Storm入門教程:消息的可靠處理
一、簡介
storm可以確保spout發送出來的每個消息都會被完整的處理。本章將會描述storm體系是如何達到這個目標的,并將會詳述開發者應該如何使用storm的這些機制來實現數據的可靠處理。
二、理解消息被完整處理
一個消息(tuple)從spout發送出來,可能會導致成百上千的消息基于此消息被創建。
我們來思考一下流式的“單詞統計”的例子:
storm任務從數據源(Kestrel queue)每次讀取一個完整的英文句子;將這個句子分解為獨立的單詞,***,實時的輸出每個單詞以及它出現過的次數。
本例中,每個從spout發送出來的消息(每個英文句子)都會觸發很多的消息被創建,那些從句子中分隔出來的單詞就是被創建出來的新消息。
這些消息構成一個樹狀結構,我們稱之為“tuple tree”,看起來如圖1所示:
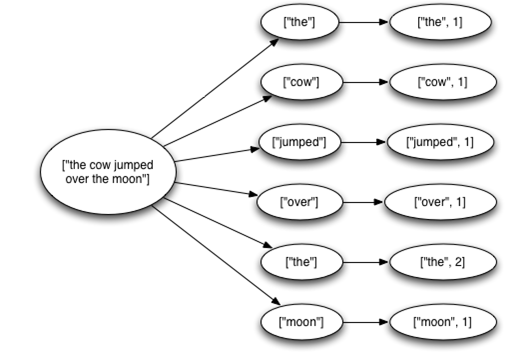
圖1 示例tuple tree
在什么條件下,Storm才會認為一個從spout發送出來的消息被完整處理呢?答案就是下面的條件同時被滿足:
- tuple tree不再生長
- 樹中的任何消息被標識為“已處理”
如果在指定的時間內,一個消息衍生出來的tuple tree未被完全處理成功,則認為此消息未被完整處理。這個超時值可以通過任務級參數Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 進行配置,默認超時值為30秒。
三、消息的生命周期
如果消息被完整處理或者未被完整處理,Storm會如何進行接下來的操作呢?為了弄清這個問題,我們來研究一下從spout發出來的消息的生命周期。這里列出了spout應該實現的接口:
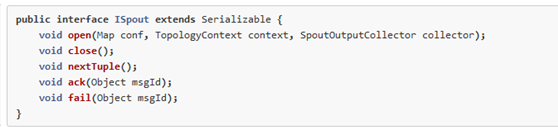
首先, Storm使用spout實例的nextTuple()方法從spout請求一個消息(tuple)。 收到請求以后,spout使用open方法中提供的SpoutOutputCollector向它的輸出流發送一個或多個消息。每發送一個消息,Spout會給這個消息提供一個message ID,它將會被用來標識這個消息。
假設我們從kestrel隊列中讀取消息,Spout會將kestrel 隊列為這個消息設置的ID作為此消息的message ID。 向SpoutOutputCollector中發送消息格式如下:

接來下,這些消息會被發送到后續業務處理的bolts, 并且Storm會跟蹤由此消息產生出來的新消息。當檢測到一個消息衍生出來的tuple tree被完整處理后,Storm會調用Spout中的ack方法,并將此消息的messageID作為參數傳入。同理,如果某消息處理超時,則此消息對應的Spout的fail方法會被調用,調用時此消息的messageID會被作為參數傳入。
注意:一個消息只會由發送它的那個spout任務來調用ack或fail。如果系統中某個spout由多個任務運行,消息也只會由創建它的spout任務來應答(ack或fail),決不會由其他的spout任務來應答。
我們繼續使用從kestrel隊列中讀取消息的例子來闡述高可靠性下spout需要做些什么(假設這個spout的名字是KestrelSpout)。
我們先簡述一下kestrel消息隊列:
