Hadoop大數據面試--Hadoop篇
原理篇
1. Hadoop2.X的各個模塊一句話簡介
1)Hadoop Common:為Hadoop其他模塊提供支持的公共工具包;
2)HDFS:Hadoop分布式文件系統;
3)YARN:任務調度和集群資源管理框架;
4)MapReduce:用于處理大數據集的框架,可擴展和并行;
2. HDFS數據上傳原理
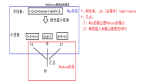
1) Client端發送一個添加文件到HDFS的請求給NameNode;
2) NameNode告訴Client端如何來分發數據塊以及分發到哪里;
3) Client端把數據分為塊(block)然后把這些塊分發到DataNode中;
4) DataNode在NameNode的指導下復制這些塊,保持冗余;
可以在講解的時候,拿只筆和紙畫下:
Tips:
a. NameNode之存儲文件的元數據,而不存儲具體的數據;
b. HDFS Federation: 解決HA單點故障問題,支持NameNode水平擴展,每個NameNode對應一個NameSpace;
3. MapReduce概述
1)map和reduce任務在NodeManager節點上各自有自己的JVM;
2)所有的Mapper完成后,實時的key/value對會經過一個shuffle和sort的階段,在這個階段中所有共同的key會被合并,發送到相同的Reducer中;
3)Mapper的個數根據輸入的格式確定,Reducer的個數根據job作業的配置決定;
4)Partitioner分區器決定key/value對應該被送往哪個Reducer中;
5)Combiner合并器可以合并Mapper的輸出,這樣可以提高性能;
4. map--》shuffle、sort--》reduce
map階段:
1) InputFormat確定輸入數據應該被分為多少個分片,并且為每個分片創建一個InputSplit實例;
2) 針對每個InputSplit實例MR框架使用一個map任務來進行處理;在InputSplit中的每個KV鍵值對被傳送到Mapper的map函數進行處理;
3) map函數產生新的序列化后的KV鍵值對到一個沒有排序的內存緩沖區中;
4) 當緩沖區裝滿或者map任務完成后,在該緩沖區的KV鍵值對就會被排序同時流入到磁盤中,形成spill文件,溢出文件;
5) 當有不止一個溢出文件產生后,這些文件會全部被排序,并且合并到一個文件中;
6) 文件中排序后的KV鍵值對等待被Reducer取走;
reduce階段:
主要包括三個小階段:
1) shuffle:或者稱為fetch階段(獲取階段),在這個階段所有擁有相同鍵的記錄都被合并而且發送到同一個Reducer中;
2) sort: 和shuffle同時發生,在記錄被合并和發送的過程中,記錄會按照key進行排序;
3) reduce:針對每個鍵會進行reduce函數調用;
reduce數據流:
1) 當Mapper完成map任務后,Reducer開始獲取記錄,同時對他們進行排序并存入自己的JVM內存中的緩沖區;
2) 當一個緩沖區數據裝滿,則會流入到磁盤;
3) 當所有的Mapper完成并且Reducer獲取到所有和他相關的輸入后,該Reducer的所有記錄會被合并和排序,包括還在緩沖區中的;
4) 合并、排序完成后調用reduce方法;輸出到HDFS或者根據作業配置到其他地方;
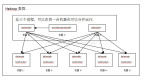
5. YARN相關
YARN包括的組件有:ResourceManager、NodeManager、ApplicationMaster,其中ResourceManager可以分為:Scheduler、ApplicationsManager
Hadoop1.X中的JobTracker被分為兩部分:ResourceManager和ApplicationMaster,前者提供集群資源給應用,后者為應用提供運行時環境;
YARN應用生命周期:
1) 客戶端提交一個應用請求到ResourceManager;
2) ResourceManager中的ApplicationsManager在集群中尋找一個可用的、負載較小的NodeManager;
3) 被找到的NodeManager創建一個ApplicationMaster實例;
4) ApplicationMaster向ResourceManager發送一個資源請求,ResourceManager回復一個Container的列表,包括這些Container是在哪些NodeManager上啟動的信息;
***pplicationMaster在ResourceManager的指導下在每個NodeManager上啟動一個Container,Container在ApplicationMaster的控制下執行一個任務;
Tips:
a. 客戶端可以從ApplicationMaster中獲取任務信息;
b. 一個作業一個ApplicationMaster,一個Application可以有多個Container,一個NodeManager也可以有多個Container;
