活的大數據實戰——人群標簽及標簽關聯性挖掘
2013年初,第85屆奧斯卡金像獎頒獎禮在美國好萊塢舉行。而在頒獎禮之前,微軟紐約研究院經濟學家David·Rothschild通過大數據分析,對此次奧斯卡各獎項的得主進行了預測。結果顯示,除最佳導演獎有所出入外,其它各獎項全部命中。這并不是David第一次準確預測,在2012年美國總統大選中,他就曾準確預測了51個選區中50個地區的選舉結果,準確度高于98%。
“大數據”時代的到來,為各個行業利用數據進行預判、分析、優化都起到了至關緊要的作用。而如何使大數據發揮其根本價值,真的為我們所用,是全世界數據算法科學家為之奮斗的技術性難題。
找出數據間的關系——
1980年,托夫勒在《第三次浪潮》中就曾預言:“如果說IBM的主機拉開了信息化革命的大幕,那么‘大數據’則是第三次浪潮的華彩樂章”。
在數據呈十萬億億字節ZB級增長的當下,如何從海量數據中獲取并過濾有價值的關系信息,是對所有數據從業者而言的一大挑戰。而如何建立數據間的關系,也是如何使大數據“活”起來的必經之路。
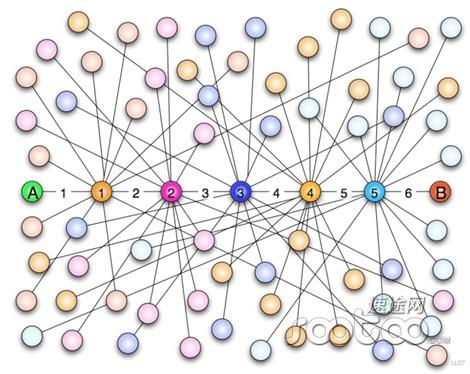
在日常生活中,我們常會發現這樣的情況,在諸如谷歌、百度等搜索引擎搜索若干關鍵詞后,例如“睫毛膏”、“不暈染”、“濃密”、“纖長”等關鍵字,在搜索結果頁面常會看到睫毛膏的廣告推廣。似乎,這些搜索引擎明確知道了我們想要做什么、我們會對什么感興趣。
這一切其實并不神奇,這只是算法科學家通過數據收集、建模、分析之后,將用戶、搜索字、搜索字相關廣告這幾類數據進行了關聯。所以當我們進行搜索的時候,看到匹配的廣告,就并不難以理解了。
最近,美國的“棱鏡”計劃引起了全世界范圍內的關注,諸如個人隱私等話題被不斷提及。在一系列爭議之中,隨著IT業巨頭們紛紛被斯諾登拉下水,“大數據”這一個先鋒技術概念再次被拉到聚光燈前。
有人甚至“善意”的對后續前往美國留學的求學者提出建議,在與家人或朋友的電話中多提及諸如“如何用高壓鍋制造炸彈”、“怎么制造TNT炸藥”等敏感字眼,用來加大美國情報分析機構的工作量。然而,這種方法真的有效嗎?我看并不盡然。
事實上,沒有規律和結構可言的數據并無任何意義,而美國的數據分析家顯然早已認識到這一點。僅僅獲取電話錄音、上網足跡等數據、將這些數據匯聚在一起并不足夠,這僅僅完成了“大數據”。而真正使數據產生價值,只有將這些碎片化的數據進行分析比對,將人們的真實身份、性格、消費習慣、需求等個人信息還原后,數據才得以“活”起來。
據美國數據分析家所言,僅通過一次電話發生的時間、通話時長、通話的地點這幾條數據,就可判斷出該通話是否存在恐怖襲擊的可能性。而這,就是通過建立海量的用戶通話數據與恐怖襲擊之間的聯系后,才得出的分析結論。#p#
可靠的數據模型——
David·Rothschild表示:“我們創建的模型是能夠預測未來的,而不只是過去發生的。科學是相同的,但證明哪些數據最有用卻存在千差萬別。”

和傳統由人工進行數據統計及收集的方式,網絡時代的數據更多來自機器,利用機器進行自動化的數據抓取及存儲,并批量化導入數據庫用于后續分析及使用。
例如某條街道上記錄車流量的攝像頭,通過24小時的實時監控將道路情況,整理統計并用于后續分析。而通過攝像頭記錄道路情況,顯然比傳統交警站崗統計違章情況更有效,但同時對于數據的分析要求也就更高。
在大數據時代,隨著數據規模呈指數級增長,對數據進行加工和分析的主角,也由原先統計和分析人員變成了程序員和算法師。程序員和算法師通過建立了無數且復雜的數學模型,并不斷進行優化與調整,找尋出數據間微妙的聯系,并在各渠道中對這些聯系進行應用。
我們先撇開“棱鏡”計劃這件事情本身是否應該存在的爭議性不談,單純從技術角度來講,“棱鏡”計劃與大數據時代的發展是密不可分的。