當KestrelSpout從kestrel隊列中讀取一個消息,表示它“打開”了隊列中某個消息。這意味著,此消息并未從隊列中真正的刪除,而是將此消息設置為“pending”狀態,它等待來自客戶端的應答,被應答以后,此消息才會被真正的從隊列中刪除。處于“pending”狀態的消息不會被其他的客戶端看到。另外,如果一個客戶端意外的斷開連接,則由此客戶端“打開”的所有消息都會被重新加入到隊列中。當消息被“打開”的時候,kestrel隊列同時會為這個消息提供一個唯一的標識。
KestrelSpout就是使用這個唯一的標識作為這個tuple的messageID的。稍后當ack或fail被調用的時候,KestrelSpout會把ack或者fail連同messageID一起發送給kestrel隊列,kestrel會將消息從隊列中真正刪除或者將它重新放回隊列中。
四、可靠相關的API
為了使用Storm提供的可靠處理特性,我們需要做兩件事情:
- 無論何時在tuple tree中創建了一個新的節點,我們需要明確的通知Storm;
- 當處理完一個單獨的消息時,我們需要告訴Storm 這棵tuple tree的變化狀態。
通過上面的兩步,storm就可以檢測到一個tuple tree何時被完全處理了,并且會調用相關的ack或fail方法。Storm提供了簡單明了的方法來完成上述兩步。
為tuple tree中指定的節點增加一個新的節點,我們稱之為錨定(anchoring)。錨定是在我們發送消息的同時進行的。為了更容易說明問題,我們使用下面代碼作為例子。本示例的bolt將包含整句話的消息分解為一系列的子消息,每個子消息包含一個單詞。
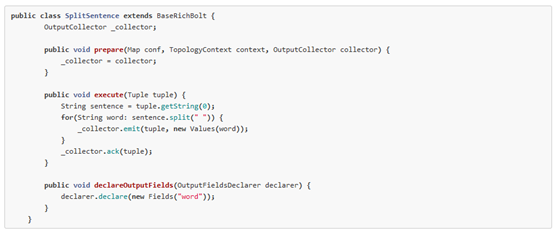
每個消息都通過這種方式被錨定:把輸入消息作為emit方法的***個參數。因為word消息被錨定在了輸入消息上,這個輸入消息是spout發送過來的tuple tree的根節點,如果任意一個word消息處理失敗,派生這個tuple tree那個spout 消息將會被重新發送。
與此相反,我們來看看使用下面的方式emit消息時,Storm會如何處理:
![]()
如果以這種方式發送消息,將會導致這個消息不會被錨定。如果此tuple tree中的消息處理失敗,派生此tuple tree的根消息不會被重新發送。根據任務的容錯級別,有時候很適合發送一個非錨定的消息。
一個輸出消息可以被錨定在一個或者多個輸入消息上,這在做join或聚合的時候是很有用的。一個被多重錨定的消息處理失敗,會導致與之關聯的多個spout消息被重新發送。多重錨定通過在emit方法中指定多個輸入消息來實現:
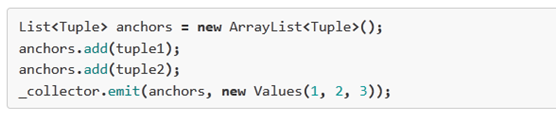
多重錨定會將被錨定的消息加到多棵tuple tree上。
注意:多重綁定可能會破壞傳統的樹形結構,從而構成一個DAGs(有向無環圖),如圖2所示:
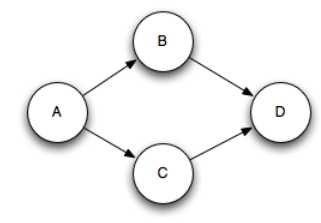
圖2 多重錨定構成的鉆石型結構
Storm的實現可以像處理樹那樣來處理DAGs。
錨定表明了如何將一個消息加入到指定的tuple tree中,高可靠處理API的接下來部分將向您描述當處理完tuple tree中一個單獨的消息時我們該做些什么。這些是通過OutputCollector 的ack和fail方法來實現的。回頭看一下例子SplitSentence,可以發現當所有的word消息被發送完成后,輸入的表示句子的消息會被應答(acked)。
每個被處理的消息必須表明成功或失敗(acked 或者failed)。Storm是使用內存來跟蹤每個消息的處理情況的,如果被處理的消息沒有應答的話,遲早內存會被耗盡!
