













XOR的黃色大象:Erasure Code為Hadoop節(jié)省數(shù)據(jù)恢復(fù)帶寬
來(lái)自南加州大學(xué)和Facebook的7名作者共同完成了論文《 XORing Elephants: Novel Erasure Code for Big Data》。論文作者開(kāi)發(fā)了Erasure Code家族的新成員——Locally Repairable Codes(即本地副本存儲(chǔ),以下簡(jiǎn)稱(chēng)LRC,它基于XOR。),明顯減少修復(fù)數(shù)據(jù)時(shí)的I/O和網(wǎng)絡(luò)流量。他們將這些編碼應(yīng)用在新的Hadoop組件中,并稱(chēng)之為 HDFS–Xorbas,并在Amazon AWS上和Facebook內(nèi)部做了測(cè)試。
從Reed Solomon code到LRC
大約十年前,業(yè)界開(kāi)始采用 Reed Solomon code對(duì)數(shù)據(jù)分發(fā)兩份或三份,替代傳統(tǒng)的RAID5或RAID6。由于采用了廉價(jià)的磁盤(pán)替代昂貴的存儲(chǔ)陣列,所以這種方法非常經(jīng)濟(jì)。Reed Solomon code和XOR都是Erasure Code的分支。其中,XOR只允許丟失一塊數(shù)據(jù),而Reed Solomon code可以容忍丟失多塊數(shù)據(jù)。
但標(biāo)準(zhǔn)的Reed Solomon code并不能很好的解決超大規(guī)模Hadoop負(fù)載。因?yàn)閿?shù)據(jù)修復(fù)的時(shí)間和花費(fèi)(主要為I/O和網(wǎng)絡(luò)流量)成本較高。同時(shí),在一段時(shí)間內(nèi),指數(shù)級(jí)增長(zhǎng)的數(shù)據(jù)超出了互聯(lián)網(wǎng)公司的基礎(chǔ)設(shè)施能力。三副本有時(shí)候也不能滿足更高的可靠性需求。
現(xiàn)在,這些互聯(lián)網(wǎng)巨頭設(shè)計(jì)的存儲(chǔ)系統(tǒng)標(biāo)準(zhǔn)為:即便四個(gè)存儲(chǔ)對(duì)象同時(shí)失效(這些對(duì)象包括磁盤(pán)、服務(wù)器、節(jié)點(diǎn),甚至整個(gè)數(shù)據(jù)中心),也不能失去任何數(shù)據(jù)(目前Reed Solomon code是采用(10,4)策略,即10個(gè)數(shù)據(jù)塊生成4個(gè)校驗(yàn)文件,可以容忍丟失4塊數(shù)據(jù)。)。從這篇論文來(lái)看,F(xiàn)acebook采用Erasure Code方式后,相對(duì)于Reed Solomon code只需要60%的I/O和網(wǎng)絡(luò)流量。
論文作者分析了Facebook的Hadoop集群中的3000個(gè)節(jié)點(diǎn),涉及45PB數(shù)據(jù)。這些數(shù)據(jù)平均每天有22個(gè)節(jié)點(diǎn)失效,有些時(shí)候一天的失效節(jié)點(diǎn)超過(guò)100個(gè),見(jiàn)圖1。
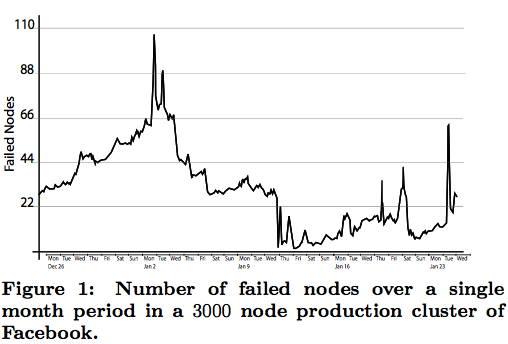
圖1:日節(jié)點(diǎn)失效圖
Hadoop集群的網(wǎng)絡(luò)經(jīng)常被被動(dòng)占用,幾個(gè)活躍的磁盤(pán)就可以占滿1Gb帶寬,修復(fù)失效數(shù)據(jù)產(chǎn)生的擁堵是不可能忽略不計(jì)的。一個(gè)理想的存儲(chǔ)方案不僅要保證存儲(chǔ)效率,還要減少修復(fù)數(shù)據(jù)所需的流量。
