技術實戰:基于 MHA 方式實現 MySQL 的高可用
數據的重要性對于人們來說重要程度不說自明,在信息時代,數據有著比人們更大的力量,我們也知道最近的斯諾登事件,軍事專家對于他掌握的數據給出的評價是,相當于美軍十個重裝甲師。
數據庫的價值可見一斑,數據庫的存在為人們提供了更快的查詢,那么在一個web網站中如何做到數據庫的高可用,保證持續提供服務,下面的實驗是通過MHA的故障轉移來實現。
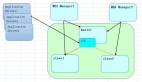
實現原理:MHA是由日本Mysql專家用Perl寫的一套Mysql故障切換方案以保障數據庫的高可用性,它的功能是能在0-30s之內實現主Mysql故障轉移(failover),
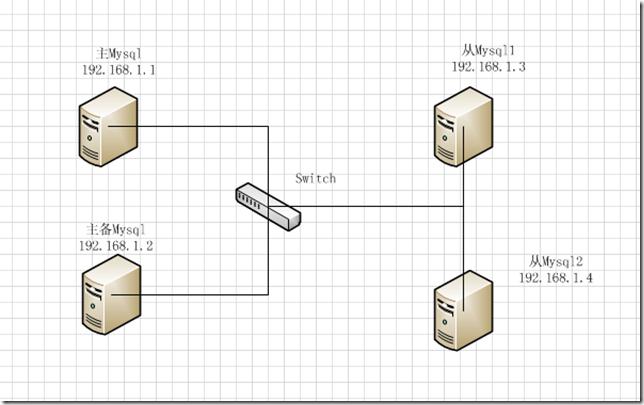
MHA故障轉移可以很好的幫我們解決從庫數據的一致性問題,同時最大化挽回故障發生后的數據。MHA里有兩個角色一個是node節點 一個是manager節點,要實現這個MHA,必須最少要三臺數據庫服務器,一主多備,即一臺充當master,一臺充當master的備份機,另外一臺是從屬機,這里實驗為了實現更好的效果使用四臺機器,需要說明的是一旦主服務器宕機,備份機即開始充當master提供服務,如果主服務器上線也不會再成為master了,因為如果這樣數據庫的一致性就被改變了。
實驗環境:vmware 9.0 RHEL5.5
實驗所需軟件包:http://mysql-master-ha.googlecode.com/files/mha4mysql-node-0.52-0.noarch.rpmhttp://mysql-master-ha.googlecode.com/files/mha4mysql-manager-0.52-0.noarch.rpm
實驗大體步驟:
1 首先要保證虛擬機能夠上網這里我在vmware里添加了第二塊網卡 一塊專門用于四臺機器通信,一塊配置上網 2 關閉selinux和配置IP地址和本地yum源 3 配置epel源 4 配置ssh公鑰免登錄環境 5 修改hostname 6 配置hosts文件 7 配置Mysql的主從同步關系并通過grant命令賦權 8 安裝node包 9 在管理機安裝manager包 10 編輯主配置文件 11 測試及排錯 12 啟動
驗拓撲圖如下:
1 在配置好IP地址后檢查selinux設置
2 在四臺機器都配置epel源 這里我找了一個epel源
rpm –ivh http://dl.fedoraproject.org/pub/epel/5Server/i386/epel-release-5-4.noarch.rpm
#p#
3 建立ssh無密碼登錄環境
主Mysql
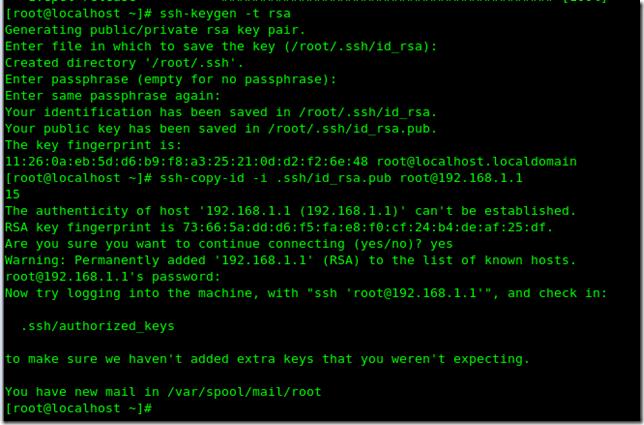
#ssh-keygen -t rsa
#ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.1 ----------------------為什么要在本機也要設置呢,因為manager節點安裝在這上面,如不設置在下面ssh檢查時會通不過。
#ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.2
#ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.3
#ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.4
過程示意圖(因其過程都一樣,故只示范192.168.1.1)
主備Mysql
#ssh-keygen -t rsa #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.1 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.3 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.4
從Mysql1
#ssh-keygen -t rsa #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.1 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.2 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.4
從Mysql2
#ssh-keygen -t rsa #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.1 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.2 #ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.3
測試ssh登錄
我們在主Mysql上測試一下:
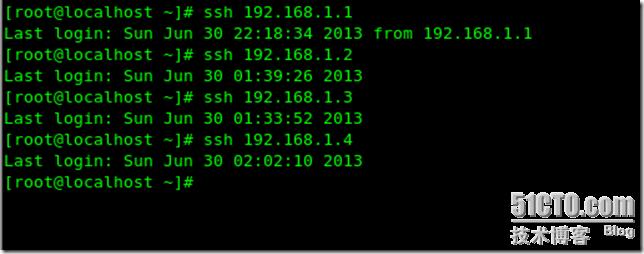
結果測試成功 進入下一步操作
4 接下來步驟就是修改hostname了
為了保險起見 我想要從內存中和文件中修改,不重啟系統(內存中位置 /etc/sysconfig/network)。
192.168.1.1 hostname為mastersql 192.168.1.2 hostname為backupsql 192.168.1.3 hostname為slavesql1 192.168.1.4 hostname為slavesql2
5 配置hosts文件
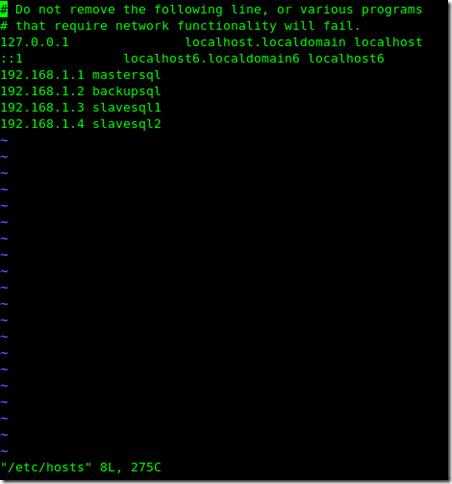
配置好后分別拷貝到其他三臺機器上:

#p#
6 配置mysql主從關系
在四臺系統通過yum安裝mysql
yum –y install mysql-server
在mastersql:
vi /etc/my.cnf
在里面添加2 3 4 行 定義id和二進制目錄:
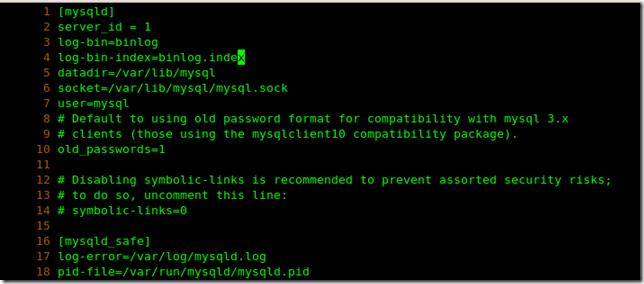
在backupsql vi /etc/my.cnf 在里面添加2 3 4 5 6 7行
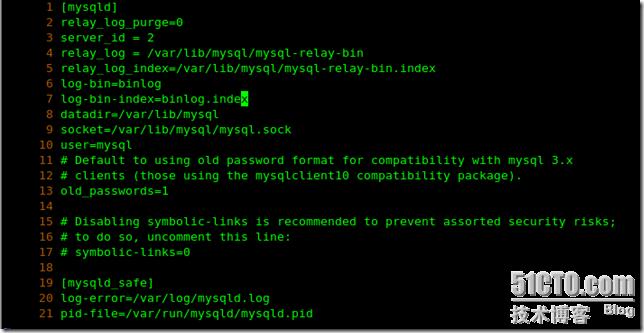
在slavesql1
vi /etc/my.cnf 不同的是第三行中的代碼 其中意思是sql數據庫是只讀的:

在slavesql2
vi /etc/my.cnf
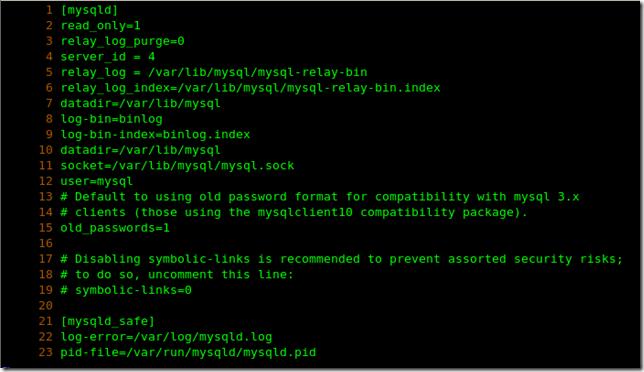
配置好后重啟下mysql服務重新加載配置文件:
service mysqld restart
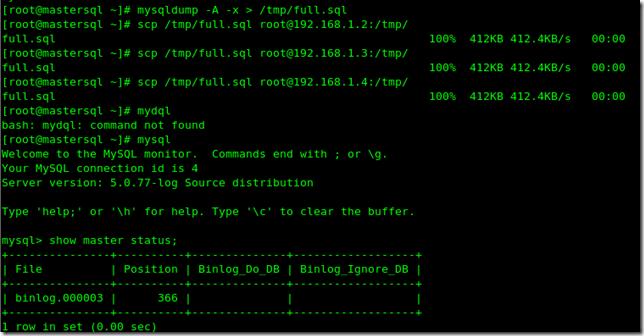
在mastersql中:
mysql> GRANT replication slave ON *.* TO 'kyo'@'%' identified by '123';-------------------賦給用戶有關操作權限 mysql> flush privileges; #mysqldump -A -x > /tmp/full.sql #scp /tmp/full.sql root@192.168.1.2:/tmp/ #scp /tmp/full.sql root@192.168.1.3:/tmp/ #scp /tmp/full.sql root@192.168.1.4:/tmp/ mysql> show master status;------------------記住position號碼(366)
分別在backupsql、slavesql1、slavesql2中做如下操作,這里以backupsql機為例:

只要看到Slave_IO_Running Slave_SQL_Running都為yes就可以了。
然后再就是賦權了,之前的一步賦權操作是權限是只有replication,MHA會在配置文件里要求能遠程登錄到數據庫,所以要進行必要的賦權。
在四臺機器中都做如下操作:
mysql> grant all privileges on *.* to 'root'@'mastersql' identified by '123'; mysql> flush privileges; mysql> grant all privileges on *.* to 'root'@'backupsql' identified by '123'; mysql> flush privileges; mysql> grant all privileges on *.* to 'root'@'slavesql1' identified by '123'; mysql> flush privileges; mysql> grant all privileges on *.* to 'root'@'slavesql2' identified by '123'; mysql> flush privileges;
#p#
7 接下來就是開始正式安裝MHA了,先安裝節點包開始 四臺機器都要安裝!
