













Storm入門教程:一致性事務
Storm是一個分布式的流處理系統,利用anchor和ack機制保證所有tuple都被成功處理。如果tuple出錯,則可以被重傳,但是如何保證出錯的tuple只被處理一次呢?Storm提供了一套事務性組件Transaction Topology,用來解決這個問題。
Transactional Topology目前已經不再維護,由Trident來實現事務性topology,但是原理相同。
一、一致性事務的設計
Storm如何實現即對tuple并行處理,又保證事務性。本節從簡單的事務性實現方法入手,逐步引出Transactional Topology的原理。
1、簡單設計一:強順序流
保證tuple只被處理一次,最簡單的方法就是將tuple流變成強順序的,并且每次只處理一個tuple。從1開始,給每個tuple都順序加上一個id。在處理tuple的時候,將處理成功的tuple id和計算結果存在數據庫中。下一個tuple到來的時候,將其id與數據庫中的id做比較。如果相同,則說明這個tuple已經被成功處理過了,忽略它;如果不同,根據強順序性,說明這個tuple沒有被處理過,將它的id及計算結果更新到數據庫中。
以統計消息總數為例。每來一個tuple,如果數據庫中存儲的id 與當前tuple id不同,則數據庫中的消息總數加1,同時更新數據庫中的當前tuple id值。如圖:
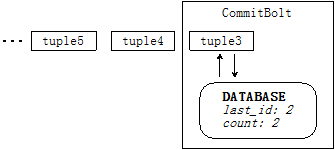
但是這種機制使得系統一次只能處理一個tuple,無法實現分布式計算。
2、簡單設計二:強順序batch流
為了實現分布式,我們可以每次處理一批tuple,稱為一個batch。一個batch中的tuple可以被并行處理。
我們要保證一個batch只被處理一次,機制和上一節類似。只不過數據庫中存儲的是batch id。batch的中間計算結果先存在局部變量中,當一個batch中的所有tuple都被處理完之后,判斷batch id,如果跟數據庫中的id不同,則將中間計算結果更新到數據庫中。
如何確保一個batch里面的所有tuple都被處理完了呢?可以利用Storm提供的CoordinateBolt。如圖:
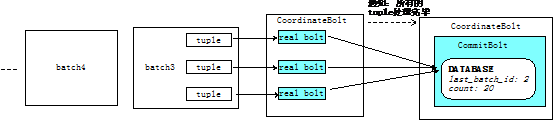
但是強順序batch流也有局限,每次只能處理一個batch,batch之間無法并行。要想實現真正的分布式事務處理,可以使用storm提供的Transactional Topology。在此之前,我們先詳細介紹一下CoordinateBolt的原理。
3、CoordinateBolt原理
CoordinateBolt具體原理如下:
- 真正執行計算的bolt外面封裝了一個CoordinateBolt。真正執行任務的bolt我們稱為real bolt。
- 每個CoordinateBolt記錄兩個值:有哪些task給我發送了tuple(根據topology的grouping信息);我要給哪些tuple發送信息(同樣根據groping信息)
- Real bolt發出一個tuple后,其外層的CoordinateBolt會記錄下這個tuple發送給哪個task了。
- 等所有的tuple都發送完了之后,CoordinateBolt通過另外一個特殊的stream以emitDirect的方式告訴所有它發送過tuple的task,它發送了多少tuple給這個task。下游task會將這個數字和自己已經接收到的tuple數量做對比,如果相等,則說明處理完了所有的tuple。
- 下游CoordinateBolt會重復上面的步驟,通知其下游。
整個過程如圖所示:
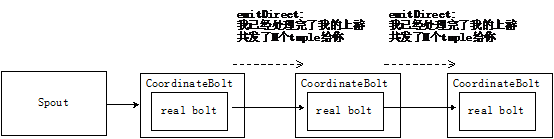
CoordinateBolt主要用于兩個場景:
- DRPC
- Transactional Topology
CoordinatedBolt對于業務是有侵入的,要使用CoordinatedBolt提供的功能,你必須要保證你的每個bolt發送的每個tuple的第一個field是request-id。 所謂的“我已經處理完我的上游”的意思是說當前這個bolt對于當前這個request-id所需要做的工作做完了。這個request-id在DRPC里面代表一個DRPC請求;在Transactional Topology里面代表一個batch。
4、Trasactional Topology
Storm提供的Transactional Topology將batch計算分為process和commit兩個階段。Process階段可以同時處理多個batch,不用保證順序性;commit階段保證batch的強順序性,并且一次只能處理一個batch,第1個batch成功提交之前,第2個batch不能被提交。
還是以統計消息總數為例,以下代碼來自storm-starter里面的TransactionalGlobalCount。
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA,new Fields(“word“), PARTITION_TAKE_PER_BATCH);
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder(“global-count“, “spout“, spout, 3);
builder.setBolt(“partial-count“, new BatchCount(), 5).noneGrouping(“spout“);
builder.setBolt(“sum“, new UpdateGlobalCount()).globalGrouping(“partial-count“);
TransactionalTopologyBuilder共接收四個參數。
- 這個Transactional Topology的id。Id用來在Zookeeper中保存當前topology的進度,如果這個topology重啟,可以繼續之前的進度執行。
- Spout在這個topology中的id
- 一個TransactionalSpout。一個Trasactional Topology中只能有一個TrasactionalSpout.在本例中是一個MemoryTransactionalSpout,從一個內存變量(DATA)中讀取數據。
- TransactionalSpout的并行度(可選)。
下面是BatchCount的定義:
- public static class BatchCount extends BaseBatchBolt {
- Object _id;
- BatchOutputCollector _collector;
- int _count = 0;
- @Override
- public void prepare(Map conf, TopologyContext context,
- BatchOutputCollector collector, Object id) {
- _collector = collector;
- _id = id;
- }
