教你怎樣玩轉(zhuǎn)千萬級別的數(shù)據(jù)
大數(shù)據(jù)處理是一個頭疼的問題,特別當(dāng)達(dá)不到專業(yè)DBA的技術(shù)水準(zhǔn)時,對一些數(shù)據(jù)庫方面的問題感到無奈。所以還是有必要了解一些數(shù)據(jù)庫方面的技巧,當(dāng)然,每個人都有自己的數(shù)據(jù)庫方面的技巧,只是八仙過海,所用的武功不同而已。我把我最常用的幾種方式總結(jié)來與大家分享,大家還有更多的數(shù)據(jù)庫設(shè)計和優(yōu)化的技巧,盡量的追加到評論中,有時一篇完整的博客評論比主題更為精彩。
方法1:采用表分區(qū)技術(shù)。
***次聽說表分區(qū),是以前的一個oracle培訓(xùn)。oracle既然有表分區(qū),就想到mssql是否有表的分區(qū),當(dāng)時我回家就google了一把,資料還是有的,在這我兒只是再作一次推廣,讓更多的人了解和運用這些技術(shù)。
表分區(qū),就是將一個數(shù)據(jù)量比較大的表,用某種方法把數(shù)據(jù)從物理上分成若干個小表來存儲,從邏輯來看還是一個大表。首先來個結(jié)構(gòu)圖:
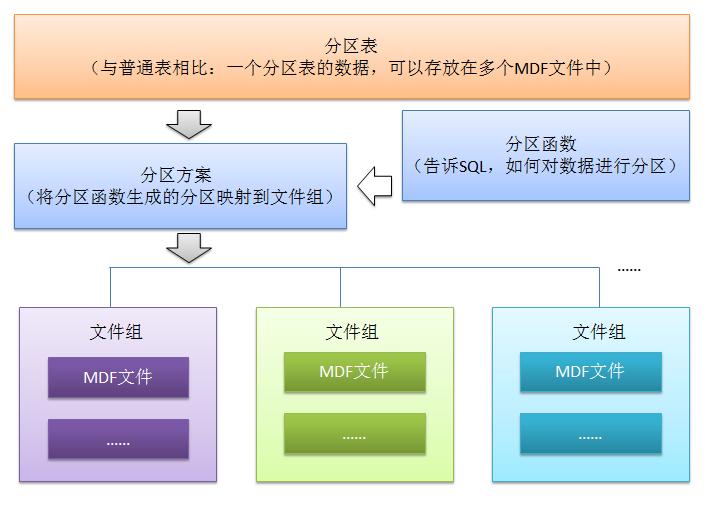
上圖雖然不能很清晰的表達(dá)表分區(qū)的執(zhí)行過程,但是可以看出表分區(qū)要用到那些對象,比如數(shù)據(jù)文件,文件組,分區(qū)方案,分區(qū)函數(shù)等。
我們以一個用戶表(TestUser)為例,假設(shè)這個表準(zhǔn)備用來存儲中國部分公民的數(shù)據(jù),每條數(shù)據(jù)記錄著每個人所屬的省份(Area),以及每個人的姓名(UserName),如下圖所示。當(dāng)數(shù)據(jù)量達(dá)到1千萬的時候,查詢就比較慢了,這時候的數(shù)據(jù)優(yōu)化就迫在眉睫。

在優(yōu)化之前,根據(jù)數(shù)據(jù)的結(jié)構(gòu),讀寫操作等,肯定會提出若干個解決方案。在這兒就以分區(qū)表的方案來優(yōu)化數(shù)據(jù)庫的查詢,這兒以區(qū)域來分別存儲數(shù)據(jù),比如廣東的公民存放在AreaFile01.MDF文件中,湖南的公民存放在AreaFile02.MDF的文件中,四川的公民存放在 AreaFile03.MDF的文件中,以此類推其它省份,為了實現(xiàn)這個功能我們就得做分區(qū)方案。在做分區(qū)方案時,首先要搞清楚分區(qū)方案要涉及到的四個對象:文件組,文件,分區(qū)函數(shù),分區(qū)方案。
