













談談WEB開發中的苦大難字符集問題
記得剛做javaweb開發的時候被這個編碼問題搞得暈頭轉向,經常稀里糊涂的編碼正常了一會編碼又亂了。那個時候迫于項目進度大多都是知其然不知其所以然。后來有時間就把整個體系搞了個遍,終于摸通了來龍去脈。
在C++的CGI開發時大家喜歡用latin,這個屬于字節方式的編碼格式,存儲mysql節約空間,而C++也是比較容易控制到byte級別的語言。所以經過框架封裝基本也問題不大。
在Java語言中,要涉及修改編碼問題的地方還真多。一個地方沒有設好就會亂碼滿天飛。大概總結包括以下這幾部分:瀏覽器、服務器、數據庫、操作系統。
瀏覽器:
如果使用模板語言,html需要設置顯示的字符集。這個適用于瀏覽器判斷什么編碼顯示。
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
擴展,瀏覽器識別編碼的順序:
1.如果HTTP頭部申明了charset,則會使用HTTP頭部的,
2.讓HTTP頭部沒有設置,則會去解析meta標簽的,
3.如果meta也沒有的話,瀏覽器會根據是否設置了auto detect來進行編碼識別,
4.否則會使用本地UI的字符編碼。
服務器:
對于JSP等動態語言,需要在jsp頭部設置編碼格式,J2EE服務器解析這個JSP的時候才會把整個頁面編碼為UTF-8輸出,不然就按照系統默認編碼格式ISO-8859-1輸出了。JSP設置格式如下:
- <%@ page language= "java" contentType = "text/html; charset=UTF-8"
- pageEncoding ="UTF-8" %>
大家都知道,JSP對應的就是servlet。servlet的編碼對應如下設置:
- public void service(HttpServletRequest request, HttpServletResponse response)
- throws ServletException,IOException{
- response.setContentType("text/html;charset=utf-8");
- }
還有不要漏掉大家常用的spring工具類,編碼轉換filter,很實用。在你用struts、spring mvc時這個過濾器幫你轉換沒有設置的編碼過濾。如下設置:
- <filter>
- <filter-name> Set Character Encoding</filter-name>
- <filter-class>
- org.springframework.web.filter.CharacterEncodingFilter
- </filter-class>
- <init-param>
- <param-name> encoding</param-name>
- <param-value> UTF-8</param-value>
- </init-param>
- </filter>
萬一還有亂碼怎么辦呢?doGet方式的參數傳遞肯定會有亂碼問題。只需要在tomcat的監聽器里設置編碼字符集如下(文件一般存儲在 /tomcat安裝目錄/conf/server.xml ):
- <Connector port="80" protocol="HTTP/1.1"
- connectionTimeout="20000"
- redirectPort="8443" URIEncoding="utf-8" />
大家在開發的時候別忘了java文件本身也是有編碼格式的。在類文件右鍵查看屬性。
如果開發時忘記更改文件的編碼格式,windows默認是GBK的,后來又要一直到utf8編碼的linux怎么辦。文件巨多,總不能一個一個去更改吧。其實很簡單,只需要在java命令的環境參數設置 -Dfile.encoding=GBK 解決。
編譯java代碼時,如果使用ant需要在javac里設置編譯的字符集。這樣打印的log輸出到文件或者控制臺上就不會亂碼了。
- <javac debuglevel= "source,lines" source= "1.6" encoding= "utf-8">
maven編譯時設置的字符集:
- < artifactId> maven-compiler-plugin </artifactId >
- < version> 2.5 </version >
- < configuration>
- < optimize> true </optimize >
- < showDeprecation> false </showDeprecation >
- < debuglevel> lines,source </debuglevel >