yum install perl-DBD-MySQL -----------------MHA是perl編寫的軟件需要perl支持 之前yum安裝mysql已經安裝過了 如果沒安裝過需要安裝這個依賴。
rpm -Uvh http://mysql-master-ha.googlecode.com/files/mha4mysql-node-0.52-0.noarch.rpm

8 節點配置完畢就開始配置管理節點了
yum –y install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager -----------安裝依賴包 rpm -Uvh http://mysql-master-ha.googlecode.com/files/mha4mysql-manager-0.52-0.noarch.rpm
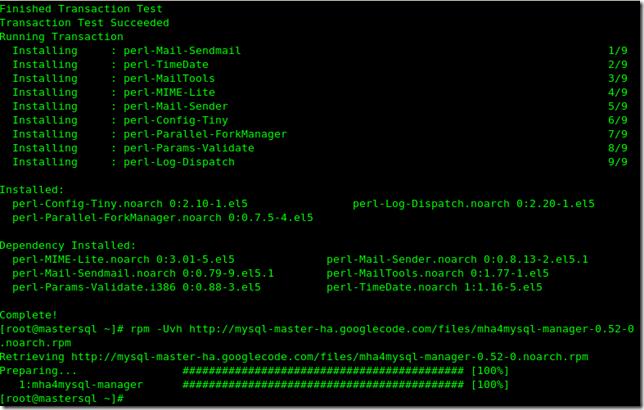
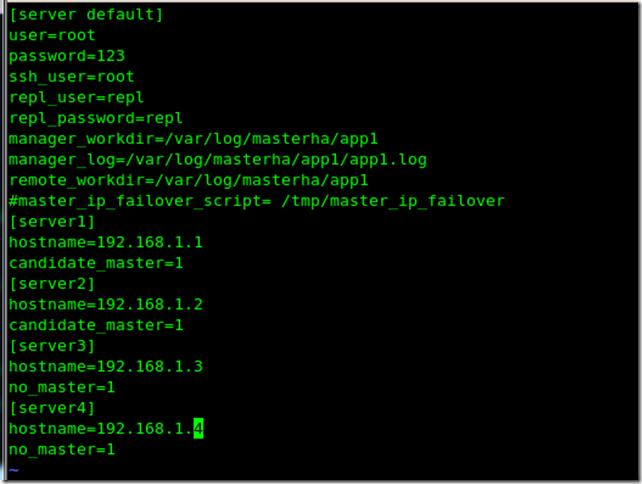
管理節點安裝完畢后就應該去編輯主配文件了
vi /etc/app1.cnf 需要指出的是第二行第三行中之前提到的user和password是mysql中賦權的用戶:
檢查下SSH公鑰免密碼登錄
masterha_check_ssh --conf=/etc/app1.cnf
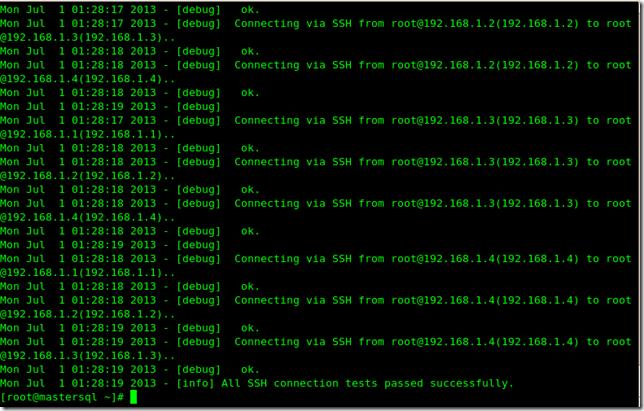
之前的都看不到了 可以看到最后檢測成功
再檢查下MySQL復制
masterha_check_repl --conf=/etc/app1.cnf---------------------由于截圖太小 直接貼出檢測文字 可以看出 最后檢測都成功(雖然有些警告信息,不用去管它)。
[root@mastersql ~]# masterha_check_repl --conf=/etc/app1.cnf Mon Jul 1 02:08:33 2013 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Jul 1 02:08:33 2013 - [info] Reading application default configurations from /etc/app1.cnf.. Mon Jul 1 02:08:33 2013 - [info] Reading server configurations from /etc/app1.cnf.. Mon Jul 1 02:08:33 2013 - [info] MHA::MasterMonitor version 0.52. Mon Jul 1 02:08:33 2013 - [info] Dead Servers: Mon Jul 1 02:08:33 2013 - [info] Alive Servers: Mon Jul 1 02:08:33 2013 - [info] 192.168.1.1(192.168.1.1:3306) Mon Jul 1 02:08:33 2013 - [info] 192.168.1.2(192.168.1.2:3306) Mon Jul 1 02:08:33 2013 - [info] 192.168.1.3(192.168.1.3:3306) Mon Jul 1 02:08:33 2013 - [info] 192.168.1.4(192.168.1.4:3306) Mon Jul 1 02:08:33 2013 - [info] Alive Slaves: Mon Jul 1 02:08:33 2013 - [info] 192.168.1.2(192.168.1.2:3306) Version=5.0.77-log (oldest major version between slaves) log-bin:enabled Mon Jul 1 02:08:33 2013 - [info] Replicating from 192.168.1.1(192.168.1.1:3306) Mon Jul 1 02:08:33 2013 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jul 1 02:08:33 2013 - [info] 192.168.1.3(192.168.1.3:3306) Version=5.0.77-log (oldest major version between slaves) log-bin:enabled Mon Jul 1 02:08:33 2013 - [info] Replicating from 