很多bolt遵循特定的處理流程: 讀取一個消息、發送它派生出來的子消息、在execute結尾處應答此消息。一般的過濾器(filter)或者是簡單的處理功能都是這類的應用。Storm有一個BasicBolt接口封裝了上述的流程。示例SplitSentence可以使用BasicBolt來重寫:

使用這種方式,代碼比之前稍微簡單了一些,但是實現的功能是一樣的。發送到BasicOutputCollector的消息會被自動的錨定到輸入消息,并且,當execute執行完畢的時候,會自動的應答輸入消息。
很多情況下,一個消息需要延遲應答,例如聚合或者是join。只有根據一組輸入消息得到一個結果之后,才會應答之前所有的輸入消息。并且聚合和join大部分時候對輸出消息都是多重錨定。然而,這些特性不是IBasicBolt所能處理的。
#p#
五、高效的實現tuple tree
Storm 系統中有一組叫做“acker”的特殊的任務,它們負責跟蹤DAG(有向無環圖)中的每個消息。每當發現一個DAG被完全處理,它就向創建這個根消息的spout任務發送一個信號。拓撲中acker任務的并行度可以通過配置參數Config.TOPOLOGY_ACKERS來設置。默認的acker任務并行度為1,當系統中有大量的消息時,應該適當提高acker任務的并發度。
為了理解Storm可靠性處理機制,我們從研究一個消息的生命周期和tuple tree的管理入手。當一個消息被創建的時候(無論是在spout還是bolt中),系統都為該消息分配一個64bit的隨機值作為id。這些隨機的id是acker用來跟蹤由spout消息派生出來的tuple tree的。
每個消息都知道它所在的tuple tree對應的根消息的id。每當bolt新生成一個消息,對應tuple tree中的根消息的messageId就拷貝到這個消息中。當這個消息被應答的時候,它就把關于tuple tree變化的信息發送給跟蹤這棵樹的acker。例如,他會告訴acker:本消息已經處理完畢,但是我派生出了一些新的消息,幫忙跟蹤一下吧。
舉個例子,假設消息D和E是由消息C派生出來的,這里演示了消息C被應答時,tuple tree是如何變化的。

因為在C被從樹中移除的同時D和E會被加入到tuple tree中,因此tuple tree不會被過早的認為已完全處理。
關于Storm如何跟蹤tuple tree,我們再深入的探討一下。前面說過系統中可以有任意個數的acker,那么,每當一個消息被創建或應答的時候,它怎么知道應該通知哪個acker呢?
系統使用一種哈希算法來根據spout消息的messageId確定由哪個acker跟蹤此消息派生出來的tuple tree。因為每個消息都知道與之對應的根消息的messageId,因此它知道應該與哪個acker通信。
當spout發送一個消息的時候,它就通知對應的acker一個新的根消息產生了,這時acker就會創建一個新的tuple tree。當acker發現這棵樹被完全處理之后,他就會通知對應的spout任務。
tuple是如何被跟蹤的呢?系統中有成千上萬的消息,如果為每個spout發送的消息都構建一棵樹的話,很快內存就會耗盡。所以,必須采用不同的策略來跟蹤每個消息。由于使用了新的跟蹤算法,Storm只需要固定的內存(大約20字節)就可以跟蹤一棵樹。這個算法是storm正確運行的核心,也是storm***的突破。
acker任務保存了spout消息id到一對值的映射。***個值就是spout的任務id,通過這個id,acker就知道消息處理完成時該通知哪個spout任務。第二個值是一個64bit的數字,我們稱之為“ack val”, 它是樹中所有消息的隨機id的異或結果。ack val表示了整棵樹的的狀態,無論這棵樹多大,只需要這個固定大小的數字就可以跟蹤整棵樹。當消息被創建和被應答的時候都會有相同的消息id發送過來做異或。
每當acker發現一棵樹的ack val值為0的時候,它就知道這棵樹已經被完全處理了。因為消息的隨機ID是一個64bit的值,因此ack val在樹處理完之前被置為0的概率非常小。假設你每秒鐘發送一萬個消息,從概率上說,至少需要50,000,000年才會有機會發生一次錯誤。即使如此,也只有在這個消息確實處理失敗的情況下才會有數據的丟失!