性能篇
性能涉及較多內容,這里參考前文中給出的鏈接,并按照作業運行、map階段、reduce階段的順序來組織性能相關的點。
1. 命令行參數:
在自定義集群的參數時,不修改集群的文件,而在命令行使用參數,這樣可以針對不同的參數設置方便,從而不必修改集群中的配置文件,一般有下面兩種方式:
1)hadoop jar ExampleJob-0.0.1.jar ExampleJob -conf my-conf.xml arg0 arg1
使用配置文件的方式,把需要修改的地方設置在配置文件里面,使用-conf指定配置文件(上面命令行來自:http://www.idryman.org/blog/2014 ... ing-best-practices/);
2)hadoop jar ExampleJob-0.0.1.jar ExampleJob -Dmapred.reduce.tasks=20 arg0
使用-D參數來這是相應的值也是可以的(上面的命令行來自:http://www.idryman.org/blog/2014 ... ing-best-practices/);
2. map階段
1) map的個數問題
map的個數是不能直接設置的,如果有很多mapper的執行時間小于1分鐘,那么建議設置mapred.min.split.size的大小,提高分片的大小,這樣來減小Mapper的個數,可以減小Mapper初始化的時間;或者設置JVM重用(圖片來自:http://www.idryman.org/blog/2014 ... ing-best-practices/)
2) 設置mapred.child.java.opts參數
使用Ganglia、Nagios等監控工具檢測slave節點的內存使用情況,設置合適的mapred.child.java.opts 參數,避免交換的發生;
3)map的輸出使用壓縮
當map的輸出較多時,可以考慮使用壓縮,這能提高很大的性能(圖片來自:http://www.idryman.org/blog/2014 ... ing-best-practices/):
4)使用合適的Writable作為key(鍵)和value(值)類型
這一點在mapper和reducer的編程中都可以使用,如果全部數據都使用Text的話,那么數據的占有空間將會很大,導致效率低下。如果有必要可以自定義Writable類型。
5)重用已有變量
在mapper或者reducer的編程中重用已經定義的變量,可以避免重復的生成新對象,而導致垃圾回收頻繁的調用,如下代碼1和2(代碼參考:http://blog.cloudera.com/blog/20 ... reduce-performance/);
- public void map(...) {
- ...
- for (String word : words) {
- output.collect(new Text(word), new IntWritable(1));
- }
- }
- class MyMapper ... {
- Text wordText = new Text();
- IntWritable one = new IntWritable(1);
- public void map(...) {
- ...
- for (String word : words) {
- wordText.set(word);
- output.collect(word, one);
- }
- }
- }
6) 設置mapreduce.reduce.shuffle.parallelcopies參數
設置此參數,可以使 Reducer在一個Mapper完成后就開始獲取數據,并行化數據獲取;
7) 最小化mapper輸出:
a. 在Mapper端過濾,而不是在Reducer端過濾;
b. 使用更小的數據來存儲map輸出的key和value(參考第4)點);
c. 設置Mapper的輸出進行壓縮(參考第3)點);
3. reduce階段Reducer負載均衡:
1) Reducer的個數,根據實際集群的數量來設置Reducer的個數,使其負載均衡。比如集群有100個節點,那么Reducer的個數設置為101個則應該是不合理的,在***次任務分配時分配了100個作業,這100個作業是并行的,但是***一個作業并不是并行的。
2)Reducer中部分因為相同key的數據量大,導致個別Reducer運行耗時相比其他Reducer耗時長很多。
可以考慮:
a. 實現一個更好的hash函數繼承自Partitioner類;
b. 如果知道有大量相同的key的數據,可以寫一個預處理的作業把相同的key分到不同的輸出中,然后再使用一個MR作業來處理這個特殊的key的數據;
4. 設置輸入輸出如果有多個連續的MR作業,可以設置輸入輸出為序列文件,這樣可以達到更好的性能。
個人整理,如有錯誤,敬請指教。
分享,成長,快樂
腳踏實地,專注
【本文為51CTO專欄作者“王森豐”的原創稿件,轉載請注明出處】