













Ubuntu 12.04搭建hadoop單機版環境
在11月初的時候,我們了解了Ubuntu 12.04 搭建 hadoop 集群版環境的方法,今天再來看看在單機版環境中,Ubuntu12.04搭建hadoop是如何實現的。
一. 你要安裝Ubuntu這一步省略;
二. 在Ubuntu下創建hadoop用戶組和用戶;
1. 創建hadoop用戶組:
| sudo addgroup hadoop |
如圖:
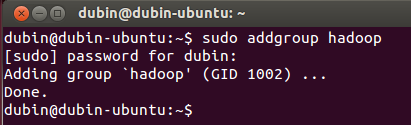
2. 創建hadoop用戶:
| sudo adduser -ingroup hadoop hadoop |
如圖:
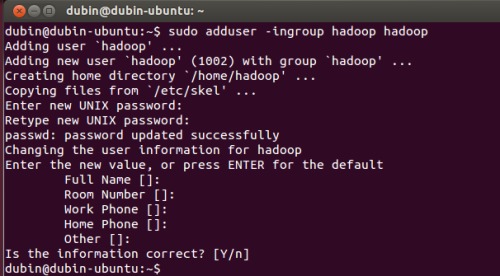
3. 給hadoop用戶添加權限,打開/etc/sudoers文件:
| sudo gedit /etc/sudoers |
按回車鍵后就會打開/etc/sudoers文件了,給hadoop用戶賦予root用戶同樣的權限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
| hadoop ALL=(ALL:ALL) ALL |
如圖:
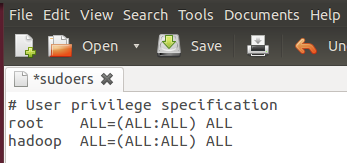
三. 在Ubuntu下安裝JDK
使用如下命令執行即可:
| sudo apt-get install openjdk-6-jre |
如圖:
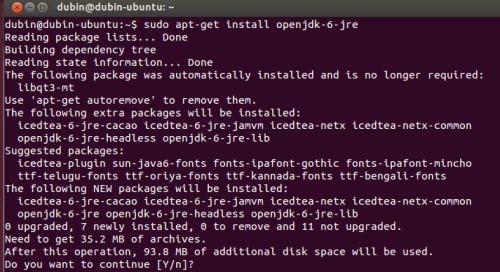
四. 修改機器名
每當ubuntu安裝成功時,我們的機器名都默認為:ubuntu ,但為了以后集群中能夠容易分辨各臺服務器,需要給每臺機器取個不同的名字。機器名由 /etc/hostname文件決定。
1. 打開/etc/hostname文件:
| sudo gedit /etc/hostname |
2. 將/etc/hostname文件中的ubuntu改為你想取的機器名。這里我取"dubin-ubuntu"。 重啟系統后才會生效。
五. 安裝ssh服務
這里的ssh和三大框架:spring,struts,hibernate沒有什么關系,ssh可以實現遠程登錄和管理,具體可以參考其他相關資料。
安裝openssh-server,
| sudo apt-get install ssh openssh-server |
這時假設您已經安裝好了ssh,您就可以進行第六步了哦~
六、 建立ssh無密碼登錄本機
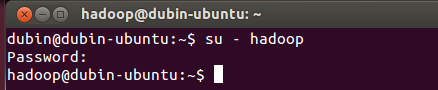
首先要轉換成hadoop用戶,執行以下命令:
| su - hadoop |
如圖:
ssh生成密鑰有rsa和dsa兩種生成方式,默認情況下采用rsa方式。
1. 創建ssh-key,,這里我們采用rsa方式:
| ssh-keygen -t rsa -P "" |
如圖:
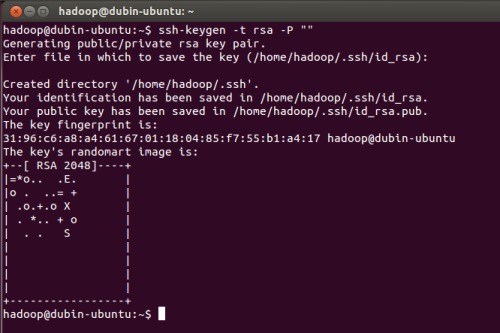
(注:回車后會在~/.ssh/下生成兩個文件:id_rsa和id_rsa.pub這兩個文件是成對出現的)
2. 進入~/.ssh/目錄下,將id_rsa.pub追加到authorized_keys授權文件中,開始是沒有authorized_keys文件的:
| cd ~/.ssh cat id_rsa.pub >> authorized_keys |
如圖:
![]()
(完成后就可以無密碼登錄本機了。)
3. 登錄localhost:
| ssh localhost |
如圖:
( 注:當ssh遠程登錄到其它機器后,現在你控制的是遠程的機器,需要執行退出命令才能重新控制本地主機。)
4. 執行退出命令:
| exit |
七. 安裝hadoop
