MapReduce連接:重分區連接
MapReduce的連接操作可以用于以下場景:
-
用戶的人口統計信息的聚合操作(例如:青少年和中年人的習慣差異)。
-
當用戶超過一定時間沒有使用網站后,發郵件提醒他們。(這個一定時間的閾值是用戶自己預定義的)
-
分析用戶的瀏覽習慣。讓系統可以基于這個分析提示用戶有哪些網站特性還沒有使用到。進而形成一個反饋循環。
所有這些場景都要求將多個數據集連接起來。
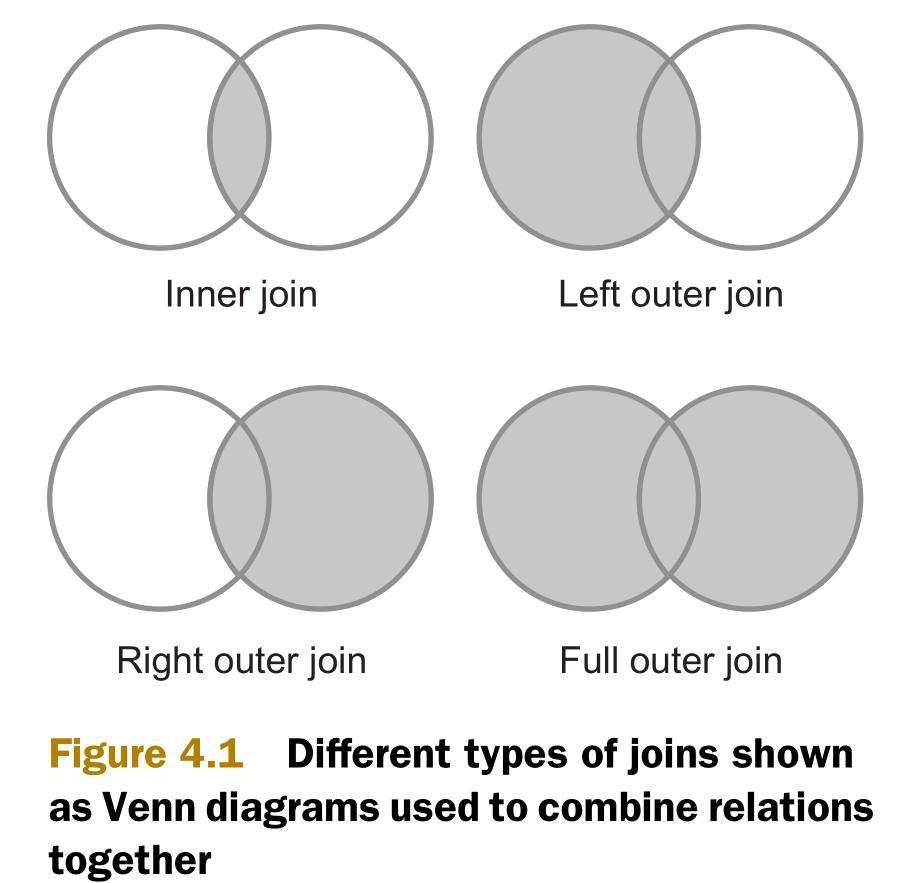
最常用的兩個連接類型是內連接(inner join)和外連接(outer join)。如下圖所示,內連接比較兩個關系中所有的元組,判斷是否滿足連接條件,然后生成一個滿足連接條件的結果集。與內連接相反的是,外連接并不需要兩個關系的元組都滿足連接條件。在連接條件不滿足的時候,外連接可以將其中一方的數據保留在結果集中。
為了實現內連接和外連接,MapReduce中有三種連接策略,如下所示。這三種連接策略有的在map階段,有的在reduce階段。它們都針對MapReduce的排序-合并(sort-merge)的架構進行了優化。
-
重分區連接(Repartition join)—— reduce端連接。使用場景:連接兩個或多個大型數據集。
-
復制連接(Replication join)—— map端連接。使用場景:待連接的數據集中有一個數據集足夠小到可以完全放在緩存中。
-
半連接(Semi-join)—— 另一個map端連接。使用場景:待連接的數據集中有一個數據集非常大,但同時這個數據集可以被過濾成小到可以放在緩存中。
在介紹完這些連接策略之后,還會介紹另一個策略:決策樹。可以根據實際情況選擇最優策略。
4.1.1 重分區連接(Repartition join)
