Hadoop就是大數(shù)據(jù)應(yīng)用又何妨
有人說“大數(shù)據(jù)不是Hadoop;Hadoop也不代表大數(shù)據(jù)”,不知說的人什么目的,但在我看來,如今業(yè)內(nèi)對大數(shù)據(jù)認(rèn)知尚不深刻的情況下,過多糾纏于概念無助于大數(shù)據(jù)應(yīng)用。在我看來,如果強(qiáng)調(diào)“Hadoop就是大數(shù)據(jù)”利多弊少。
有關(guān)大數(shù)據(jù),“奧巴馬連任總統(tǒng)和大數(shù)據(jù)、2009年谷歌在甲型H1N1流感爆發(fā)前幾周成功預(yù)測,公共衛(wèi)生部門震驚、美國折扣店零售商塔吉特與懷孕預(yù)測、UPS快遞最佳行車路線和汽車修理預(yù)測、亞馬遜大數(shù)據(jù)書評推薦下調(diào)戰(zhàn)勝專家團(tuán)……”這樣幾個案例耳熟能詳,管中窺豹,我們可以大數(shù)據(jù)應(yīng)用的價值,但我們的盲點(diǎn)在于不知道它們是如何做的,大數(shù)據(jù)應(yīng)用是如何實(shí)現(xiàn)的。
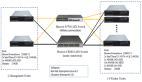
從這個意義上說,了解Hadoop就非常有意義。它可以幫助我們了解什么是大數(shù)據(jù),以及如何進(jìn)行大數(shù)據(jù)的應(yīng)用。Hadoop,分布式數(shù)據(jù)庫,僅從字面上還是很難了解其作用和價值。對此不妨看一個簡單的實(shí)例,看看搜索引擎是如何進(jìn)行大數(shù)據(jù)應(yīng)用的。首先,搜索引擎通過網(wǎng)絡(luò)爬蟲自動獲取網(wǎng)頁內(nèi)容,按照一定算法對內(nèi)容建立索引,這些索引和原始的數(shù)據(jù)用Hadoop存儲起來,并根據(jù)規(guī)則制作副本(通常是3副本)。當(dāng)用戶發(fā)起檢索需求,搜索引擎就將Map為多個并行操作,對Hadoop數(shù)據(jù)庫中的索引進(jìn)行檢索,其結(jié)果經(jīng)過Reduce,聚合為一個結(jié)果,提交給發(fā)起請求的終端。這就是搜索引擎大致一個工作過程。
我們很少把搜索引擎稱為大數(shù)據(jù)應(yīng)用,但它確實(shí)是一個典型的大數(shù)據(jù)應(yīng)用。其中的關(guān)鍵在于應(yīng)用Hadoop,用相對廉價的X86服務(wù)器,對海量低價值密度的非結(jié)構(gòu)化數(shù)據(jù)進(jìn)行存儲和處理。 從橫向擴(kuò)展性來看,其存儲和處理能力接近無限,只需要不斷添加服務(wù)器就可以了。至于存儲,可以依賴服務(wù)器自帶的磁盤,也可以理解用磁盤陣列。從Hadoop的角度,采用多副本的策略,數(shù)據(jù)可靠性已經(jīng)有所保證,如此也大大降低了對RAID、快照、復(fù)制/備份技術(shù)的依賴和要求,進(jìn)一步降低了成本。
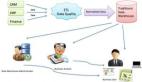
所以,把大數(shù)據(jù)理解Hadoop沒有什么不好,至少我們知道了分布式組織和存儲數(shù)據(jù)、多副本、NFS、Map/Reduce,這很好,至少我們不會為BI、ETL與大數(shù)據(jù)應(yīng)用的關(guān)系而糾結(jié),兩者各有適合應(yīng)用的場景,雖有交叉,但更多是相互補(bǔ)充。
應(yīng)該承認(rèn),沒有Hadoop+X86服務(wù)器這種廉價的手段,就不會有大數(shù)據(jù)應(yīng)用。正是因?yàn)橛辛诉@種廉價的手段,我們才能夠?qū)A康姆墙Y(jié)構(gòu)化數(shù)據(jù)的全局進(jìn)行分析。而在著名的《大數(shù)據(jù)時代》一書中,特別強(qiáng)到“不是隨機(jī)抽樣,而是全體數(shù)據(jù)”,這是大數(shù)據(jù)應(yīng)用的核心特征,對全體數(shù)據(jù)進(jìn)行分析的結(jié)果,會讓我們迅速了解事情的結(jié)果。至于所采用的手段,叫不叫Hadoop、NFS、Map/Reduce,這并不知道,但核心思路和思想一定會延續(xù),從這個意義上,將Hadoop稱為大數(shù)據(jù)應(yīng)用又有什么不可以呢?!至少我是這么看的。