人工智能在線特征系統中的數據存取技術
一、在線特征系統
主流互聯網產品中,不論是經典的計算廣告、搜索、推薦,還是垂直領域的路徑規劃、司機派單、物料智能設計,建立在人工智能技術之上的策略系統已經深入到了產品功能的方方面面。相應的,每一個策略系統都離不開大量的在線特征,來支撐模型算法或人工規則對請求的精準響應,因此特征系統成為了支持線上策略系統的重要支柱。美團點評技術博客之前推出了多篇關于特征系統的文章,如《機器學習中的數據清洗與特征處理綜述》側重于介紹特征生產過程中的離線數據清洗、挖掘方法,《業務賦能利器之外賣特征檔案》側重于用不同的存儲引擎解決不同的特征數據查詢需求。而《外賣排序系統特征生產框架》側重介紹了特征計算、數據同步和線上查詢的特征生產Pipeline。
本文以美團酒旅在線特征系統為原型,重點從線上數據存取角度介紹一些實踐中的通用技術點,以解決在線特征系統在高并發情形下面臨的問題。
1.1 在線特征系統框架——生產、調度、服務一體化
在線特征系統就是通過系統上下文,獲得相關特征數據的在線服務。其功能可以是一個簡單的Key-Value(KV)型存儲,對線上提供特征查詢服務,也可以輻射到通用特征生產、統一特征調度、實時特征監控等全套特征服務體系。可以說,幾個人日就可以完成一個簡單能用的特征系統,但在復雜的業務場景中,把這件事做得更方便、快速和穩定,卻需要一個團隊長期的積累。
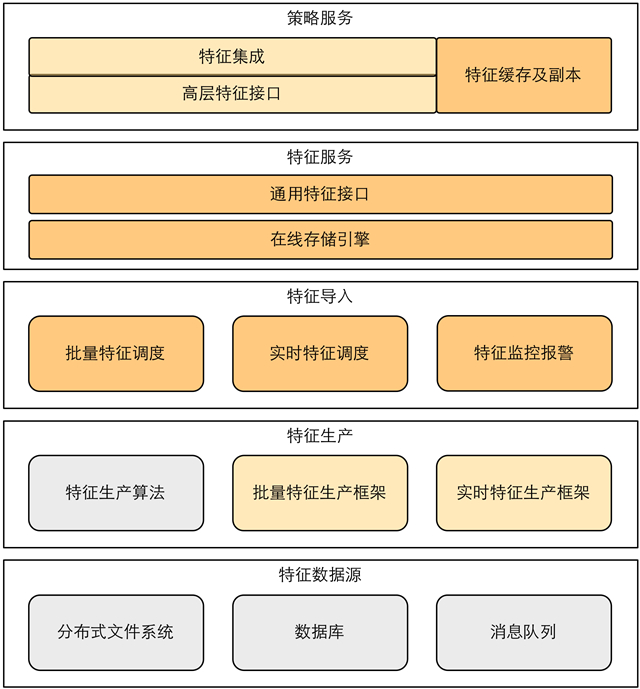
以上結構圖為一體化特征系統的概貌,自底向上為數據流動的方向,各部分的功能如下:
- 數據源:用于計算特征的原始數據。根據業務需求,數據來源可能是分布式文件系統(如Hive),關系型數據庫(如MySQL),消息隊列(如Kafka)等。
- 特征生產:該部分負責從各種數據源讀取數據,提供計算框架用于生產特征。生產框架需要根據數據源的類型、不同的計算需求綜合設計,因此會有多套生產框架。
- 特征導入:該部分負責將計算好的特征寫入到線上存儲供特征服務讀取。該部分主要關注導入作業之間的依賴、并發寫入的速度與一致性等問題。
- 特征服務:該部分為整個特征系統的核心功能部分,提供在線特征的存取服務,直接服務于上層策略系統。
特征的生命周期按照上述過程,可以抽象為五個步驟:讀、算、寫、存、取。整個流程于特征系統框架內成為一個整體,作為特征工程的一體化解決方案。本文主要圍繞特征服務的核心功能“存”、“取”,介紹一些通用的實踐經驗。特征系統的延伸部分,如特征生產、系統框架等主題會在后續文章中做詳細介紹。
1.2 特征系統的核心——存與取
簡單來說,可以認為特征系統的核心功能是一個大號的HashMap,用于存儲和快速提取每次請求中相關維度的特征集合。然而實際情況并不像HashMap那樣簡單,以我們的通用在線特征系統(Datahub)的系統指標為例,它的核心功能主要需面對存儲與讀取方面的挑戰:
- 高并發:策略系統面向用戶端,服務端峰值QPS超過1萬,數據庫峰值QPS超過100萬(批量請求造成)。
- 高吞吐:每次請求可能包含上千維特征,網絡IO高。服務端網絡出口流量均值500Mbps,峰值為1.5Gbps。
- 大數據:雖然線上需要使用的特征數據不會像離線Hive庫那樣龐大,但數據條數也會超過10億,字節量會達到TB級。
- 低延遲:面對用戶的請求,為保持用戶體驗,接口的延遲要盡可能低,服務端TP99指標需要在10ms以下。
以上指標數字僅是以我們系統作為參考,實際各個部門、公司的特征系統規模可能差別很大,但無論一個特征系統的規模怎樣,其系統核心目標必定是考慮:高并發、高吞吐、大數據、低延遲,只不過各有不同的優先級罷了。當系統的優化方向是多目標時,我們不可能獨立的用任何一種方式,在有限資源的情況下做到面面俱到。留給我們的是業務最重要的需求特性,以及對應這些特性的解決方案。
二、在線特征存取技術
本節介紹一些在線特征系統上常用的存取技術點,以豐富我們的武器庫。主要內容也并非詳細的系統設計,而是一些常見問題的通用技術解決方案。但如上節所說,如何根據策略需求,利用合適的技術,制定對應的方案,才是各位架構師的核心價值所在。
2.1 數據分層
特征總數據量達到TB級后,單一的存儲介質已經很難支撐完整的業務需求了。高性能的在線服務內存或緩存在數據量上成了杯水車薪,分布式KV存儲能提供更大的存儲空間但在某些場景又不夠快。開源的分布式KV存儲或緩存方案很多,比如我們用到的就有Redis/Memcache,HBase,Tair等,這些開源方案有大量的貢獻者在為它們的功能、性能做出不斷努力,本文就不更多著墨了。
對構建一個在線特征系統而言,實際上我們需要理解的是我們的特征數據是怎樣的。有的數據非常熱,我們通過內存副本或者是緩存能夠以極小的內存代價覆蓋大量的請求。有的數據不熱,但是一旦訪問要求穩定而快速的響應速度,這時基于全內存的分布式存儲方案就是不錯的選擇。對于數據量級非常大,或者增長非常快的數據,我們需要選擇有磁盤兜底的存儲方案——其中又要根據各類不同的讀寫分布,來選擇存儲技術。
當業務發展到一定層次后,單一的特征類型將很難覆蓋所有的業務需求。所以在存儲方案選型上,需要根據特征類型進行數據分層。分層之后,不同的存儲引擎統一對策略服務提供特征數據,這是保持系統性能和功能兼得的***實踐。
2.2 數據壓縮
海量的離線特征加載到線上系統并在系統間流轉,對內存、網絡帶寬等資源都是不小的開銷。數據壓縮是典型的以時間換空間的例子,往往能夠成倍減少空間占用,對于線上珍貴的內存、帶寬資源來說是莫大的福音。數據壓縮本質思想是減少信息冗余,針對特征系統這個應用場景,我們積累了一些實踐經驗與大家分享。
2.2.1 存儲格式
特征數據簡單來說即特征名與特征值。以用戶畫像為例,一個用戶有年齡、性別、愛好等特征。存儲這樣的特征數據通常來說有下面幾種方式:
- JSON格式,完整保留特征名-特征值對,以JSON字符串的形式表示。
- 元數據抽取,如Hive一樣,特征名(元數據)單獨保存,特征數據以String格式的特征值列表表示。
- 元數據固化,同樣將元數據單獨保存,但是采用強類型定義每個特征,如Integer、Double等而非統一的String類型。
三種格式各有優劣:
- JSON格式的優點在特征數量可以是變長的。以用戶畫像為例,A用戶可能有年齡、性別標簽。B用戶可以有籍貫、愛好標簽。不同用戶標簽種類可以差別很大,都能便捷的存儲。但缺點是每組特征都要存儲特征名,當特征種類同構性很高時,會包含大量冗余信息。
- 元數據抽取的特點與JSON格式相反,它只保留特征值本身,特征名作為元數據單獨存放,這樣減少了冗余特征名的存儲,但缺點是數據格式必須是同構的,而且如果需要增刪特征,需要更改元數據后刷新整個數據集。
- 元數據固化的優點與元數據抽取相同,而且更加節省空間。然而其存取過程需要實現專有序列化,實現難度和讀寫速度都有成本。
特征系統中,一批特征數據通常來說是完全同構的,同時為了應對高并發下的批量請求,我們在實踐中采用了元數據抽取作為存儲方案,相比JSON格式,有2~10倍的空間節約(具體比例取決于特征名的長度、特征個數以及特征值的類型)。
2.2.2 字節壓縮
提到數據壓縮,很容易就會想到利用無損字節壓縮算法。無損壓縮的主要思路是將頻繁出現的模式(Pattern)用較短的字節碼表示。考慮到在線特征系統的讀寫模式是一次全量寫入,多次逐條讀取,因此壓縮需要針對單條數據,而非全局壓縮。目前主流的Java實現的短文本壓縮算法有Gzip、Snappy、Deflate、LZ4等,我們做了兩組實驗,主要從單條平均壓縮速度、單條平均解壓速度、壓縮率三個指標來對比以上各個算法。
數據集:我們選取了2份線上真實的特征數據集,分別取10萬條特征記錄。記錄為純文本格式,平均長度為300~400字符(600~800字節)。
壓縮算法:Deflate算法有1~9個壓縮級別,級別越高,壓縮比越大,操作所需要的時間也越長。而LZ4算法有兩個壓縮級別,我們用0,1表示。除此之外,LZ4有不同的實現版本:JNI、Java Unsafe、Java Safe,詳細區別參考 https://github.com/lz4/lz4-java ,這里不做過多解釋。
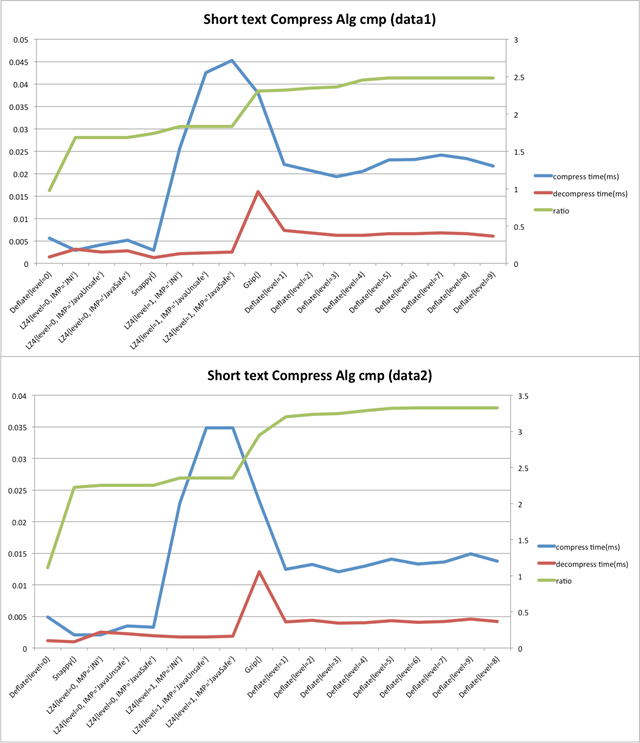
實驗結果圖中的毫秒時間為單條記錄的壓縮或解壓縮時間。壓縮比的計算方式為壓縮前字節碼長度/壓縮后字節碼長度。可以看出,所有壓縮算法的壓縮/解壓時間都會隨著壓縮比的上升而整體呈上升趨勢。其中LZ4的Java Unsafe、Java Safe版由于考慮平臺兼容性問題,出現了明顯的速度異常。