誠然,每個個體的行為也許都不盡相同,但都是有規律的。通過海量數據的獲取與分析,能夠獲得人們的行為習慣的有效信息,當信息量累積到足夠的規模之后,科學家們通過建模找尋數據間的聯系,從而對每個人的個體行為習慣進行推測,并提供分析。而“棱鏡”計劃正是通過海量數據的收集,建模與分析,找尋到單一個體與諸如“恐怖襲擊”、“隱藏罪案”等事件間的聯系,并采取相應應對方式的計劃。
當洛杉磯警方通過“棱鏡”計劃所收集到的數據,對幾十年的犯罪記錄進行分析后,預測犯罪行為模式與頻率,從而有針對地安排警力的時候,廣告主也可以通過分析海量客戶的購買行為能夠了解客戶,進行有針對的營銷以提升業務,而易傳媒人群標簽算法,就是幫助廣告主了解用戶并提升投放效果的數據分析模型,是“活”的大數據的現實實踐者。#p#
“活”的大數據實踐者——
美國記者華萊士曾經談笑風生地說:“如果它看起來像鴨子,游泳像鴨子,叫聲像鴨子,那么它可能就是只鴨子。”
而易傳媒人群標簽算法,就是幫助廣告主找到“鴨子”。
在營銷界,啤酒和尿布的案例一直為人們所熟悉。普通人可能無法理解,為什么尿布與啤酒這兩種風馬牛不相及的商品擺在一起,居然使兩者的稍量大幅增加。原來,媽媽們通經常會囑咐丈夫在下班回家的路上為孩子買尿布,而丈夫在買尿布的同時又會順手購買自己愛喝的啤酒。這個發現為商家帶來了大量的利潤,而在互聯網浩如煙海卻又雜亂無章的數據中,發現類似“啤酒和尿布”之間聯系,就是人群標簽算法的核心價值所在。
人群標簽算法首先根據互聯網的行為屬性將人進行了區隔,隨后分析不同人群之間的共同屬性,建立人群間的聯系并應用于后續的廣告投放。
這好比某超市門店發現:老張買了2瓶啤酒、4袋花生米。可是在超市中,了解一個又一個老張們的喝酒習慣沒有意義。門店需要知道的是,有多少個老張?又有多少個喝酒習慣不同的老李?將喝啤酒配花生米的老張與喝干白葡萄酒配腰果的老李分開,分成不同的客戶群體才有意義。比如只要知道,在喝酒的100個客戶里,有30個喝啤酒配花生米的老張,10個喝干白葡萄酒配腰果的老李,另外有20個老王是喝黃酒配豆腐干,這就足夠了。這時就可以知道,啤酒與花生米有關系,干白葡萄酒與腰果有關系,黃酒與豆腐干有關系,那么這些商品可以考慮一起促銷,或者擺放在相近的位置進行陳列。
易傳媒人群標簽算法,是將互聯網上的“老張”、“老李”、“老王”區分開,并找到他們真正關注的內容,將其標簽化處理后,分析標簽間的關系并進行關聯化投放的算法。比如我們發現到把瀏覽汽車網站作為每天必做事項的老張,也經常搜索“LED電視”,從而對其標記“汽車”與“LED電視”的人群標簽,當發現千千萬萬個“老張”都同時具有“汽車”與“LED電視”標簽的時候,我們發現這兩個標簽似乎存在某種必然的聯系,便可對這些“老張”們,投放LED電視的廣告了。而這在過去,僅憑經驗主義大行其道的時代,汽車與LED電視,便如啤酒與尿布一樣,是風馬牛不相及的兩種東西,是萬萬想不到這兩者之間的聯系的。

互聯網的海量數據不僅可以提煉歸類并開發成為實用的系統工具,在實際執行中,數據也是無處不在并且可以被擴展化使用的。而“人群標簽算法”就是賦予數據活力,使大數據“活”起來的一種典型體現。人群標簽算法是通過線上人群行為數據的收集,抽取并標記以產品導向的興趣標簽,經由人群標簽聚類,并對人群進行行為及興趣趨勢分析的流程化算法。
通過持續的、多渠道的、海量的數據收集及管理,易傳媒從線上到線下,從在線到移動,將受眾進行納米級微分,幫助廣告主最準找到人、管理人,支持強大的受眾區隔,提供包括26類人口屬性細分、20大類159小類行為興趣細分、3大類產品行業、數千種行業產品意向細分,共13000多個、3層結構的受眾標簽。
大數據時代,最大的創新就在于,人們可以通過算法科學家及數據分析師們不斷調整優化的數據模型來解讀大腦無法處理的數據間關系,我們的四周充斥著數據,而我們的生活也被不斷收集數據的計算機引導并優化著。
通過大數據相對理性的分析,結合大腦感性的思維方式,在面對決策和判斷是十字路口,我們會得出性價比更高的結論,得到更高效的解決方案。而這一切,才是大數據帶給我們的無盡財富和價值。而易傳媒,在將“活”的大數據運用在互聯網廣告投放這件事情上,也將不遺余力、不斷前進。