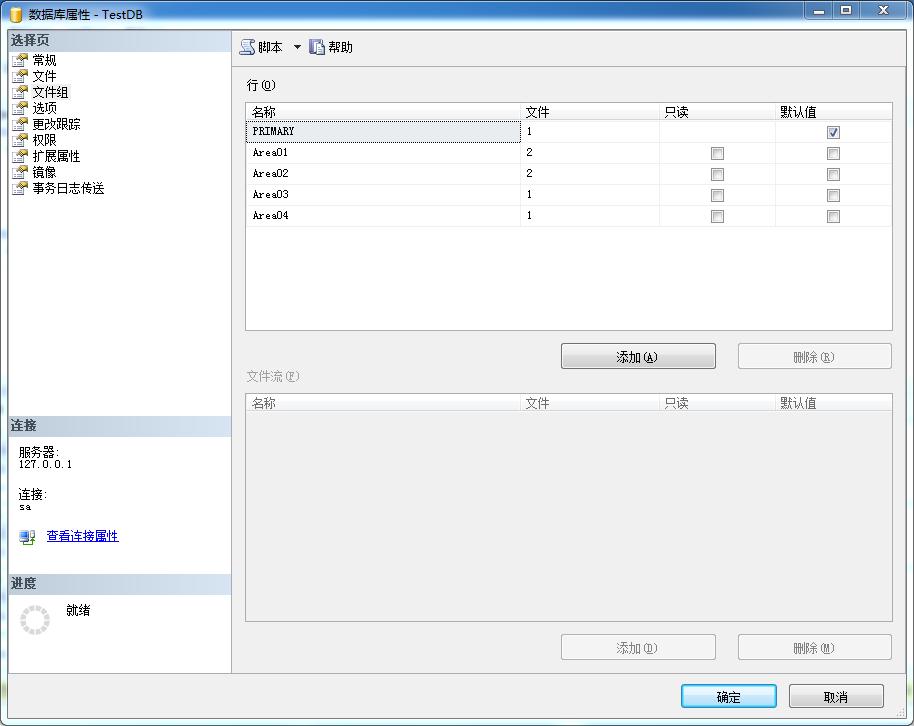
a:文件組,用來組織數(shù)據(jù)文件(.MDF)的一個虛擬名稱,一個文件組可以添加多個數(shù)據(jù)文件(.MDF)。打開SQL管理器,找到具體的數(shù)據(jù)庫,然后右鍵【屬性】,進入到【文件組】選項卡,添加Area01,Area02,Area03,Area04四個文件組。如圖:
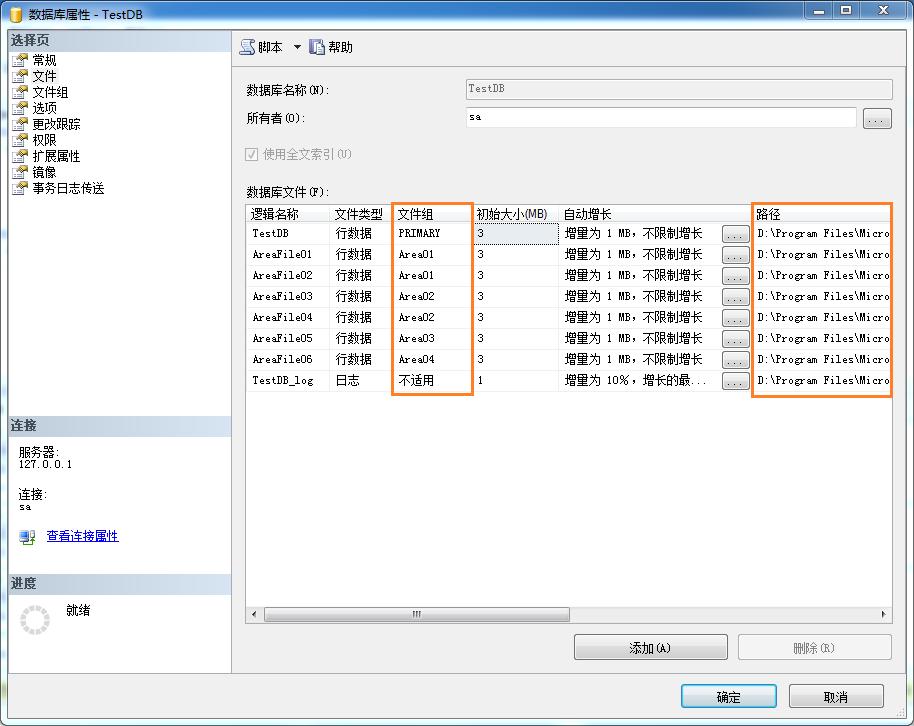
b:然后選擇中【文件】選項卡,添加 AreaFile01,AreaFile02,AreaFile03,AreaFile04,AreaFile0***reaFile06六個數(shù)據(jù)文件(.MDF),然后指定每個文件屬于那個文件組(一個文件組可以存儲多個數(shù)據(jù)文件),以及這個文件的物理路徑。在這兒大家已經(jīng)看明白了,這些數(shù)據(jù)文件,就是物理上來分割一個數(shù)據(jù)表的數(shù)據(jù)的。也就是說一個表的數(shù)據(jù)有可能存儲在AreaFile01中,也有可能存儲在AreaFile02中,只要用某種方法來指定他們的存儲規(guī)則就行了。
c:分區(qū)函數(shù),就是指定數(shù)據(jù)的存儲規(guī)則。就是告訴SQL,把新增的數(shù)據(jù)如何分區(qū)。創(chuàng)建一個分區(qū)函數(shù),可以用下邊的SQL語句來實現(xiàn)。
- CREATE PARTITION FUNCTION partitionFunArea (nvarchar(50))
- AS RANGE Left FOR VALUES ('廣東','湖南','四川')
d:辛苦的創(chuàng)建了文件,又為其指定文件組,還建一個分區(qū)函數(shù),目的只有一個,就是為了創(chuàng)建一個分區(qū)方案。分區(qū)方案可以用以下代碼來創(chuàng)建。
- CREATE PARTITION SCHEME partitionSchemeArea
- AS PARTITION partitionFunArea