我們采用的hadoop版本是:hadoop-0.20.203(http://www.apache.org/dyn/closer.cgi/hadoop/common/ ),因為該版本比較穩定。
1. 假設hadoop-0.20.203.tar.gz在桌面,將它復制到安裝目錄 /usr/local/下:
| sudo cp hadoop-0.20.203.0rc1.tar.gz /usr/local/ |
2. 解壓hadoop-0.20.203.tar.gz:
| cd /usr/local sudo tar -zxf hadoop-0.20.203.0rc1.tar.gz |
3. 將解壓出的文件夾改名為hadoop:
| sudo mv hadoop-0.20.203.0 hadoop |
4. 將該hadoop文件夾的屬主用戶設為hadoop:
| sudo chown -R hadoop:hadoop hadoop |
5. 打開hadoop/conf/hadoop-env.sh文件:
| sudo gedit hadoop/conf/hadoop-env.sh |
6. 配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本機jdk的路徑):
| export JAVA_HOME=/usr/lib/jvm/java-6-openjdk |
7. 打開conf/core-site.xml文件:
| sudo gedit hadoop/conf/core-site.xml |
編輯如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
8. 打開conf/mapred-site.xml文件:
| sudo gedit hadoop/conf/mapred-site.xml |
編輯如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
9. 打開conf/hdfs-site.xml文件:
| sudo gedit hadoop/conf/hdfs-site.xml |
編輯如下:
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- </configuration>
10. 打開conf/masters文件,添加作為secondarynamenode的主機名,作為單機版環境,這里只需填寫 localhost 就Ok了。
| sudo gedit hadoop/conf/masters |
11. 打開conf/slaves文件,添加作為slave的主機名,一行一個。作為單機版,這里也只需填寫 localhost就Ok了。
| sudo gedit hadoop/conf/slaves |
八. 在單機上運行hadoop
1. 進入hadoop目錄下,格式化hdfs文件系統,初次運行hadoop時一定要有該操作,
| cd /usr/local/hadoop/ bin/hadoop namenode -format |
2. 當你看到下圖時,就說明你的hdfs文件系統格式化成功了。
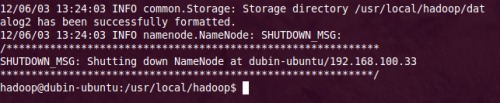
3. 啟動bin/start-all.sh:
| bin/start-all.sh |
4. 檢測hadoop是否啟動成功:
| jps |
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五個進程,就說明你的hadoop單機版環境配置好了!
如下圖:
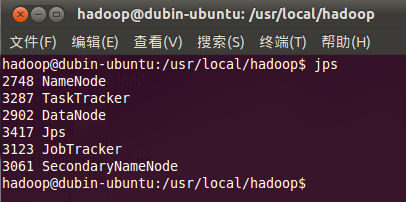
至此,一個hadoop的單機版環境就搭建好了,如果有什么問題,請給我提出來,咱們可以相互交流。
后續我將會整理hadoop集群的搭建,和測試的教程。敬請關注!