從使用場景(一次全量寫入,多次逐條讀取)出發,特征系統主要的服務指標是特征高并發下的響應時間與特征數據存儲效率。因此特征壓縮關注的指標其實是:快速的解壓速度與較高的壓縮比,而對壓縮速度其實要求不高。因此綜合上述實驗中各個算法的表現,Snappy是較為合適我們的需求。
2.2.3 字典壓縮
壓縮的本質是利用共性,在不影響信息量的情況下進行重新編碼,以縮減空間占用。上節中的字節壓縮是單行壓縮,因此只能運用到同一條記錄中的共性,而無法顧及全局共性。舉個例子:假設某個用戶維度特征所有用戶的特征值是完全一樣的,字節壓縮逐條壓縮不能節省任何的存儲空間,而我們卻知道實際上只有一個重復的值在反復出現。即便是單條記錄內部,由于壓縮算法窗口大小的限制,長Pattern也很難被顧及到。因此,對全局的特征值做一次字典統計,自動或人工的將頻繁Pattern加入到字典并重新編碼,能夠解決短文本字節壓縮的局限性。
2.3 數據同步
當每次請求,策略計算需要大量的特征數據時(比如一次請求上千條的廣告商特征),我們需要非常強悍的在線數據獲取能力。而在存儲特征的不同方法中,訪問本地內存毫無疑問是性能***的解決方式。想要在本地內存中訪問到特征數據,通常我們有兩種有效手段:內存副本和客戶端緩存。
2.3.1 內存副本技術
當數據總量不大時,策略使用方可以在本地完全鏡像一份特征數據,這份鏡像叫內存副本。使用內存副本和使用本地的數據完全一致,使用者無需關心遠端數據源的存在。內存副本需要和數據源通過某些協議進行同步更新,這類同步技術稱為內存副本技術。在線特征系統的場景中,數據源可以抽象為一個KV類型的數據集,內存副本技術需要把這樣一個數據集完整的同步到內存副本中。
推拉結合——時效性和一致性
一般來說,數據同步為兩種類型:推(Push)和拉(Pull)。Push的技術比較簡單,依賴目前常見的消息隊列中間件,可以根據需求做到將一個數據變化傳送到一個內存副本中。但是,即使實現了不重不漏的高可靠性消息隊列通知(通常代價很大),也還面臨著初始化啟動時批量數據同步的問題——所以,Push只能作為一種提高內存副本時效性的手段,本質上內存副本同步還得依賴Pull協議。Pull類的同步協議有一個非常好的特性就是冪等,一次失敗或成功的同步不會影響下一次進行新的同步。
Pull協議有非常多的選擇,最簡單的每次將所有數據全量拉走就是一種基礎協議。但是在業務需求中需要追求數據同步效率,所以用一些比較高效的Pull協議就很重要。為了縮減拉取數據量,這些協議本質上來說都是希望高效的計算出盡量精確的數據差異(Diff),然后同步這些必要的數據變動。這里介紹兩種我們曾經在工程實踐中應用過的Pull型數據同步協議。
基于版本號同步——回放日志(RedoLog)和退化算法
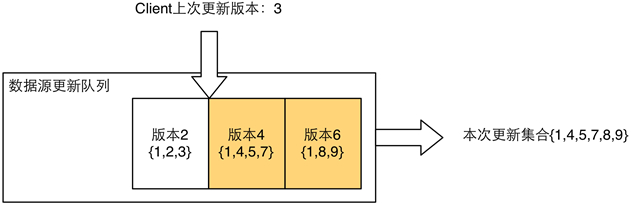
在數據源更新時,對于每一次數據變化,基于版本號的同步算法會為這次變化分配一個唯一的遞增版本號,并使用一個更新隊列記錄所有版本號對應的數據變化。