重分區連接是reduce端連接。它利用MapReduce的排序-合并機制來分組數據。它只使用一個單獨的MapReduce任務,并支持多路連接(N-way join)。多路指的是多個數據集。
Map階段負責從多個數據集中讀取數據,決定每個數據的連接值,將連接值作為輸出鍵(output key)。輸出值(output value)則包含將在reduce階段被合并的值。
Reduce階段,一個reduce接收map函數傳來的每一個輸出鍵的所有輸出值,并將數據分為多個分區。在此之后,reduce對所有的分區進行笛卡爾積(Cartersian product)連接運算,并生成全部的結果集。
以上MapReduce過程如圖4.2所示:

|
注:過濾(filtering)和投影(projection) 在MapReduce重分區連接中,最好能夠減少map階段傳輸到reduce階段的數據量。因為通過網絡在這兩個階段中排序和傳輸數據會產生很高的成本。如果不能避免reduce端的工作,那么一個最佳實踐就是盡可能在map階段多過濾數據和投影。過濾指的是將map極端的輸入數據中不需要的部分丟棄。投影是關系代數的概念。投影用于減少發送給reduce的字段。例如:在分析用戶數據的時候,如果只關注用戶的年齡,那么在map任務中應該只投影(或輸出)年齡字段,不考慮用戶的其他的字段。 |
技術19:優化重分區連接
《Hadoop in Action》給出了一個例子,說明如何使用Hadoop的社區包(contrib package)org.apache.hadoop.contrib.utils.join實現重分區連接。這個貢獻包打包了所有的處理細節,僅僅需要實現一個非常簡單的方法。
然而,這個社區包對重分區的實現方法的空間效率低下。它需要將待連接的所有輸出值都讀取到內存中,然后進行多路連接(multiway join)。實際上,如果僅僅將小數據集讀取到內存中,然后用小數據集遍歷大數據集來進行連接,這樣將更加高效。
