于是又加入字符編碼這一新特征。再通過(guò)苦苦搜尋或買(mǎi)或央求,我們得到一個(gè)數(shù)據(jù)庫(kù)包含了大量不安全ip和發(fā)信地址,于是可以加入不安全來(lái)源這一新特征。通過(guò)不斷的優(yōu)化特征,系統(tǒng)的準(zhǔn)確性和覆蓋性不斷的提高,這又驅(qū)使我們繼續(xù)追求新特征。
由此可以看出,特征工程建立在不斷的深入理解問(wèn)題和獲取額外的數(shù)據(jù)源上。但問(wèn)題是,通常根據(jù)數(shù)據(jù)人能抽象出來(lái)的特征總類(lèi)很有限。例如,廣告點(diǎn)擊預(yù)測(cè),這個(gè)被廣告投放公司做得最透徹的問(wèn)題,目前能抽象出來(lái)的特征完全可以寫(xiě)在一張幻燈片里。好理解的、方便拿來(lái)用的、干凈的數(shù)據(jù)源也不會(huì)很多,對(duì)于廣告無(wú)外乎是廣告本身信息(標(biāo)題、正文、樣式),廣告主信息(行業(yè)、地理位置、聲望),和用戶信息(性別、年齡、收入等個(gè)人信息,cookie、session等點(diǎn)擊信息)。KDD CUP2013騰訊提供了廣告點(diǎn)擊預(yù)測(cè)的數(shù)據(jù),就包含了其中很多。所以最終能得到的特征類(lèi)數(shù)上限也就是數(shù)百。另外一個(gè)例子是,google使用的數(shù)據(jù)集里每個(gè)樣本含有的特征數(shù)平均不超過(guò)100,可以推斷他們的特征類(lèi)數(shù)最多也只是數(shù)百。
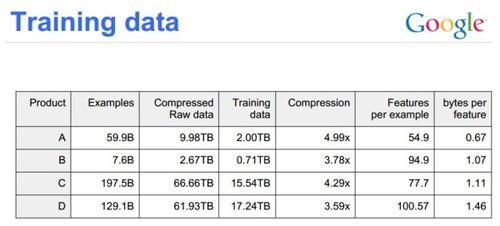
圖1
因此,新數(shù)據(jù)源和新特征的獲得會(huì)越來(lái)越難。然而,模型的精度并不是隨著特征的增長(zhǎng)而線性提高。很多情況是指數(shù)。隨著人工特征工程的深入,投入的人力和時(shí)間越來(lái)越長(zhǎng),得到的新特征對(duì)系統(tǒng)的提升卻越來(lái)越少。最終,系統(tǒng)性能看上去似乎是停止增長(zhǎng)了。Robin曾問(wèn)過(guò)我老大一個(gè)問(wèn)題:“機(jī)器學(xué)習(xí)還能持續(xù)為百度帶來(lái)收益嗎?” 但時(shí)候我的***反應(yīng)是,這個(gè)商人!現(xiàn)在想一想,Robin其實(shí)挺高瞻遠(yuǎn)矚。
另外一個(gè)例子是IBM的Watson。從下圖中可以看出,雖然每次性能的提升基本都是靠引入了新數(shù)據(jù)和新特征,但提升幅度是越來(lái)越小,也越來(lái)越艱難。
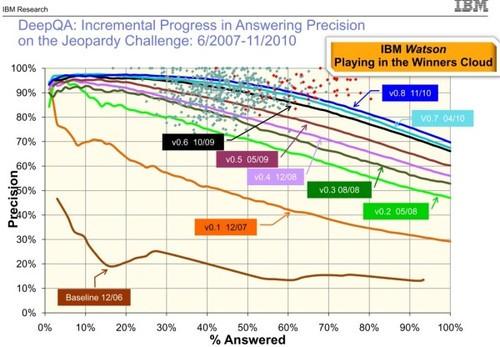
圖2
這解釋了***個(gè)問(wèn)題,為什么特征數(shù)量的漲幅比當(dāng)初預(yù)計(jì)的要少很多。一個(gè)特征團(tuán)隊(duì),5個(gè)經(jīng)驗(yàn)豐富的大哥加上10個(gè)動(dòng)手強(qiáng)的小弟,幾個(gè)月就能把可能的特征發(fā)掘得差不多,然后再用1、2年把特征全部做進(jìn)系統(tǒng)。再然后呢?就會(huì)被發(fā)現(xiàn)有點(diǎn)后續(xù)無(wú)力了,進(jìn)入中年穩(wěn)定期了。
接下來(lái)討論模型訓(xùn)練,因?yàn)椴幌氡豢鐕?guó)追捕所以主要用google sibyl?來(lái)舉例子。Sibyl是一個(gè)線性分類(lèi)器,支持多種常見(jiàn)loss,例如logistc loss,square loss,hingle loss。還可以使用l2罰,或者l1罰來(lái)得到稀疏模型。Sibyl每天要被運(yùn)行數(shù)百次,被廣泛應(yīng)用在google的搜索,gmail,youtube等應(yīng)用上。由于這些應(yīng)用直接關(guān)系到用戶體驗(yàn)和收入,通常需要得到收斂精度很高而且收斂點(diǎn)穩(wěn)定的模型。因?yàn)橐粋€(gè)有著數(shù)百億項(xiàng)的模型,如果收斂不夠,即使只是少數(shù)特征上權(quán)重計(jì)算誤差過(guò)大,也很容易引起bad case。同時(shí),應(yīng)用也希望模型的輸出在一段時(shí)間是穩(wěn)定的。
