不會吧?還在用 MHA 做 MySQL 高可用?
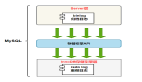
Orchestrator 是一款成熟的 MySQL 高可用中間件。采用 Go 語言編寫,支持拓撲發現、集群重塑、拓撲恢復等功能。
主要功能
拓撲發現:Orchestrator 主動搜尋并記錄 MySQL 節點的主從配置、復制狀態等基礎信息并進行拓撲映射。即使發生故障,它依然可以提供出色的可視化拓撲圖。
集群重塑:Orchestrator 了解復制規則。它能準確識別復制類型:Binlog 位點復制、GTID 復制、偽 GTID 復制、Binlog Server。Orchestrator 還提供了復制檢查功能,保證了副本的移動安全可靠。
拓撲恢復:Orchestrator 定義了 30 種故障模型,根據集群拓撲信息可精準識別故障類型。針對不同的故障類型還提供了 15 種恢復執行計劃,大大降低了恢復失敗的概率。
優勢
相較于 MHA 它有以下優勢:
- 可視化:Orchestrator 提供了整潔的可視化界面
- 拓撲發現:拓撲自動發現的能力,大大簡化了集群管理
- 高可用:Orchestrator 自身基于 Raft 一致性算法實現高可用
- 安全:Orchestrator 強大的審計功能,讓我們的每一步操作都有跡可循
- 精準:多達 30 種故障模型,大大降低了誤切的可能性
- 高效:Orchestrator 為我們提供了 200+ 的 api 來幫助我們管理 MySQL
- 快速:3s 發現故障 7s 完成切換
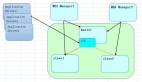
高可用
Orchestrator 高可用的實現主要分為兩步:
故障檢測
函數入口:ContinuousDiscovery --> CheckAndRecover --> GetReplicationAnalysis
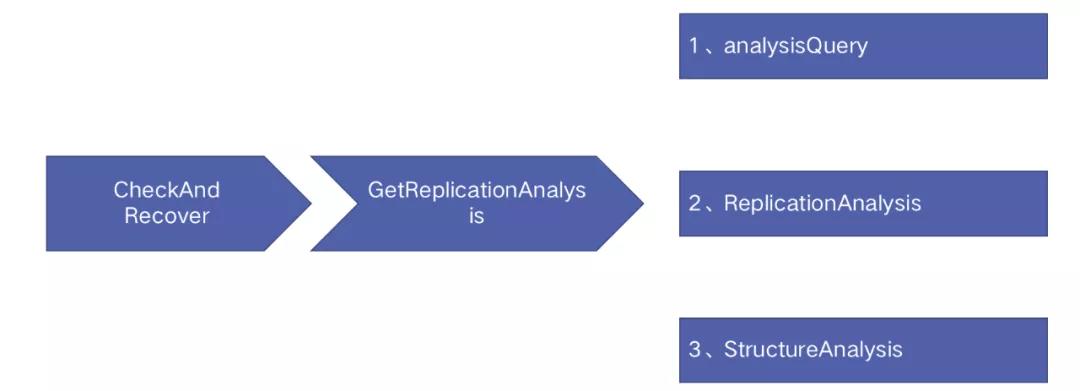
故障檢測的工作周期為 1 秒,它的主要工作如上圖所示:
- 集群拓撲信息獲取:通過 select 語句從后端獲取 Binlog 位點、探活是否有效、從庫復制情況等集群拓撲信息;
- 定義故障類型:通過獲取到的集群拓撲信息判定故障類型;
- 探測潛在故障:除了判定故障類型外還會探測集群可能存在的潛在故障。Orchestrator 一共定義了 err1236 在內的 15 種潛在故障類型;
故障恢復
函數入口:ContinuousDiscovery --> CheckAndRecover --> executeCheckAndRecoverFunction
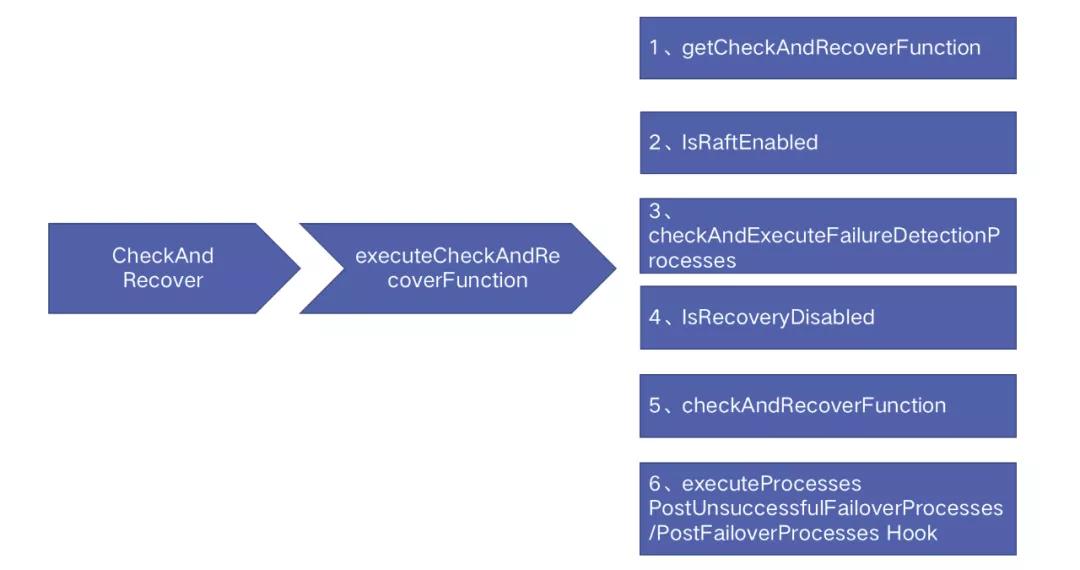
故障恢復的工作周期也是 1 秒,它的主要工作如下:
- 獲取恢復執行計劃:Orchestrator 一共定義了 15 種執行計劃,根據不同的故障類型它會選擇不同的執行計劃;
- leader 節點檢查:Orchestrator 集群只有 leader 節點有權限執行恢復操作;
- 故障注冊:對于每一個故障只有注冊成功才能執行后續的恢復操作;
- 全局恢復設置檢查:檢查是否開啟了全局恢復禁止,如果有則中斷恢復;
- 執行步驟 1 中獲取的執行計劃;
- 調用 PostUnsuccessfulFailoverProcesses/PostFailoverProcesses 鉤子 ;
執行計劃
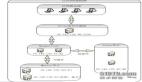
Orchestrator 定義了 15 種執行計劃,本次詳解故障類型 DeadMaster
故障定義:主節點無法訪問,且所有從節點的復制都處于失敗狀態;
判斷標準:1、主節點訪問失敗;2、從節點訪問正常,且所有從節點復制都失敗;
