Hadoop 2.0.3在Linux環境下單機部署
1.Hadoop2.0簡述[1]
HDFS:為了保證name服務器的規模水平,開發人員使用了多個獨立的Namenodes和Namespaces。這些Namenode是聯合起來的,它們之間不需要相互協調。Datanode可以為所有Namenode存放數據塊,每個數據塊要在平臺上所有的Namenode上進行注冊。Datenode定期向Namenode發送心跳信號和數據報告,接受和處理Namenodes的命令。
YARN(新一代MapReduce):在hadoop-0.23中介紹的新架構,將JobTracker的兩個主要的功能:資源管理和作業生命周期管理分成不同的部分。新的資源管理器負責管理面向應用的計算資源分配和每個應用的之間的調度及協調。
每個新的應用既是一個傳統意義上的MapReduce作業,也是這些作業的 DAG(Database Availability Group數據可用性組),資源管理者(ResourcesManager)和管理每臺機器的數據管理者(NodeManager)構成了整個平臺的計算布局。
每一個應用的應用管理者實際上是一個架構的數據庫,向資源管理者(ResourcesManager)申請資源,數據管理者(NodeManager)進行執行和監測任務。
2. Hadoop2.0的目錄結構[2]
Hadoop2.0的目錄結構很像Linux操作系統的目錄結構,各個目錄的作用如下:
(1) 在新版本的hadoop中,由于使用hadoop的用戶被分成了不同的用戶組,就像Linux一樣。因此執行文件和腳本被分成了兩部分,分別存放在bin和sbin目錄下。存放在sbin目錄下的是只有超級用戶(superuser)才有權限執行的腳本,比如start-dfs.sh, start-yarn.sh, stop-dfs.sh, stop-yarn.sh等,這些是對整個集群的操作,只有superuser才有權限。而存放在bin目錄下的腳本所有的用戶都有執行的權限,這里的腳本一般都是對集群中具體的文件或者block pool操作的命令,如上傳文件,查看集群的使用情況等。
(2) etc目錄下存放的就是在0.23.0版本以前conf目錄下存放的東西,就是對common, hdfs, mapreduce(yarn)的配置信息。
(3) include和lib目錄下,存放的是使用Hadoop的C語言接口開發用到的頭文件和鏈接的庫。
(4) libexec目錄下存放的是hadoop的配置腳本,具體怎么用到的這些腳本,我也還沒跟蹤到。目前我就是在其中hadoop-config.sh文件中增加了JAVA_HOME環境變量。
(5) logs目錄在download到的安裝包里是沒有的,如果你安裝并運行了hadoop,就會生成logs 這個目錄和里面的日志。
(6) share這個文件夾存放的是doc文檔和最重要的Hadoop源代碼編譯生成的jar包文件,就是運行hadoop所用到的所有的jar包。
3.學習hadoop的配置文件[3]
(1) dfs.hosts記錄即將作為datanode加入集群的機器列表
(2) mapred.hosts 記錄即將作為tasktracker加入集群的機器列表
(3) dfs.hosts.exclude mapred.hosts.exclude 分別包含待移除的機器列表
(4) master 記錄運行輔助namenode的機器列表
(5) slave 記錄運行datanode和tasktracker的機器列表
(6) hadoop-env.sh 記錄腳本要用的環境變量,以運行hadoop
(7) core-site.xml hadoop core的配置項,例如hdfs和mapreduce常用的i/o設置等。
(8) hdfs-site.xml hadoop守護進程的配置項,包括namenode、輔助namenode和datanode等。
(9) mapred-site.xml mapreduce守護進程的配置項,包括jobtracker和tasktracker。
(10) hadoop-metrics.properties 控制metrics在hadoop上如何發布的屬性。
(11) log4j.properties 系統日志文件、namenode審計日志、tasktracker子進程的任務日志的屬性。
4. hadoop詳細配置[4,5]
從Hadoop官網上下載hadoop-2.0.0-alpha.tar.gz,放到共享文件夾中,在/usr/lib中進行解壓,運行tar -zxvf /mnt/hgfs/share/hadoop-2.0.0-alpha.tar.gz。
(1)在gedit ~/.bashrc中編輯:
- export HADOOP_PREFIX="/usr/lib/hadoop-2.0.0-alpha"
- export PATH=$PATH:$HADOOP_PREFIX/bin
- export PATH=$PATH:$HADOOP_PREFIX/sbin
- export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
- export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
- export YARN_HOME=${HADOOP_PREFIX}
仍然保存退出,再source ~/.bashrc,使之生效。
(2)在etc/hadoop目錄中編輯 core-site.xml
- <configuration>
- <property>
- <name>io.native.lib.available</name>
- <value>true</value>
- </property>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://10.1.50.170:9000</value>
- <description>The name of the default file system.Either the literal string "local" or a host:port for NDFS.</description>
- <final>true</final>
- </property>
- </configuration>
(3) 在etc/hadoop目錄中編輯hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/name</value>
- <description>Determines where on the local filesystem the DFS name node should store the
- name table.If this is a comma-delimited list of directories,then name table is
- replicated in all of the directories,for redundancy.</description>
- <final>true</final>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/data</value>
- <description>Determines where on the local filesystem
- an DFS data node should store its blocks.If this is a comma-delimited
- list of directories,then data will be stored in all named directories,
- typically on different devices.Directories that do not exist are ignored.</description>
- <final>true</final>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.permission</name>