- @Override
- public void execute(Tuple tuple) {
- _count++;
- }
- @Override
- public void finishBatch() {
- _collector.emit(new Values(_id, _count));
- }
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(“id“, “count“));
- }
- }
BatchCount的prepare方法的最后一個參數是batch id,在Transactional Tolpoloyg里面這id是一個TransactionAttempt對象。
Transactional Topology里發送的tuple都必須以TransactionAttempt作為第一個field,storm根據這個field來判斷tuple屬于哪一個batch。
TransactionAttempt包含兩個值:一個transaction id,一個attempt id。transaction id的作用就是我們上面介紹的對于每個batch中的tuple是唯一的,而且不管這個batch replay多少次都是一樣的。attempt id是對于每個batch唯一的一個id, 但是對于同一個batch,它replay之后的attempt id跟replay之前就不一樣了, 我們可以把attempt id理解成replay-times, storm利用這個id來區別一個batch發射的tuple的不同版本。
execute方法會為batch里面的每個tuple執行一次,你應該把這個batch里面的計算狀態保持在一個本地變量里面。對于這個例子來說, 它在execute方法里面遞增tuple的個數。
最后, 當這個bolt接收到某個batch的所有的tuple之后, finishBatch方法會被調用。這個例子里面的BatchCount類會在這個時候發射它的局部數量到它的輸出流里面去。
下面是UpdateGlobalCount類的定義:
- public static class UpdateGlobalCount extends BaseTransactionalBolt
- implements ICommitter {
- TransactionAttempt _attempt;
- BatchOutputCollector _collector;
- int _sum = 0;
- @Override
- public void prepare(Map conf, TopologyContext context,
- BatchOutputCollector collector, TransactionAttempt attempt) {
- _collector = collector;
- _attempt = attempt;
- }
- @Override
- public void execute(Tuple tuple) {
- _sum+=tuple.getInteger(1);
- }
- @Override
- public void finishBatch() {
- Value val = DATABASE.get(GLOBAL_COUNT_KEY);
- Value newval;
- if(val == null || !val.txid.equals(_attempt.getTransactionId())) {
- newnewval = new Value();
- newval.txid = _attempt.getTransactionId();
- if(val==null) {
- newval.count = _sum;
- } else {
- newval.count = _sum + val.count;
- }
- DATABASE.put(GLOBAL_COUNT_KEY, newval);
- } else {
- newval = val;
- }
- _collector.emit(new Values(_attempt, newval.count));
- }
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(“id“, “sum“));
- }
- }
UpdateGlobalCount實現了ICommitter接口,所以storm只會在commit階段執行finishBatch方法。而execute方法可以在任何階段完成。
在UpdateGlobalCount的finishBatch方法中,將當前的transaction id與數據庫中存儲的id做比較。如果相同,則忽略這個batch;如果不同,則把這個batch的計算結果加到總結果中,并更新數據庫。
Transactional Topolgy運行示意圖如下:
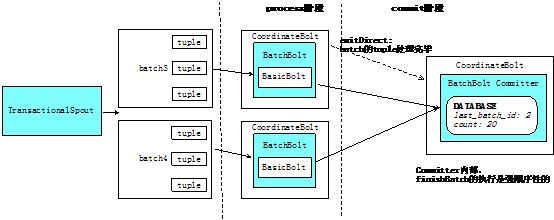
下面總結一下Transactional Topology的一些特性:
- Transactional Topology將事務性機制都封裝好了,其內部使用CoordinateBolt來保證一個batch中的tuple被處理完。
- TransactionalSpout只能有一個,它將所有tuple分為一個一個的batch,而且保證同一個batch的transaction id始終一樣。
- BatchBolt處理batch在一起的tuples。對于每一個tuple調用execute方法,而在整個batch處理完成的時候調用finishBatch方法。
- 如果BatchBolt被標記成Committer,則只能在commit階段調用finishBolt方法。一個batch的commit階段由storm保證只在前一個batch成功提交之后才會執行。并且它會重試直到topology里面的所有bolt在commit完成提交。
- Transactional Topology隱藏了anchor/ack框架,它提供一個不同的機制來fail一個batch,從而使得這個batch被replay。
二、Trident介紹
Trident是Storm之上的高級抽象,提供了joins,grouping,aggregations,fuctions和filters等接口。如果你使用過Pig或Cascading,對這些接口就不會陌生。
Trident將stream中的tuples分成batches進行處理,API封裝了對這些batches的處理過程,保證tuple只被處理一次。處理batches中間結果存儲在TridentState對象中。
Trident事務性原理這里不詳細介紹,有興趣的讀者請自行查閱資料。
參考:http://xumingming.sinaapp.com/736/twitter-storm-transactional-topolgoy/
http://xumingming.sinaapp.com/811/twitter-storm-code-analysis-coordinated-bolt/
