LRC測(cè)試結(jié)果的主要指標(biāo):
——磁盤(pán)I/O和網(wǎng)絡(luò)流量比Reed Solomon code減少一半;
——LRC比Reed Solomon code多占用14%的存儲(chǔ)空間;
——修復(fù)時(shí)間大幅縮短;
——更強(qiáng)的可靠性;
——對(duì)網(wǎng)絡(luò)流量需求降低將實(shí)現(xiàn)適當(dāng)?shù)臄?shù)據(jù)物理分布,甚至跨數(shù)據(jù)中心分布。

表1:LRC與Reed Solomon code、傳統(tǒng)Hadoop三副本策略對(duì)比。LRC比Reed Solomon code的無(wú)故障運(yùn)行時(shí)間提升兩個(gè)數(shù)量級(jí),修復(fù)流量減少一半。
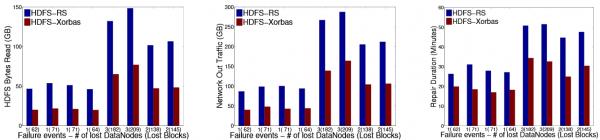
圖2:LRC與Reed Solomon code在多節(jié)點(diǎn)、多數(shù)據(jù)塊失效的情況下,HDFS讀取數(shù)據(jù)量、網(wǎng)絡(luò)流量和修復(fù)時(shí)間的對(duì)比,LRC基本上比Reed Solomon code節(jié)省一半資源。
包括 HDFS-3544在內(nèi),業(yè)界正在不斷追求高可靠下對(duì)網(wǎng)絡(luò)帶寬的節(jié)省方法,這對(duì)于互聯(lián)網(wǎng)巨頭和云計(jì)算基礎(chǔ)架構(gòu)服務(wù)商而言的意義不言而喻。由南加州大學(xué)、韋恩州立大學(xué)和微軟共同參與的《 Simple Regenerating Codes》也在朝這個(gè)方向努力。值得注意的是,前文所說(shuō)的LRC、HDFS-3544和《Simple Regenerating Codes》都是通過(guò)增加本地?cái)?shù)據(jù),來(lái)減少修復(fù)數(shù)據(jù)需要的網(wǎng)絡(luò)流量。
在 ATC2012上,微軟Azure工程師Cheng Huang和他的同事分享了《 Erasure Coding in Windows Azure Storage》。Cheng Huang表示,微軟在Azure上也使用了LRC技術(shù)。 這里可以看到Cheng Huang此次分享視頻。另外,Cheng Huang也參與了《Simple Regenerating Codes》。
在國(guó)內(nèi),Azure在世紀(jì)互聯(lián)北京、上海的兩個(gè)數(shù)據(jù)中心部署了服務(wù)。在接受CSDN采訪時(shí),微軟云計(jì)算與服務(wù)器事業(yè)部總經(jīng)理嚴(yán)治慶 透露:
Windwos Azure上的數(shù)據(jù)要存放6份,即使是虛機(jī)的本地存儲(chǔ)也不例外。在中國(guó),沒(méi)有一家公有云計(jì)算的公司愿意去承諾三個(gè)9這樣的 SLA,但微軟會(huì)承諾3個(gè)9或更高。
關(guān)于HDFS–Xorbas、LRC和GFS2
目前,HDFS–Xorbas基于Facebook的HDFS-RAID版Hadoop( GitHub入口、 Apache入口)修改而來(lái),并在 GitHub上托管代碼。
HDFS–Xorbas項(xiàng)目由 Maheswaran Sathiamoorthy維護(hù),他是一名南加州大學(xué)謝明電子工程部的候選教授。咨詢(xún)公司TechnoQWAN創(chuàng)始人Robin Harris在 文章中表示:論文中的幾名作者已經(jīng)創(chuàng)立了公司。