192.168.1.1(192.168.1.1:3306) Mon Jul 1 02:08:33 2013 - [info] Not candidate for the new Master (no_master is set) Mon Jul 1 02:08:33 2013 - [info] 192.168.1.4(192.168.1.4:3306) Version=5.0.77-log (oldest major version between slaves) log-bin:enabled Mon Jul 1 02:08:33 2013 - [info] Replicating from 192.168.1.1(192.168.1.1:3306) Mon Jul 1 02:08:33 2013 - [info] Not candidate for the new Master (no_master is set) Mon Jul 1 02:08:33 2013 - [info] Current Alive Master: 192.168.1.1(192.168.1.1:3306) Mon Jul 1 02:08:33 2013 - [info] Checking slave configurations.. Mon Jul 1 02:08:33 2013 - [warning] read_only=1 is not set on slave 192.168.1.2(192.168.1.2:3306). Mon Jul 1 02:08:33 2013 - [warning] relay_log_purge=0 is not set on slave 192.168.1.2(192.168.1.2:3306). Mon Jul 1 02:08:33 2013 - [warning] relay_log_purge=0 is not set on slave 192.168.1.3(192.168.1.3:3306). Mon Jul 1 02:08:33 2013 - [warning] relay_log_purge=0 is not set on slave 192.168.1.4(192.168.1.4:3306). Mon Jul 1 02:08:33 2013 - [info] Checking replication filtering settings.. Mon Jul 1 02:08:33 2013 - [info] binlog_do_db= , binlog_ignore_db= Mon Jul 1 02:08:33 2013 - [info] Replication filtering check ok. Mon Jul 1 02:08:33 2013 - [info] Starting SSH connection tests.. Mon Jul 1 02:08:36 2013 - [info] All SSH connection tests passed successfully. Mon Jul 1 02:08:36 2013 - [info] Checking MHA Node version.. Mon Jul 1 02:08:36 2013 - [info] Version check ok. Mon Jul 1 02:08:36 2013 - [info] Checking SSH publickey authentication and checking recovery script configurations on the current master.. Mon Jul 1 02:08:36 2013 - [info] Executing command: save_binary_logs --command=test --start_file=binlog.000003 --start_pos=4 -- binlog_dir=/var/lib/mysql,/var/log/mysql --output_file=/var/log/masterha/app1/save_binary_logs_test --manager_version=0.52 Mon Jul 1 02:08:36 2013 - [info] Connecting to root@192.168.1.1(192.168.1.1).. Creating /var/log/masterha/app1 if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /var/lib/mysql, up to binlog.000003 Mon Jul 1 02:08:37 2013 - [info] Master setting check done. Mon Jul 1 02:08:37 2013 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers.. Mon Jul 1 02:08:37 2013 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user=root --slave_host=192.168.1.2 --slave_ip=192.168.1.2 --slave_port=3306 --workdir=/var/log/masterha/app1 --target_version=5.0.77-log --manager_version=0.52 --relay_log_info=/var/lib/mysql/relay-log.info --slave_pass=xxx Mon Jul 1 02:08:37 2013 - [info] Connecting to root@192.168.1.2(192.168.1.2).. mysqlbinlog version is 3.2 (included in MySQL Client 5.0 or lower). This is not recommended. Consider upgrading MySQL Client to 5.1 or higher. Checking slave recovery environment settings.. Opening /var/lib/mysql/relay-log.info ... ok. Relay log found at /var/lib/mysql, up to mysql-relay-bin.000002 Temporary relay log file is /var/lib/mysql/mysql-relay-bin.000002 Testing mysql connection and privileges.. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Mon Jul 1 02:08:37 2013 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user=root --slave_host=192.168.1.3 --slave_ip=192.168.1.3 --slave_port=3306 --workdir=/var/log/masterha/app1 --target_version=5.0.77-log --manager_version=0.52 --relay_log_info=/var/lib/mysql/relay-log.info --slave_pass=xxx Mon Jul 1 02:08:37 2013 - [info] Connecting to root@192.168.1.3(192.168.1.3).. mysqlbinlog version is 3.2 (included in MySQL Client 5.0 or lower). This is not recommended. Consider upgrading MySQL Client to 5.1 or higher. Checking slave recovery environment settings.. Opening /var/lib/mysql/relay-log.info ... ok. Relay log found at /var/lib/mysql, up to mysql-relay-bin.000002 Temporary relay log file is /var/lib/mysql/mysql-relay-bin.000002 Testing mysql connection and privileges.. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Mon Jul 1 02:08:37 2013 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user=root --slave_host=192.168.1.4 --slave_ip=192.168.1.4 --slave_port=3306 --workdir=/var/log/masterha/app1 --target_version=5.0.77-log --manager_version=0.52 --relay_log_info=/var/lib/mysql/relay-log.info --slave_pass=xxx Mon Jul 1 02:08:37 2013 - [info] Connecting to root@192.168.1.4(192.168.1.4).. mysqlbinlog version is 3.2 (included in MySQL Client 5.0 or lower). This is not recommended. Consider upgrading MySQL Client to 5.1 or higher. Creating directory /var/log/masterha/app1.. done. Checking slave recovery environment settings.. Opening /var/lib/mysql/relay-log.info ... ok. Relay log found at /var/lib/mysql, up to mysql-relay-bin.000002 Temporary relay log file is /var/lib/mysql/mysql-relay-bin.000002 Testing mysql connection and privileges.. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Mon Jul 1 02:08:37 2013 - [info] Slaves settings check done. Mon Jul 1 02:08:37 2013 - [info] 192.168.1.1 (current master) +--192.168.1.2 +--192.168.1.3 +--192.168.1.4 Mon Jul 1 02:08:37 2013 - [info] Checking replication health on 192.168.1.2.. Mon Jul 1 02:08:37 2013 - [info] ok. Mon Jul 1 02:08:37 2013 - [info] Checking replication health on 192.168.1.3.. Mon Jul 1 02:08:37 2013 - [info] ok. Mon Jul 1 02:08:37 2013 - [info] Checking replication health on 192.168.1.4.. Mon Jul 1 02:08:37 2013 - [info] ok. Mon Jul 1 02:08:37 2013 - [warning] master_ip_failover_script is not defined. Mon Jul 1 02:08:37 2013 - [warning] shutdown_script is not defined. Mon Jul 1 02:08:37 2013 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
這時用虛擬機的話得要做個快照,因為下面我們要進行兩個小實驗 這個實驗是不可逆的
#p#
開啟MHA進程

這時我們模擬主Mysql宕機,看看數據庫是否能夠切換到備份機上
service mysqld stop
在從屬機中
mysql>show slave status \G
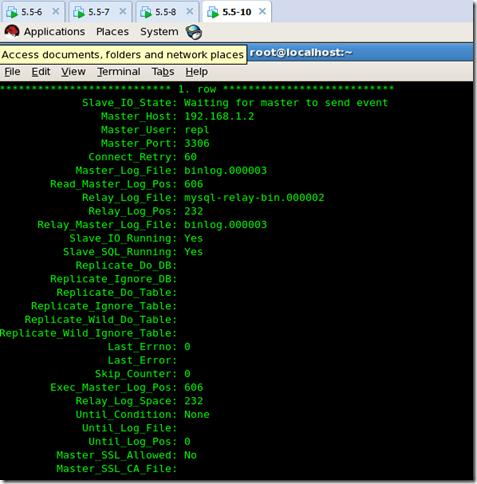
1 通過腳本實現failover(故障轉移)
2 通過keepalived實現虛擬IP 虛擬IP的地址隨著master的改變而漂移
先來第一種方式
如果仔細看上面的開啟進程中會注意到一個warning Mon Jul 1 02:08:37 2013 - [warning] master_ip_failover_script is not defined. 在/etc/app1.cnf中我們注釋了這一行,現在在/etc/app1.cnf里開啟這一行代碼,然后在/tmp/master_ip_failover寫入如下代碼:
- #!/usr/bin/env php
- <?php
- $longopts = array(
- 'command:',
- 'ssh_user:',
- 'orig_master_host:',
- 'orig_master_ip:',
- 'orig_master_port:',
- 'new_master_host::',
- 'new_master_ip::',
- 'new_master_port::', );
- $options = getopt(null, $longopts);