- TO (
- Area01,
- Area02,
- Area03,
- Area04)
經(jīng)過緊張的四步操作,一個分區(qū)方案就呈現(xiàn)在我們的眼前了。接下來的事,就是我們要怎樣來消費這個分區(qū)方案。
首先我們創(chuàng)建一人普通的表,然后給這個表指定一個分區(qū)方案。如下代碼。
- CREATE TABLE TestUser(
- [Id] [int] IDENTITY(1,1) NOT NULL,
- [Area] nvarchar(50),
- [UserName] nvarchar(50)
- ) ON partitionSchemeArea([Area])
為了能看到效果,再插入一些數(shù)據(jù)。
- INSERT TestUser ([Area],[UserName]) Values('四川','肖一');
- INSERT TestUser ([Area],[UserName]) Values('四川','肖二');
- INSERT TestUser ([Area],[UserName]) Values('四川','肖三');
- INSERT TestUser ([Area],[UserName]) Values('四川','肖四');
- INSERT TestUser ([Area],[UserName]) Values('廣東','張一');
- INSERT TestUser ([Area],[UserName]) Values('廣東','張二');
- INSERT TestUser ([Area],[UserName]) Values('廣東','張三');
- INSERT TestUser ([Area],[UserName]) Values('湖南','楊一');
- INSERT TestUser ([Area],[UserName]) Values('湖南','楊二');
查詢所有的數(shù)據(jù),可以用select * from TestUser; 按分區(qū)查詢:就用如下方法:
- select $PARTITION.partitionFunArea([Area]) as 分區(qū)編號,count(id) as 記錄數(shù)
- from TestUser group by $PARTITION.partitionFunArea([Area])