論文作者之一的 Dhruba Borthakur是Facebook的Hadoop工程師,他在2009年的一篇 博客中對(duì)Erasure Code進(jìn)行了介紹:
我知道使用Erasure Code的想法來(lái)自 DiskReduce,這是一幫來(lái)自卡內(nèi)基梅隆大學(xué)的家伙搞出來(lái)的。于是我借用了這個(gè)想法,并在Apache Hadoop上增加了這一功能 HDFS-503。
Dhruba強(qiáng)調(diào),HDFS Erasure Code只是在HDFS之上的代碼,并沒(méi)有對(duì)HDFS內(nèi)部代碼進(jìn)行修改。這樣做的原因是HDFS代碼已經(jīng)十分復(fù)雜,不想自找麻煩把它弄的更復(fù)雜。
Dhruba還在Hadoop Summit 2012中的一個(gè)關(guān)于HDFS的 研討會(huì)上談到了HDFS-RAID在Facebook內(nèi)部運(yùn)行的情況。數(shù)據(jù)工程師 梁堰波在 博客中分享了Dhruba的觀點(diǎn):
存放在HDFS上的數(shù)據(jù)分為熱數(shù)據(jù)和冷數(shù)據(jù)兩種。熱數(shù)據(jù)一般是存放三備份,因?yàn)檫@些數(shù)據(jù)經(jīng)常會(huì)被用到,所以多備份除了高效冗余外還能起到負(fù)載均衡的作用。對(duì)于冷數(shù)據(jù),并非一定要在HDFS里面保存3個(gè)副本。Dhruba介紹了兩種不同的RAID方案,對(duì)于不太冷的數(shù)據(jù)塊A/B/C,通過(guò)XOR方式產(chǎn)生校驗(yàn)數(shù)據(jù)塊,原來(lái)的數(shù)據(jù)塊A/B/C各保留2個(gè)副本,校驗(yàn)數(shù)據(jù)塊也有兩個(gè)副本。這樣,副本系數(shù)就從3減小到了2.6(理論值)。
對(duì)于很冷的數(shù)據(jù),方案更加激進(jìn),由10個(gè)數(shù)據(jù)塊通過(guò)Reed Solomon code生成4個(gè)校驗(yàn)文件,對(duì)于原來(lái)的數(shù)據(jù)塊,只保留一個(gè)副本,校驗(yàn)數(shù)據(jù)塊有2份副本。這樣,副本系數(shù)就降到了1.2。
梁堰波在 博客分享了Dhruba介紹的分布式RAID文件系統(tǒng)實(shí)現(xiàn)原理,在2009年Dhruba的博客中也對(duì)此進(jìn)行了介紹,可以分別查閱。
當(dāng)然,Hadoop不過(guò)是GFS的開(kāi)源實(shí)現(xiàn),那么Google是如何解決數(shù)據(jù)修復(fù)帶來(lái)的高成本呢?在Google GFS2(Colossus)中使用了Reed Solomon code來(lái)復(fù)制。在Google去年發(fā)表的《 Spanner: Google's Globally-Distributed Database》( CSDN摘譯稿)中透露:
Reed Solomon code可以將原先的3副本減小到1.5副本,提高寫(xiě)入性能,降低延遲。
但是關(guān)于GFS2的信息,Google透露非常有限。Google首席工程師Andrew Fikes在Faculty Summit 2010會(huì)議上分享了《 Google的存儲(chǔ)架構(gòu)挑戰(zhàn)》,他談到了Google為什么使用Reed Solomon code,并列舉了以下理由:
——成本。特別是跨集群的數(shù)據(jù)拷貝。
——提升平均無(wú)故障時(shí)間(MTTF)。
——更靈活的成本控制和可用性選擇。