內存副本發起同步請求時,會攜帶該副本上一次完成同步時的***版本號,這意味著所有該版本號之后的數據變化都需要被拉取過來。數據源方收到請求后,從更新隊列中找到大于該版本號的所有數據變化,并將數據變化匯總,得到最終需要更新的Diff,返回給發起方。此時內存副本只需要更新這些Diff數據即可。
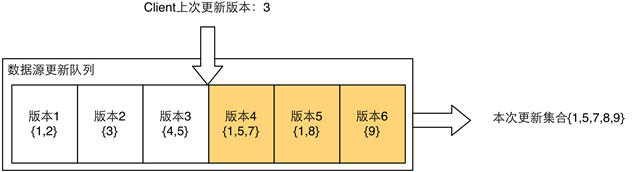
對于大多數的業務場景,特征數據的生成會收口到一個統一的更新服務中,所以遞增版本號可以串行的生成。如果在分布式的數據更新環境中,則需要利用分布式id生成器來獲取遞增版本號。
另一個問題則是更新隊列的長度。如果不進行任何優化,更新隊列理論上是***長的,甚至會超過數據集的大小。一個優化方法是我們限制住更新隊列的***長度,一旦長度超過限制,則執行合并(Merge)操作。Merge操作將隊列中的數據進行兩兩合并,合并后的版本號以較大的版本號為準,合并后的更新數據集是兩個數據集的并。Merge后,新的隊列長度下降為原更新隊列的一半。

Merge之后的更新隊列,我們依然可以使用相同的算法進行同步Diff計算:在隊列中找到大于上一次更新版本號的所有數據集。可以看到由于版本號的合并,算出的Diff不再是完全精準的更新數據,在隊列中最早的更新數據集有可能包含部分已經同步過的數據——但這樣的退化并不影響同步正確性,僅僅會造成少量的同步冗余,冗余的量取決于Diff中最早的數據集經過Merge的次數。
MerkleTree同步——數據集對比算法
基于版本號的同步使用的是類似RedoLog的思想,將業務變動的歷史記錄下來,并通過回放未同步的歷史記錄得到Diff。由于記錄不斷增長的RedoLog需要不小的開銷,所以采用了Merge策略來退化原始日志(Log)。對于批量或者微批量的更新來說,基于版本號的同步算法能較好的工作;相反,若數據是實時更新的,將會出現大量的RedoLog,并快速的退化,影響同步的效率。
Merkle Tree同步算法走的是另一條路,簡單來說就是通過每次直接比較兩個數據集的差異來獲取Diff。首先看一個最簡單的算法:每次內存副本將所有數據的Hash值發送給數據源,數據源比較整個數據集,對于Hash值不同的數據執行同步操作——這樣就精確計算出了兩個數據集之間的Diff。但顯而易見的問題,是每次傳輸所有數據的Hash值可能并不比多傳幾個數據輕松。Merkle Tree同步算法就是使用Merkle Tree數據結構來優化這一比較過程。
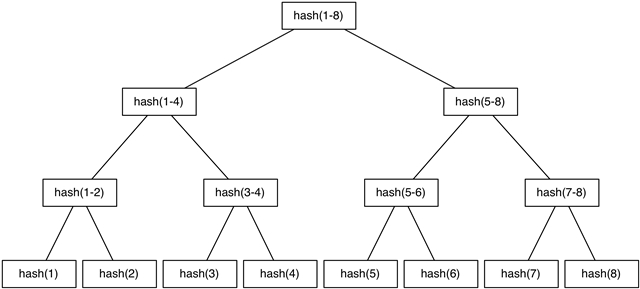
Merkle Tree簡單來說是就是把所有數據集的hash值組織成一棵樹,這棵樹的葉子節點描述一個(或一組)數據的Hash值。而中間節點的值由其所有兒子的Hash值再次Hash得到,描述了以它為根的子樹所包含的數據的整體Hash。顯然,在不考慮Hash沖突的情況下,如果兩顆Merkle Tree根節點相同,代表這是兩個完全相同的數據集。