- select * from TestUser where $PARTITION.partitionFunArea([Area])=1
- select * from TestUser where $PARTITION.partitionFunArea([Area])=2
- select * from TestUser where $PARTITION.partitionFunArea([Area])=3
- select * from TestUser where $PARTITION.partitionFunArea([Area])=4
效果圖:
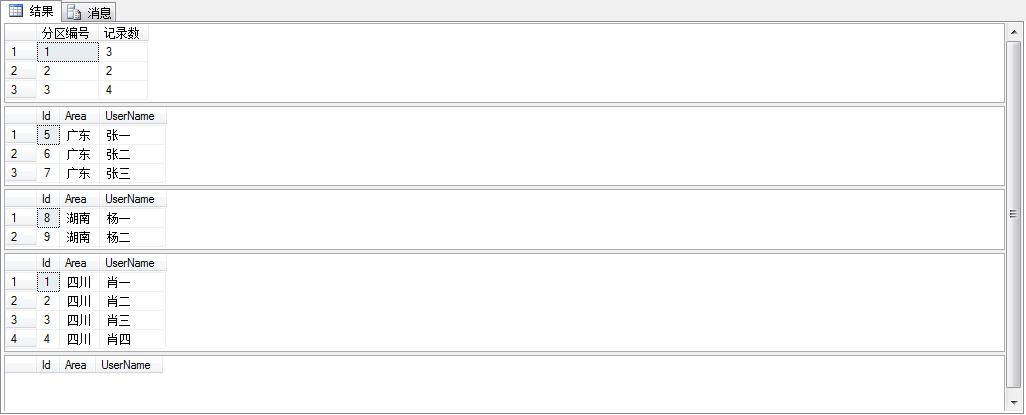
你們看我一個簡單的表的分區(qū)是不是就已經(jīng)完成了。呵呵,當(dāng)然在實際應(yīng)用中,僅僅掌握這點是不夠的,比如在原分區(qū)方案上添加一個分區(qū),刪除一個分區(qū)。
#p#
方法2:用xml類型代替主從表設(shè)計,從而達(dá)到提高查詢性能。
優(yōu)化和提高數(shù)據(jù)庫的性能,是從一個良好的數(shù)據(jù)庫設(shè)計開始的。以一個會議預(yù)訂系統(tǒng)為例,一個預(yù)訂會議系統(tǒng)包括了會議時間,會議地點,主持人,參與人,知會人,記錄者等相關(guān)信息。在的TDD,DDD模型主導(dǎo)的時代,在這兒為了更好的想表達(dá)我要闡述的問題,還是以表驅(qū)動模型來進行開發(fā)。
用戶需求:
a:一個會議可能有多個主持人,雖然這種情況比較少,但是也有可能有。
b:一個會議有多個參與人,這個不難理解。
c:一個會議有可能要讓某人知曉,這人可以參與或不參與會議,一般為高層。
d:一個會議有可能有零個或者多個記錄者。
e:一個會議需要遠(yuǎn)程視頻,投影儀,電腦,麥克風(fēng)等會議設(shè)備中的某些設(shè)備。
f:會議預(yù)訂成功,或者會議時間,會議地點等重要信息修改后,郵件通知與會人員。
常規(guī)數(shù)據(jù)庫設(shè)計:
a:建一個Meeting的主表,用于存放會議名稱,會議地點,會議時間等的相關(guān)信息。
b:再建一個MeetingUser的表存儲主持人,參與人,知會人,記錄者。
c:同樣,會議所需要的設(shè)備用MeetingDevice表來存儲相關(guān)的信息。如圖:
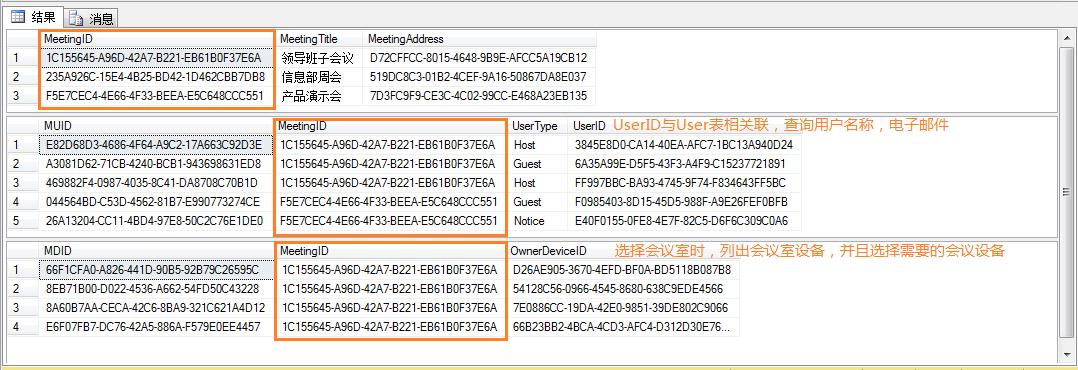