- if ($options['command'] == 'start') {
- $params = array(
- 'ip' => $options['new_master_ip'],
- 'port' => $options['new_master_port'],
- );
- $string = '<?php return ' . var_export($params, true) . '; ?>';
- file_put_contents('config.php', $string, LOCK_EX); }
- exit(0);
- ?>
這是一段PHP代碼 如果機器中沒裝php模塊的話要執行 yum –y install php
之后賦給這個文件可執行權限 chmod +x /tmp/master_ip_failover,
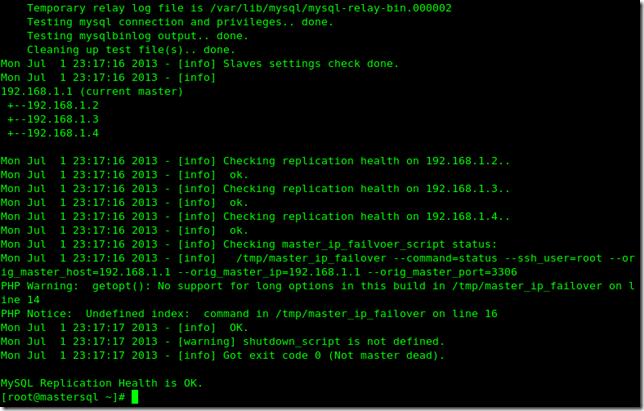
- 再次檢查后的截圖 總之是檢查OK了,這次再去把主Mysql服務器停止看看
- 再次運行MHA進程masterha_manager --conf=/etc/app1.cnf
然后停止mysql服務:
service mysqld stop
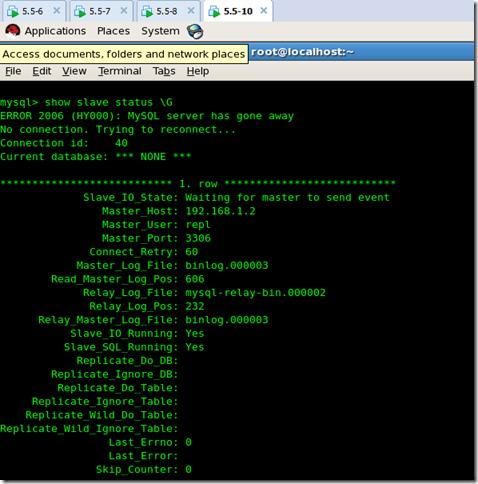
可以看到master的host成了192.168.1.2 實現了最短時間的故障轉移:
2 keepalived實現方式
首先還原快照 實驗原理已經明白 就是通過虛擬IP來管理master的狀態
在mastersql和backupsql中都安裝keepalived軟件
tar -zvxf keepalived-1\[1\].1.17.tar.gz yum -y install kernel-devel ln -s /usr/src/kernels/2.6.18-164.el5-i686/ /usr/src/linux cd keepalived-1.1.17/ yum –y install openssl-* ./configure --prefix=/usr/local/keepalived
編譯后看到三個yes才算成功 如果出現兩個yes或者一個應該要檢查下內核軟連接做對了沒有:

make make install cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ mkdir -pv /etc/keepalived cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ ln -s /usr/local/keepalived/sbin/keepalived /sbin/ service keepalived restart
注意 這里如果下載的keepalived軟件包不一樣和kernel版本不一樣 不要盲目復制粘貼該用tab命令補全就補全。
#p#
編輯mastersql的keepalived配置文件
vi /etc/keepalived/keepalived.conf 只編輯有效配置:
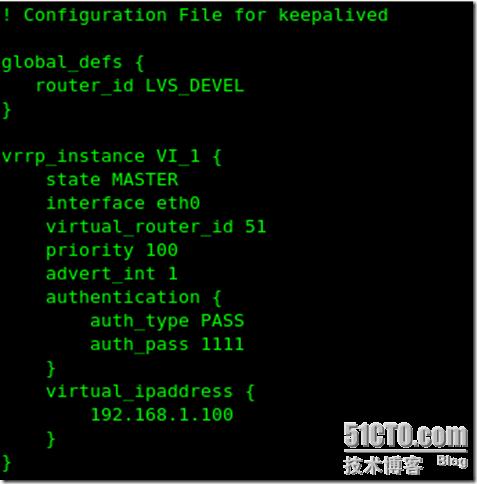
編輯backupsql的配置文件:

在mastersql上重啟keepalived服務后看ip addr
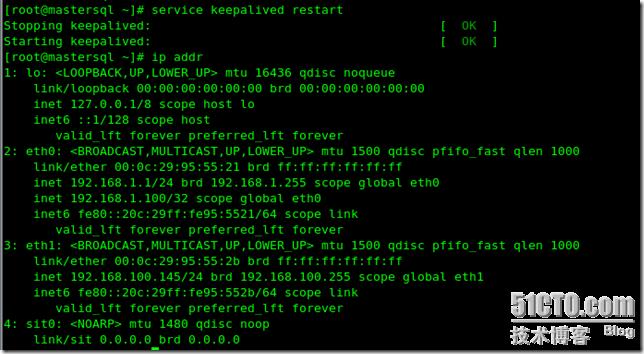
可以看到eth0上有了另外一個IP 即虛擬IP
編輯腳本文件 大體意思是只要檢測到mysql服務停止keepalived服務也停止 ,因為keepalived是通過組播方式告訴本網段自己還活著 當mysql服務停止后keepalived還依然運行 這時就需要停止keepalived讓另一個主機獲得虛擬IP,可以在后臺運行這個腳本 也可以在keepalived配置文件加入這個腳本。
mastersql上keepalived配置如下:

interval 2 是每間隔兩秒執行一次腳本 這個可以自己調節
腳本文件放置路徑在/tmp/下 注意 這個也要被賦可執行權限!
開啟MHA進程masterha_manager --conf=/etc/app1.cnf
一切都做好了只等停止mysql服務了 停止下試試
在backupsql上看ip addr:
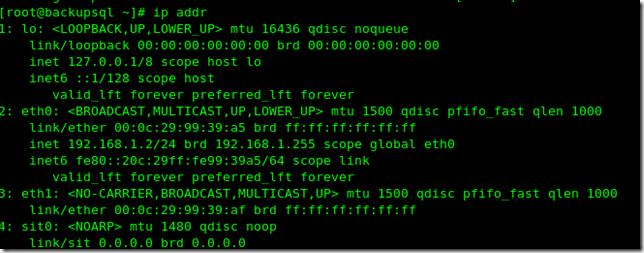
在另一臺slavesql1上查看slave status:
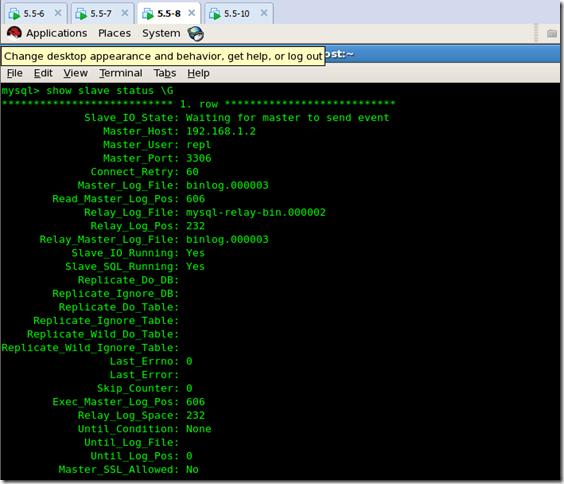
成功切換到192.168.1.2 OK 實驗完成。至此通過腳本和虛擬IP地址實現了高效率的故障轉移,實現了mysql的真正的高可用!