- <value>false</value>
- </property>
- </configuration>
路徑
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/name與
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/data
是計算機中的一些文件夾,用于存放數據和編輯文件的路徑必須用一個詳細的URI描述。
(4)在 /etc/hadoop 使用以下內容創建一個文件mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.job.tracker</name>
- <value>hdfs://10.1.50.170:9001</value>
- <final>true</final>
- </property>
- <property>
- <name>mapreduce.map.memory.mb</name>
- <value>1536</value>
- </property>
- <property>
- <name>mapreduce.map.java.opts</name>
- <value>-Xmx1024M</value>
- </property>
- <property>
- <name>mapreduce.reduce.memory.mb</name>
- <value>3072</value>
- </property>
- <property>
- <name>mapreduce.reduce.java.opts</name>
- <value>-Xmx2560M</value>
- </property>
- <property>
- <name>mapreduce.task.io.sort.mb</name>
- <value>512</value>
- </property>
- <property>
- <name>mapreduce.task.io.sort.factor</name>
- <value>100</value>
- </property>
- <property>
- <name>mapreduce.reduce.shuffle.parallelcopies</name>
- <value>50</value>
- </property>
- <property>
- <name>mapred.system.dir</name>
- <value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/system</value>
- <final>true</final>
- </property>
- <property>
- <name>mapred.local.dir</name>
- <value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/local</value>
- <final>true</final>
- </property>
- </configuration>
路徑:
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/system與
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/local
為計算機中用于存放數據的文件夾路徑必須用一個詳細的URI描述。
(5)編輯yarn-site.xml
- <configuration>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>10.1.50.170:8080</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>10.1.50.170:8081</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>10.1.50.170:8082</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce.shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- </configuration>
(6) 在 /etc/hadoop 目錄中創建hadoop-env.sh 并添加:
export HADOOP_FREFIX=/usr/lib/hadoop-2.0.0-alpha
export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
export PATH=$PATH:$HADOOP_FREFIX/bin
export PATH=$PATH:$HADOOP_FREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
export YARN_HOME=${HADOOP_FREFIX}
export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-sun
另,需要yarn-env.sh中充填相同的內容,再配置到各節點。
配置過程中遇到的問題:
▼在瀏覽器中localhost:8088中,只能看到主節點的信息,看不到datanode的信息。
解決方法:在重新配置yarn.xml(以上為修改后內容)后已經可以看到兩個節點,但啟動后有一個datanode會自動關閉。
▼在糾結了很長時間kerbose的問題后,才找到運行不能的原因是這個提示:
INFO mapreduce.Job: Job job_1340251923324_0001 failed with state FAILED due to: Application application_1340251923324_0001 failed 1 times due to AM Container for appattempt_1340251923324_0001_000001 exited with exitCode: 1 due to:Failing this attempt.. Failing the application.
按照一個國外友人的回貼[6]fs.deault.name -> hdfs://localhost:9100 in core-site.xml ,mapred.job.tracker - > http://localhost:9101 in mapred-site.xml,錯誤提示發生改變。再把hadoop-env.sh中的內容copy到yarn-env.sh中,平臺就可以勉強運行了(還是有報警)
5.初始化hadoop
首先格式化 namenode,輸入命令 hdfs namenode –format;
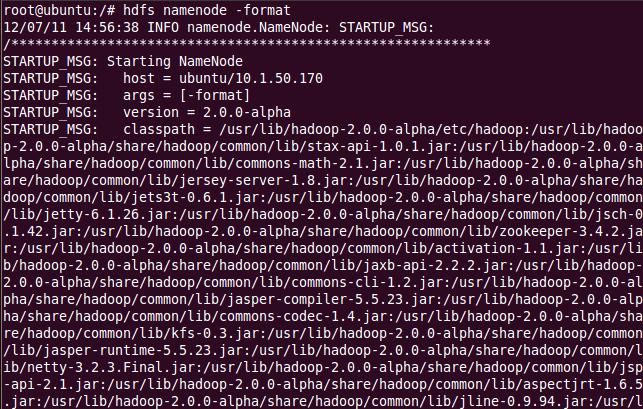
然后開始守護進程 hadoop-daemon.sh start namenode 和 hadoop-daemon.sh start datanode或(可以同時啟動:start-dfs.sh);然后,開始 Yarn 守護進程運行 yarn-daemon.sh start resourcemanager和 yarn-daemon.sh start nodemanager(或同時啟動: start-yarn.sh)。
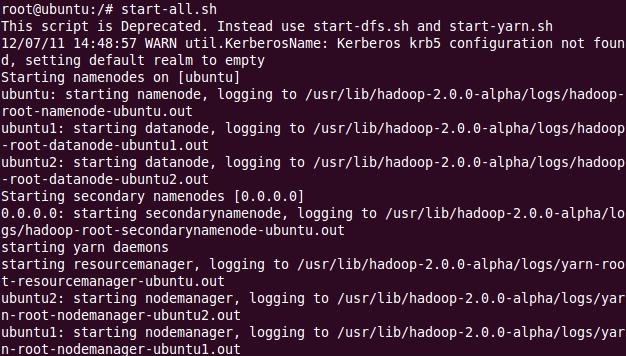
最后,檢查守護進程是否啟動運行 jps,是否輸出以下結果:

在datanode上jps,有以下輸出:


瀏覽UI,打開 localhost:8088 可以查看資源管理頁面。
結束守護進程stop-dfs.sh和stop-yarn.sh(或者同時關閉stop-all.sh)。
原文鏈接:http://wenluoxicheng.blog.163.com/blog/static/192519939201325114018477/