Sibyl使用parallel boosting,而darin用了一個(gè)更生僻的算法。后來(lái)聽(tīng)說(shuō)了linkedin,yahoo,facebook的算法之后,狠下心survey了一些古老的優(yōu)化論文,發(fā)現(xiàn)雖然大家名字各不相同,但其實(shí)都等價(jià)的【吐槽2】。在合適算法下,收斂到所要求的精度通常只需要數(shù)十論迭代。而且隨著數(shù)據(jù)量的增大迭代數(shù)還會(huì)進(jìn)一步降低。更多的,在online/incremental的情況下,還能更進(jìn)一步大幅減少。 #p#
【吐槽2】在嘗試過(guò)ml人最近一些年做的一系列算法后發(fā)現(xiàn),它們真心只是研究目的:(
然后是工程實(shí)現(xiàn)。google有強(qiáng)大的底層支持,例如GFS,Mapreduce,BigTable,最近幾年更是全部更新了這一套。所以sibyl的實(shí)現(xiàn)應(yīng)該是相當(dāng)輕松。但即使是從0開(kāi)始,甚至不借助hadoop和mpi,也不是特別復(fù)雜。純C開(kāi)發(fā),只是用GCC的情況下,代碼量也只是數(shù)萬(wàn)行。主要需要考慮的是數(shù)據(jù)格式,計(jì)算,和網(wǎng)絡(luò)通訊。數(shù)據(jù)格式首先考慮壓縮率,可以大量節(jié)省I/O時(shí)間,其次是空間連續(xù)性(space locality)。但通常數(shù)據(jù)都遠(yuǎn)超last level cache,也不需要顧慮太多。計(jì)算可以用一些常見(jiàn)小技巧,例如少用鎖,線程分配的計(jì)算量要盡量均勻(稀疏數(shù)據(jù)下并不容易),double轉(zhuǎn)float,甚至是int來(lái)計(jì)算,buffer要管理好不要不斷的new和delete,也不要太浪費(fèi)內(nèi)存。網(wǎng)絡(luò)稍微復(fù)雜一點(diǎn),要大致了解集群的拓?fù)浣Y(jié)構(gòu),注意不要所有機(jī)器同時(shí)大量收發(fā)打爆了交換機(jī),從而引起大量重傳(這個(gè)經(jīng)常發(fā)生),盡量少的做集群同步。
考察了幾個(gè)公司的系統(tǒng)性能后,可以認(rèn)為現(xiàn)在state-of-the-art的性能標(biāo)準(zhǔn)是,100T數(shù)據(jù),通常包含幾千億樣本,幾百億特征,200臺(tái)機(jī)器,收斂精度要求大致等于L-BFGS 150輪迭代后的精度,可以在2小時(shí)內(nèi)訓(xùn)練完成。如果用online/incremental模式,時(shí)間還可以大幅壓縮。例如,使用67T數(shù)據(jù)和1000核,Sibyl在不到一個(gè)小時(shí)可以完成訓(xùn)練。
這回答了前面的第二個(gè)問(wèn)題。假設(shè)特征不會(huì)突增,那么數(shù)據(jù)的主要增長(zhǎng)點(diǎn)就是樣本的累積。這只是一個(gè)線性的增長(zhǎng)過(guò)程,而硬件的性能和規(guī)模同時(shí)也在線性增長(zhǎng)。目前來(lái)看效率已經(jīng)很讓人滿意。所以一個(gè)有著適當(dāng)優(yōu)化算法和良好工程實(shí)現(xiàn)的系統(tǒng)會(huì)勝任接下來(lái)一兩年的工作。
在人工特征工程下,隨著可用的新數(shù)據(jù)源和新特征的獲取越來(lái)越困難,數(shù)據(jù)的增長(zhǎng)會(huì)進(jìn)入慢速期。而硬件的發(fā)展使得現(xiàn)有系統(tǒng)能完全勝任未來(lái)幾年內(nèi)的工作量,因此人工特征工程加線性模型的發(fā)展模式進(jìn)入了后期:它會(huì)隨著數(shù)據(jù)和計(jì)算成本的降低越來(lái)越普及,但卻無(wú)法滿足已經(jīng)獲得收益而希求更多的人的期望。