六、選擇合適的可靠性級別
Acker任務是輕量級的,所以在拓撲中并不需要太多的acker存在。可以通過Storm UI來觀察acker任務的吞吐量,如果看上去吞吐量不夠的話,說明需要添加額外的acker。
如果你并不要求每個消息必須被處理(你允許在處理過程中丟失一些信息),那么可以關閉消息的可靠處理機制,從而可以獲取較好的性能。關閉消息的可靠處理機制意味著系統中的消息數會減半(每個消息不需要應答了)。另外,關閉消息的可靠處理可以減少消息的大小(不需要每個tuple記錄它的根id了),從而節省帶寬。
有三種方法可以關系消息的可靠處理機制:
- 將參數Config.TOPOLOGY_ACKERS設置為0,通過此方法,當Spout發送一個消息的時候,它的ack方法將立刻被調用;
- 第二個方法是Spout發送一個消息時,不指定此消息的messageID。當需要關閉特定消息可靠性的時候,可以使用此方法;
- ***,如果你不在意某個消息派生出來的子孫消息的可靠性,則此消息派生出來的子消息在發送時不要做錨定,即在emit方法中不指定輸入消息。因為這些子孫消息沒有被錨定在任何tuple tree中,因此他們的失敗不會引起任何spout重新發送消息。
七、集群的各級容錯
到現在為止,大家已經理解了Storm的可靠性機制,并且知道了如何選擇不同的可靠性級別來滿足需求。接下來我們研究一下Storm如何保證在各種情況下確保數據不丟失。
1、任務級失敗
因為bolt任務crash引起的消息未被應答。此時,acker中所有與此bolt任務關聯的消息都會因為超時而失敗,對應spout的fail方法將被調用。
- acker任務失敗。如果acker任務本身失敗了,它在失敗之前持有的所有消息都將會因為超時而失敗。Spout的fail方法將被調用。
- Spout任務失敗。這種情況下,Spout任務對接的外部設備(如MQ)負責消息的完整性。例如當客戶端異常的情況下,kestrel隊列會將處于pending狀態的所有的消息重新放回到隊列中。
2、任務槽(slot) 故障
- worker失敗。每個worker中包含數個bolt(或spout)任務。supervisor負責監控這些任務,當worker失敗后,supervisor會嘗試在本機重啟它。
- supervisor失敗。supervisor是無狀態的,因此supervisor的失敗不會影響當前正在運行的任務,只要及時的將它重新啟動即可。supervisor不是自舉的,需要外部監控來及時重啟。
- nimbus失敗。nimbus是無狀態的,因此nimbus的失敗不會影響當前正在運行的任務(nimbus失敗時,無法提交新的任務),只要及時的將它重新啟動即可。nimbus不是自舉的,需要外部監控來及時重啟。
3.、集群節點(機器)故障
- storm集群中的節點故障。此時nimbus會將此機器上所有正在運行的任務轉移到其他可用的機器上運行。
- zookeeper集群中的節點故障。zookeeper保證少于半數的機器宕機仍可正常運行,及時修復故障機器即可。
八、小結
本章介紹了storm集群如何實現數據的可靠處理。借助于創新性的tuple tree跟蹤技術,storm高效的通過數據的應答機制來保證數據不丟失。
storm集群中除nimbus外,沒有單點存在,任何節點都可以出故障而保證數據不會丟失。nimbus被設計為無狀態的,只要可以及時重啟,就不會影響正在運行的任務。