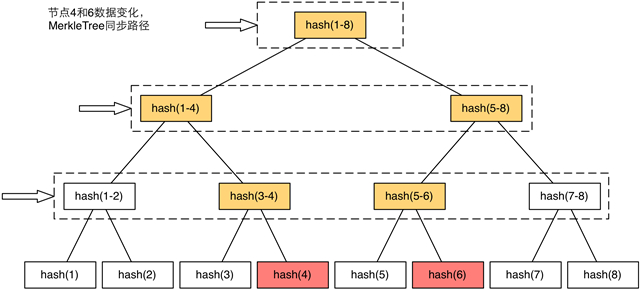
Merkle Tree同步協議由副本發起,將副本根節點值發送給數據源,若與數據源根節點hash值一致,則沒有數據變動,同步完成。否則數據源將把根結點的所有兒子節點的hash發送給副本,進行遞歸比較。對于不同的hash值,一直持續獲取直到葉子節點,就可以完全確定已經改變的數據。以二叉樹為例,所有的數據同步最多經過LogN次交互完成。
2.3.2 客戶端緩存技術
當數據規模大,無法完全放入到內存中,冷熱數據分明,對于數據時效性要求又不高的時候,通常各類業務都會采用客戶端緩存。客戶端緩存的集中實現,是特征服務延伸的一部分。通用的緩存協議和使用方式不多說,從在線特征系統的業務角度出發,這里給出幾個方向的思考和經驗。
接口通用化——緩存邏輯與業務分離
一個特征系統要滿足各類業務需求,它的接口肯定是豐富的。從數據含義角度分有用戶類、商戶類、產品類等等,從數據傳輸協議分有Thrift、HTTP,從調用方式角度分有同步、異步,從數據組織形式角度分有單值、List、Map以及相互嵌套等等……一個良好的架構設計應該盡可能將數據處理與業務剝離開,抽象各個接口的通用部分,一次緩存實現,多處接口同時受益復用。下面以同步異步接口為例介紹客戶端接口通用化。
同步接口只有一步:
- 向服務端發起請求得到結果。
異步接口分為兩步:
- 向服務端發起請求得到Future實例。
- 向Future實例發起請求,得到數據。
同步和異步接口的數據處理只有順序的差別,只需要梳理好各個步驟的執行順序即可。引入緩存后,數據處理流程對比如下:
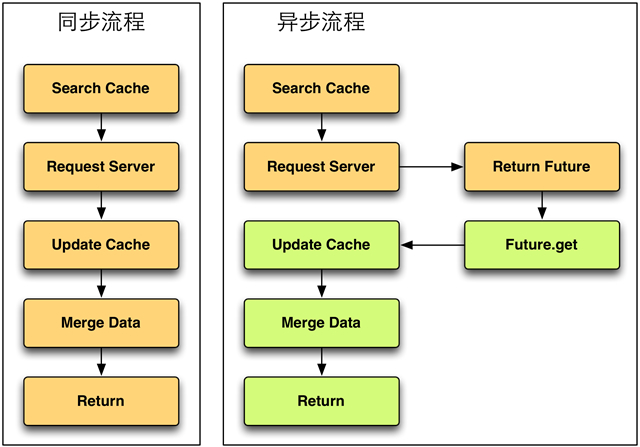
不同顏色的處理框表示不同的請求。異步流程需要使用方的兩次請求才能獲取到數據。像圖中“用服務端數據更新緩存”(update cache)、“服務端數據與緩存數據匯總”(merge data)步驟在異步流程里是在第二次請求中完成的,區別于同步流程***次請求就完成所有步驟。將數據流程拆分為這些子步驟,同步與異步只是這些步驟的不同順序的組合。因此讀寫緩存(search cache、update cache)這兩個步驟可以抽象出來,與其余邏輯解耦。
數據存儲——時間先于空間,客戶端與服務端分離
客戶端之于服務端,猶如服務端之于數據庫,其實數據存儲壓縮的思路是完全一樣的。具體的數據壓縮與存儲策略在上文數據壓縮章節已經做了詳細介紹,這里主要想說明兩點問題:
客戶端壓縮與服務端壓縮由于應用場景的不同,其目標是有差異的。服務端壓縮使用場景是一次性高吞吐寫入,逐條高并發低延遲讀取,它主要關注的是讀取時的解壓時間和數據存儲時的壓縮比。而客戶端緩存屬于數據存儲分層中最頂端的部分,由于讀寫的場景都是高并發低延遲的本地內存操作,因此對壓縮速度、解壓速度、數據量大小都有很高要求,它要做的權衡更多。