DeadMaster 的執行計劃為:checkAndRecoverDeadMaster
函數入口:CheckAndRecover --> executeCheckAndRecoverFunction --> checkAndRecoverDeadMaster

詳細流程如上圖:
- 注冊本次故障恢復;
- 調用 PreFailoverProcesses Hook ;
- 獲取恢復類型:GTID、偽 GTID、Binlog 位點;
- 集群重塑:選主、集群拓撲調整;
- 給故障節點打上維護標簽;
- 切換前地理位置檢測:如果我們做了不允許跨 DC 故障轉移的設置,本次恢復將中斷;
- 檢查新主的復制延時是否超過閥值,如果超過將中斷本次恢復;
- 解析本次恢復,為本次恢復打上成功或者失敗的標簽;
- 新主執行:stop slave; 和 reset slave all;
- 新主執行:set read only false;
- 嘗試舊主執行:set read only true;
- 在新主執行分離操作:在新主上利用 change master to master_host="//host" ... 命令給 master_host 加上注釋標簽,防止舊主復活后新主重新掛載。這一步和第 9 步互斥;
- 替換集群名;
- 調用 PostMasterFailoverProcesses Hook;
集群重塑
執行計劃中最為關鍵的就是 RegroupReplicasGTID (集群重塑)這一步,接下來我們繼續分析 Orchestrator 的集群重塑;
集群重塑一共有三個主要工作:選主、復制檢查、結構調整;
選主
- 同 DC、同物理環境檢查
- 提升權限檢查:must > prefer
- 副本有效性檢查:檢查副本是否開啟 Binlog、檢查副本是不是偽副本( Binlog Server)
- 提升權限被禁止檢查:候選副本被禁止參與選主(被禁止包含:PromoteRule 禁止和配置文件中 PromotionIgnoreHostnameFilters 參數禁止)
- 版本檢查:版本不低于集群中大多數版本
- Binlog 格式檢查:Binlog 格式不小于集群中的最大 binlog 格式(比較規則:ROW>MIX>STATEMENT)
復制檢查
主要是執行有效從節點到新主節點的復制可行性檢查,具體如下:
- 檢查新主是否開啟 Binlog 日志;
- 檢查新主是否開啟 log_slave_updates 參數;
- 從節點和主節點版本比較:從庫是否比主庫版本小、從庫是否是 Binlog server;
- 從庫在開啟 Binlog 和 log_slave_updates 的情況下檢查從庫的 Binlog 格式是否低于新主;
- 排除被復制篩選掉的從節點(VerifyReplicationFilters 參數控制開關);
- 檢查 sever id 是否相等;
- 檢查 uuid 是否相等且不得為空;
- 檢查是否從庫 sqldelay < 新主 sqldelay 且主庫 sqldelay > ReasonableMaintenanceReplicationLagSeconds 參數;
結構調整
- 結構調整主要分為三步:
- StopReplication:1、從節點有效性檢查;2、執行 stop slave;
- ChangeMasterTo: 1、檢查從節點 io 線程和 sql 線程是否停止;2、新主 hostname 解析;3、執行 change master to master_host=?, master_port=?;
- StartReplication:執行 start salve;
本文轉載自微信公眾號「悅專欄」,可以通過以下二維碼關注。轉載本文請聯系悅專欄公眾號。