- < source> 1.6 </source >
- < target> 1.6 </target >
- < encoding> UTF-8 </encoding >
- < meminitial> 128m </meminitial >
- < maxmem> 768m </maxmem >
- </ configuration>
sqlmap的sql xml,sping的xml 也是需要設置的,因為涉及到跨平臺。 頂上添加:
- <!--?xml version="1.0" encoding="UTF-8"?-->
數據庫:
這里列出大家用的最多的Mysql字符集設置。打開mysql的配置文件( linux 一般在 /etc/my.cnf ,windows在mysql的安裝目錄 my.ini)。設置如下:
- [mysqld]
- default-character-set = utf8
- [ mysql]
- character_set_server = utf8
jdbc需要設置
jdbc : mysql://192.168.0.237:3306/dzh_db?useUnicode=true&characterEncoding=UTF-8
這些都設置了一般的中文是不會有問題的。
不過最近出現了一個問題很搞怪。以前以為所有的字符只要設置好了所有數據都可以錄入數據庫,結果有些字符就不行,比如●■★這類型的。后來把這些字符變成字節碼,居然不是三位utf8的,我擦,大汗淋漓。后來查詢可以通過過濾utf8 特殊字符的方式處理。
#p#
- public static String Utf2String (byte buf[]) {
- int len = buf.length ;
- StringBuffer sb = new StringBuffer(len / 2);
- for (int i = 0; i < len; i++) {
- if (by2int(buf[i]) <= 0x7F)
- sb.append(( char ) buf[i]);
- else if (by2int(buf[i]) <= 0xDF && by2int(buf[i]) >= 0xC0) {
- int bh = by2int(buf[i] & 0x1F);
- int bl = by2int(buf[++i] & 0x3F);
- bl = by2int(bh << 6 | bl); bh = by2int(bh >> 2);
- int c = bh << 8 | bl;
- sb.append(( char ) c);
- } else if (by2int(buf[i]) <= 0xEF && by2int(buf[i]) >= 0xE0) {
- int bh = by2int(buf[i] & 0x0F);
- int bl = by2int(buf[++i] & 0x3F);
- int bll = by2int(buf[++i] & 0x3F);
- bh = by2int(bh << 4 | bl >> 2);
- bl = by2int(bl << 6 | bll);
- int c = bh << 8 | bl;
- // 空格轉換為半角
- if (c == 58865) {
- c = 32;
- }
- sb.append(( char ) c);
- }
- }
- return sb.toString();
- }
或者把mysql的字符集改為 utf8mb4 ,記得這個只有mysql55支持哦!
- [mysqld]
- default-character-set =utf8mb4
- [ mysql]
- character_set_server = utf8mb4
操作系統:
windows默認是gbk,一般不需要變動。不過大家又想每個文件都要建立為utf8格式怎么辦,不可能我們每個文件建立后都去用屬性改變一下?太麻煩!直接在eclipse設置后,同種類型的文件建立都會是utf8格式。
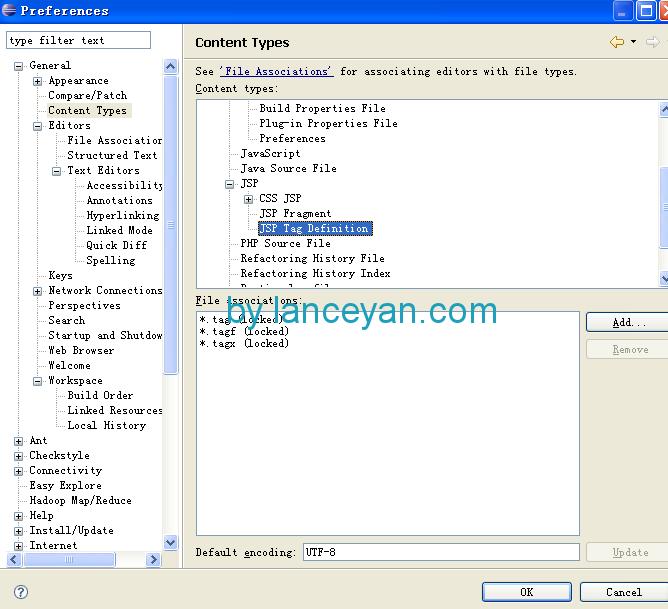
linux,可以有兩個地方修改基本就足夠了:
vi /etc/sysconfig/i18n
修改
- LANG="zh_CN.GB3212"
- LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"
- SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:en"
vi /etc/profile
- export LC_ALL="zh_CN.GB2312"
- export LANG="zh_CN.GB2312"