其次,客戶端與服務端是兩個完全獨立的模塊,說白了,雖然我們會編寫客戶端代碼,但它不屬于服務的一部分,而是調用方服務的一部分。客戶端的數據壓縮應該盡量與服務端解耦,切不可為了貪圖實現方便,將兩者的數據格式耦合在一起,與服務端的數據通信格式應該理解為一種獨立的協議,正如服務端與數據庫的通信一樣,數據通信格式與數據庫的存儲格式沒有任何關系。
內存管理——緩存與分代回收的矛盾
緩存的目標是讓熱數據(頻繁被訪問的數據)能夠留在內存,以便提高緩存***率。而JVM垃圾回收(GC)的目標是釋放失去引用的對象的內存空間。兩者目標看上去相似,但細微的差異讓兩者在高并發的情景下很難共存。緩存的淘汰會產生大量的內存垃圾,使Full GC變得非常頻繁。這種矛盾其實不限于客戶端,而是所有JVM堆內緩存共同面臨的問題。下面我們仔細分析一個場景:
隨著請求產生的數據會不斷加入緩存,QPS較高的情形下,Young GC頻繁發生,會不斷促使緩存所占用的內存從新生代移向老年代。緩存被填滿后開始采用Least Recently Used(LRU)算法淘汰,冷數據被踢出緩存,成為垃圾內存。然而不幸的是,由于頻繁的Young GC,有很多冷數據進入了老年代,淘汰老年代的緩存,就會產生老年代的垃圾,從而引發Full GC。
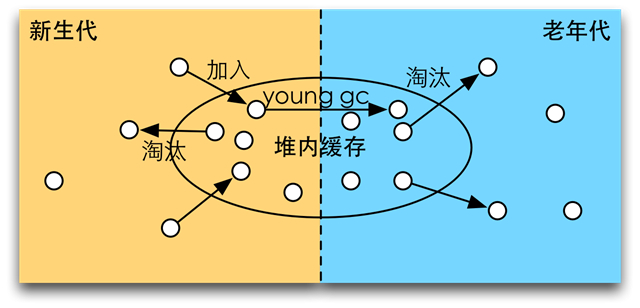
可以看到,正是由于緩存的淘汰機制與新生代的GC策略目標不一致,導致了緩存淘汰會產生很多老年代的內存垃圾,而且產生垃圾的速度與緩存大小沒有太多關系,而與新生代的GC頻率以及堆緩存的淘汰速度相關。而這兩個指標均與QPS正相關。因此堆內緩存仿佛成了一個通向老年代的垃圾管道,QPS越高,垃圾產生越快!
因此,對于高并發的緩存應用,應該避免采用JVM的分帶管理內存,或者可以說,GC內存回收機制的開銷和效率并不能滿足高并發情形下的內存管理的需求。由于JVM虛擬機的強制管理內存的限制,此時我們可以將對象序列化存儲到堆外(Off Heap),來達到繞開JVM管理內存的目的,例如Ehcache,BigMemory等第三方技術便是如此。或者改動JVM底層實現(類似之前淘寶的做法),做到堆內存儲,免于GC。
三、結束語
本文主要介紹了一些在線特征系統的技術點,從系統的高并發、高吞吐、大數據、低延遲的需求出發,并以一些實際特征系統為原型,提出在線特征系統的一些設計思路。正如上文所說,特征系統的邊界并不限于數據的存儲與讀取。像數據導入作業調度、實時特征、特征計算與生產、數據備份、容災恢復等等,都可看作為特征系統的一部分。本文是在線特征系統系列文章的***篇,我們的特征系統也在需求與挑戰中不斷演進,后續會有更多實踐的經驗與大家分享。一家之言,難免有遺漏和偏頗之處,但是他山之石可以攻玉,若能為各位架構師在面向自己業務時提供一些思路,善莫大焉。