這樣的表結(jié)構(gòu),是比較常規(guī)的設(shè)計方法,但是在實際應(yīng)用中,你會發(fā)現(xiàn)一些待改進的問題。比如:
a:在提取一個會議的相關(guān)信息時,會連接多個表進行查詢。這種查詢在很大的程序上影響了數(shù)據(jù)庫性能。
b:在做修改操作時也夠嗆的,先修改主表的相關(guān)信息,再把主表關(guān)聯(lián)的子表信息全部刪除重新插入一次,這樣的操作是否夠吐血了。當(dāng)然有人精益求精,會比較修改前和修改后的數(shù)據(jù),再用增加,刪除,修改的手段達(dá)到子表數(shù)據(jù)的更新。這樣的操作在有些ORM操作中已經(jīng)實現(xiàn)了,但當(dāng)自己code代碼來實現(xiàn)的時候,特別是在多次code的時候,感覺總是那么煩心。
吐槽了這么多,是否有更好的解決方案呢?當(dāng)然,在SQL里,我們可以XML數(shù)據(jù)類型來消除主從表的設(shè)計。如圖:
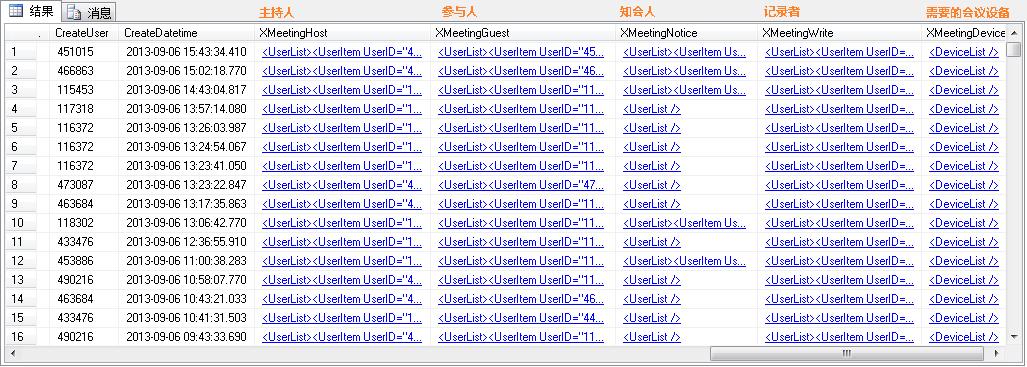
上面的表結(jié)構(gòu)設(shè)計,是不是有一個小清新的感覺呢?很明顯,可以把***種表的設(shè)計缺陷給消除了。一個會議的相關(guān)信息都存儲在了一個表的一條記錄中,這樣的數(shù)據(jù)看起來是不是更直觀呢?
a:獲取一個預(yù)訂會議的詳細(xì)信息,我不需要進行多個表的連接查詢,我要做的是只需用C#的Linq.Xml來解析查詢出來的XML字符串即可。
b:修改操作時,我只需要重新組合XML數(shù)據(jù),一個Update就更新了與會議相關(guān)的信息,操作是不是簡單多了。
表面上看這種設(shè)計已經(jīng)***了,但是用戶的需求是無止境的,有一天,你收到了一個需求,查詢某個用戶參與過的所有會議(就是只要主持人,參與人,或者記錄者中包括了這個用戶,就把這些記錄都給查詢出來),Oh!My God 這種表結(jié)構(gòu)設(shè)計應(yīng)該怎么解決這個問題呢?其實可以用XQuery解決這個問題,還沒接觸過XQuery的那得趕快充一下電了。XQuery中最常用的有 exist(),value()這些函數(shù),這兒就不詳細(xì)的介紹了,網(wǎng)上搜索一下有很多相關(guān)資料,如果有必要,我會把以前項目中用的XQuery技巧與大家分享。