所以,然后呢?我來(lái)拋磚引玉:)
還是先從特征開(kāi)始。正如任何技術(shù)一樣,機(jī)器學(xué)習(xí)在過(guò)去20年里成功的把很多人從機(jī)械勞動(dòng)里解救了出來(lái),是時(shí)候再來(lái)解救特征專(zhuān)家們了。因?yàn)榫€性分類(lèi)系統(tǒng)有足夠的性能來(lái)支撐更多的數(shù)據(jù),所以我們可以用它來(lái)做更加復(fù)雜的事情。一個(gè)簡(jiǎn)單的想法是自動(dòng)組合特征,通過(guò)目標(biāo)函數(shù)值的降低或者精度的提升來(lái)啟發(fā)式的搜索特征的組合。此外,Google最近的deep learning項(xiàng)目【吐槽3】展現(xiàn)另外一種可能,就是從原始數(shù)據(jù)中構(gòu)造大量的冗余特征。這些特征雖然質(zhì)量不如精心構(gòu)造的特征來(lái)得好,但如果數(shù)量足夠多,極有可能得到比以前更好的模型。他們使用的算法結(jié)合了ICA和sparse coding的優(yōu)點(diǎn),從100x100圖片的原始pixel信息中抽取上十億的特征。雖然他們算法現(xiàn)在有嚴(yán)重的scalability的問(wèn)題,但卻可以啟發(fā)出很多新的想法。 #p#
【吐槽3】中文介紹請(qǐng)見(jiàn)余老師的文章。我個(gè)人覺(jué)得這個(gè)項(xiàng)目更多是關(guān)于提取特征。引用Quoc來(lái)CMU演講時(shí)說(shuō)的兩點(diǎn)。一、為了減少數(shù)據(jù)通訊量和提升并行效率,每一層只與下層部分節(jié)點(diǎn)相連。因此需要多層來(lái)使得局部信息擴(kuò)散到高層。如果計(jì)算能力足夠,單層也可能是可以的。二、如果只使用DL來(lái)得到的特征,但用線性分類(lèi)器來(lái)訓(xùn)練,還可以提升訓(xùn)練精度。
模型方面,線性模型雖然簡(jiǎn)單,但實(shí)際上是效果最差的模型。鑒于計(jì)算能力的大量冗余,所以是時(shí)候奔向更廣闊的天空了。在廣告點(diǎn)擊預(yù)測(cè)那個(gè)例子里,數(shù)據(jù)至少可以表示成一個(gè)四緯的張量:展現(xiàn) x廣告 x 廣告主 x 用戶。線性模型簡(jiǎn)單粗暴把它壓成了一個(gè)2維矩陣,明顯丟掉了很多信息。一個(gè)可能的想法是用張量分解(現(xiàn)在已經(jīng)有了很高效的算法)來(lái)找出這些內(nèi)在的聯(lián)系。另一方面,點(diǎn)擊預(yù)測(cè)的最終目的是來(lái)對(duì)廣告做排序,所以這個(gè)本質(zhì)是一個(gè)learning to rank的問(wèn)題,而不是一個(gè)簡(jiǎn)單的分類(lèi)問(wèn)題。例如可以嘗試boosted decision tree。
再有,最近大家都在談神經(jīng)網(wǎng)絡(luò)。多層神經(jīng)網(wǎng)絡(luò)理論上可以逼近任何一個(gè)函數(shù),但由于計(jì)算復(fù)雜、參數(shù)過(guò)多、容易過(guò)擬合等特點(diǎn)被更加簡(jiǎn)單的kernel svm取代了。但現(xiàn)在的數(shù)據(jù)規(guī)模和計(jì)算能力完全不同當(dāng)年,神經(jīng)網(wǎng)絡(luò)又再一次顯示它的威力,hinton又再一次走向了職業(yè)生涯的***。微軟的語(yǔ)音實(shí)時(shí)翻譯是一個(gè)很好的樣例。反過(guò)來(lái)說(shuō),有多少人真正試過(guò)百億樣本級(jí)別kernel svm?至少,據(jù)小道消息說(shuō),多項(xiàng)式核在語(yǔ)音數(shù)據(jù)上效果很好。
我的結(jié)論是,大數(shù)據(jù)時(shí)代,雖然人工特征工程和線性模型將會(huì)被更廣泛的事情,但它只是大數(shù)據(jù)應(yīng)用的起點(diǎn)。而且,我們應(yīng)該要邁過(guò)這個(gè)起點(diǎn)了。
















