













剖析Disruptor:為什么會這么快?(三)偽共享
緩存系統中是以緩存行(cache line)為單位存儲的。緩存行是2的整數冪個連續字節,一般為32-256個字節。最常見的緩存行大小是64個字節。當多線程修改互相獨立的變量時,如 果這些變量共享同一個緩存行,就會無意中影響彼此的性能,這就是偽共享。緩存行上的寫競爭是運行在SMP系統中并行線程實現可伸縮性最重要的限制因素。有 人將偽共享描述成無聲的性能殺手,因為從代碼中很難看清楚是否會出現偽共享。
為了讓可伸縮性與線程數呈線性關系,就必須確保不會有兩個線程往同一個變量或緩存行中寫。兩個線程寫同一個變量可以在代碼中發現。為了確定互相獨立的變量 是否共享了同一個緩存行,就需要了解內存布局,或找個工具告訴我們。Intel VTune就是這樣一個分析工具。本文中我將解釋Java對象的內存布局以及我們該如何填充緩存行以避免偽共享。

圖1說明了偽共享的問題。在核心1上運行的線程想更新變量X,同時核心2上的線程想要更新變量Y。不幸的是,這兩個變量在同一個緩存行中。每個線程都要去 競爭緩存行的所有權來更新變量。如果核心1獲得了所有權,緩存子系統將會使核心2中對應的緩存行失效。當核心2獲得了所有權然后執行更新操作,核心1就要 使自己對應的緩存行失效。這會來來回回的經過L3緩存,大大影響了性能。如果互相競爭的核心位于不同的插槽,就要額外橫跨插槽連接,問題可能更加嚴重。
Java內存布局(Java Memory Layout)
對于HotSpot JVM,所有對象都有兩個字長的對象頭。第一個字是由24位哈希碼和8位標志位(如鎖的狀態或作為鎖對象)組成的Mark Word。第二個字是對象所屬類的引用。如果是數組對象還需要一個額外的字來存儲數組的長度。每個對象的起始地址都對齊于8字節以提高性能。因此當封裝對 象的時候為了高效率,對象字段聲明的順序會被重排序成下列基于字節大小的順序:
- doubles (8) 和 longs (8)
- ints (4) 和 floats (4)
- shorts (2) 和 chars (2)
- booleans (1) 和 bytes (1)
- references (4/8)
- <子類字段重復上述順序>
了解這些之后就可以在任意字段間用7個long來填充緩存行。在Disruptor里我們對RingBuffer的cursor和BatchEventProcessor的序列進行了緩存行填充。
為了展示其性能影響,我們啟動幾個線程,每個都更新它自己獨立的計數器。計數器是volatile long類型的,所以其它線程能看到它們的進展。
- public final class FalseSharing
- implements Runnable
- {
- public final static int NUM_THREADS = 4; // change
- public final static long ITERATIONS = 500L * 1000L * 1000L;
- private final int arrayIndex;
- private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
- static
- {
- for (int i = 0; i < longs.length; i++)
- {
- longs[i] = new VolatileLong();
- }
- }
- public FalseSharing(final int arrayIndex)
- {
- this.arrayIndex = arrayIndex;
- }
- public static void main(final String[] args) throws Exception
- {
- final long start = System.nanoTime();
- runTest();
- System.out.println("duration = " + (System.nanoTime() - start));
- }
- private static void runTest() throws InterruptedException
- {
- Thread[] threads = new Thread[NUM_THREADS];
- for (int i = 0; i < threads.length; i++)
- {
- threads[i] = new Thread(new FalseSharing(i));
- }
- for (Thread t : threads)
- {
- t.start();
- }
- for (Thread t : threads)
- {
- t.join();
- }
- }
- public void run()
- {
- long i = ITERATIONS + 1;
- while (0 != --i)
- {
- longs[arrayIndex].value = i;
- }
- }
- public final static class VolatileLong
- {
- public volatile long value = 0L;
- public long p1, p2, p3, p4, p5, p6; // comment out
- }
- }
結果(Results)
運行上面的代碼,增加線程數以及添加/移除緩存行的填充,下面的圖2描述了我得到的結果。這是在我4核Nehalem上測得的運行時間。
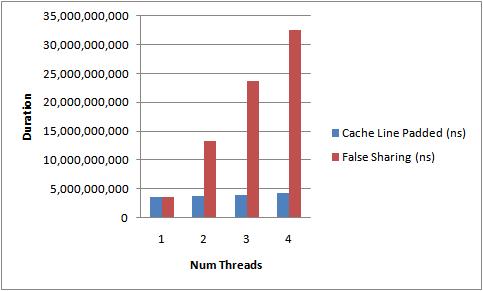
從不斷上升的測試所需時間中能夠明顯看出偽共享的影響。沒有緩存行競爭時,我們幾近達到了隨著線程數的線性擴展。
這并不是個完美的測試,因為我們不能確定這些VolatileLong會布局在內存的什么位置。它們是獨立的對象。但是經驗告訴我們同一時間分配的對象趨向集中于一塊。
所以你也看到了,偽共享可能是無聲的性能殺手。


















