如何讓Hadoop結(jié)合R語言做大數(shù)據(jù)分析?
為什么要讓Hadoop結(jié)合R語言?
R語言和Hadoop讓我們體會到了,兩種技術(shù)在各自領(lǐng)域的強(qiáng)大。很多開發(fā)人員在計(jì)算機(jī)的角度,都會提出下面2個問題。問題1: Hadoop的家族如此之強(qiáng)大,為什么還要結(jié)合R語言?
問題2: Mahout同樣可以做數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí),和R語言的區(qū)別是什么?下面我嘗試著做一個解答:問題1: Hadoop的家族如此之強(qiáng)大,為什么還要結(jié)合R語言?
- a. Hadoop家族的強(qiáng)大之處,在于對大數(shù)據(jù)的處理,讓原來的不可能(TB,PB數(shù)據(jù)量計(jì)算),成為了可能。
- b. R語言的強(qiáng)大之處,在于統(tǒng)計(jì)分析,在沒有Hadoop之前,我們對于大數(shù)據(jù)的處理,要取樣本,假設(shè)檢驗(yàn),做回歸,長久以來R語言都是統(tǒng)計(jì)學(xué)家專屬的工具。
- c. 從a和b兩點(diǎn),我們可以看出,hadoop重點(diǎn)是全量數(shù)據(jù)分析,而R語言重點(diǎn)是樣本數(shù)據(jù)分析。 兩種技術(shù)放在一起,剛好是最長補(bǔ)短!
- d. 模擬場景:對1PB的新聞網(wǎng)站訪問日志做分析,預(yù)測未來流量變化
d1:用R語言,通過分析少量數(shù)據(jù),對業(yè)務(wù)目標(biāo)建回歸建模,并定義指標(biāo)d2:用Hadoop從海量日志數(shù)據(jù)中,提取指標(biāo)數(shù)據(jù)d3:用R語言模型,對指標(biāo)數(shù)據(jù)進(jìn)行測試和調(diào)優(yōu)d4:用Hadoop分步式算法,重寫R語言的模型,部署上線這個場景中,R和Hadoop分別都起著非常重要的作用。以計(jì)算機(jī)開發(fā)人員的思路,所有有事情都用Hadoop去做,沒有數(shù)據(jù)建模和證明,”預(yù)測的結(jié)果”一定是有問題的。以統(tǒng)計(jì)人員的思路,所有的事情都用R去做,以抽樣方式,得到的“預(yù)測的結(jié)果”也一定是有問題的。所以讓二者結(jié)合,是產(chǎn)界業(yè)的必然的導(dǎo)向,也是產(chǎn)界業(yè)和學(xué)術(shù)界的交集,同時也為交叉學(xué)科的人才提供了無限廣闊的想象空間。問題2: Mahout同樣可以做數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí),和R語言的區(qū)別是什么?
- a. Mahout是基于Hadoop的數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)的算法框架,Mahout的重點(diǎn)同樣是解決大數(shù)據(jù)的計(jì)算的問題。
- b. Mahout目前已支持的算法包括,協(xié)同過濾,推薦算法,聚類算法,分類算法,LDA, 樸素bayes,隨機(jī)森林。上面的算法中,大部分都是距離的算法,可以通過矩陣分解后,充分利用MapReduce的并行計(jì)算框架,高效地完成計(jì)算任務(wù)。
- c. Mahout的空白點(diǎn),還有很多的數(shù)據(jù)挖掘算法,很難實(shí)現(xiàn)MapReduce并行化。Mahout的現(xiàn)有模型,都是通用模型,直接用到的項(xiàng)目中,計(jì)算結(jié)果只會比隨機(jī)結(jié)果好一點(diǎn)點(diǎn)。Mahout二次開發(fā),要求有深厚的JAVA和Hadoop的技術(shù)基礎(chǔ),***兼有 “線性代數(shù)”,“概率統(tǒng)計(jì)”,“算法導(dǎo)論” 等的基礎(chǔ)知識。所以想玩轉(zhuǎn)Mahout真的不是一件容易的事情。
- d. R語言同樣提供了Mahout支持的約大多數(shù)算法(除專有算法),并且還支持大量的Mahout不支持的算法,算法的增長速度比mahout快N倍。并且開發(fā)簡單,參數(shù)配置靈活,對小型數(shù)據(jù)集運(yùn)算速度非常快。
雖然,Mahout同樣可以做數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí),但是和R語言的擅長領(lǐng)域并不重合。集百家之長,在適合的領(lǐng)域選擇合適的技術(shù),才能真正地“保質(zhì)保量”做軟件。
如何讓Hadoop結(jié)合R語言?
從上一節(jié)我們看到,Hadoop和R語言是可以互補(bǔ)的,但所介紹的場景都是Hadoop和R語言的分別處理各自的數(shù)據(jù)。一旦市場有需求,自然會有商家填補(bǔ)這個空白。
1). RHadoop
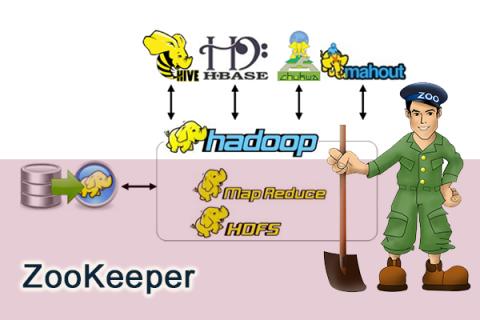
RHadoop是一款Hadoop和R語言的結(jié)合的產(chǎn)品,由RevolutionAnalytics公司開發(fā),并將代碼開源到github社區(qū)上面。RHadoop包含三個R包 (rmr,rhdfs,rhbase),分別是對應(yīng)Hadoop系統(tǒng)架構(gòu)中的,MapReduce, HDFS, HBase 三個部分。
2). RHiveRHive是一款通過R語言直接訪問Hive的工具包,是由NexR一個韓國公司研發(fā)的。
3). 重寫Mahout用R語言重寫Mahout的實(shí)現(xiàn)也是一種結(jié)合的思路,我也做過相關(guān)的嘗試。
4).Hadoop調(diào)用R
上面說的都是R如何調(diào)用Hadoop,當(dāng)然我們也可以反相操作,打通JAVA和R的連接通道,讓Hadoop調(diào)用R的函數(shù)。但是,這部分還沒有商家做出成形的產(chǎn)品。
5. R和Hadoop在實(shí)際中的案例
R和Hadoop的結(jié)合,技術(shù)門檻還是有點(diǎn)高的。對于一個人來說,不僅要掌握Linux, Java, Hadoop, R的技術(shù),還要具備 軟件開發(fā),算法,概率統(tǒng)計(jì),線性代數(shù),數(shù)據(jù)可視化,行業(yè)背景 的一些基本素質(zhì)。在公司部署這套環(huán)境,同樣需要多個部門,多種人才的的配合。Hadoop運(yùn)維,Hadoop算法研發(fā),R語言建模,R語言MapReduce化,軟件開發(fā),測試等等。所以,這樣的案例并不太多。
原文鏈接:http://www.36dsj.com/archives/6468