問題
需要在MapReduce中進行重分區連接,但是不希望在reduce階段將所有的數據都放到緩存中。
解決方案
這個技術運用了優化后的重分區框架。它僅僅將一個待連接的數據集放在緩存中,減少了reduce需要放在緩存中的數據。
討論
附錄D中介紹了優化后的重分區框架的實現。這個實現是根據org.apache.hadoop.contrib.utils.join社區包進行建模。這個優化后的框架僅僅緩存兩個數據集中比較小的那一個,以減少內存消耗。圖4.3是優化后的重分區連接的流程圖:
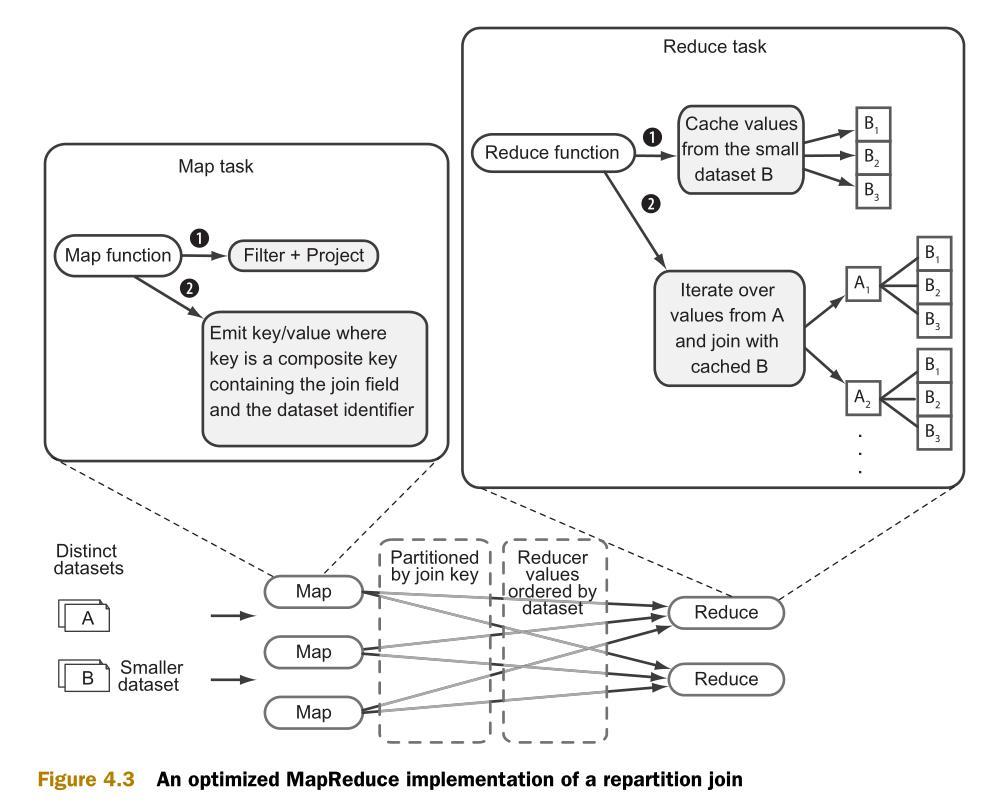
圖4.4是實現的類圖。類圖中包含兩個部分,一個通用框架和一些類的實現樣例。
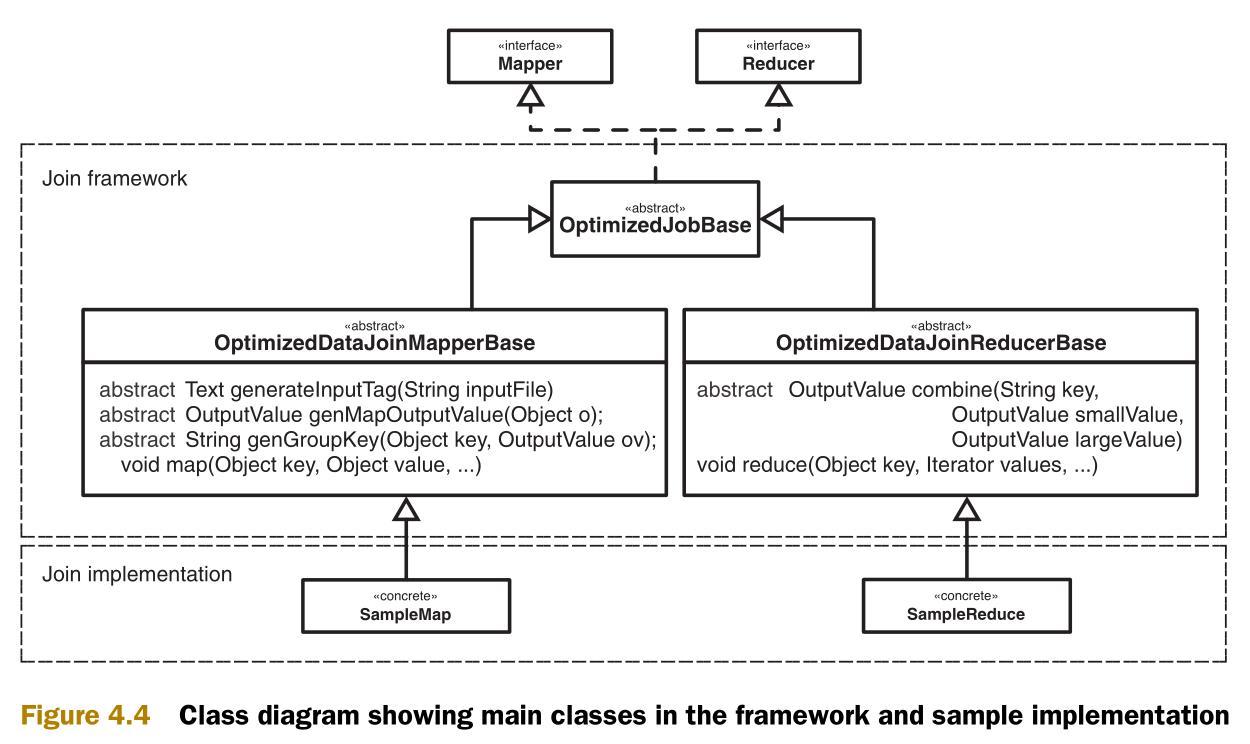
使用這個連接框架需要實現抽象類OptimizedDataJoinMapperBase和OptimizedDataJoinReducerBase。
例如,需要連接用戶詳情數據和用戶活動日志。第一步,判斷兩個數據集中那一個比較小。對于一般的網站來說,用戶詳情數據會比較小,用戶活動日志會比較大。
在如下示例中,用戶數據中有用戶姓名,年齡和所在州
- $ cat test-data/ch4/users.txt
- anne 22 NY
- joe 39 CO
- alison 35 NY
- mike 69 VA
- marie 27 OR
- jim 21 OR
- bob 71 CA
- mary 53 NY
- dave 36 VA
- dude 50 CA
用戶活動日志中有用戶姓名,進行的動作,來源IP。這個文件一般都要比用戶數據要大得多。
- $ cat test-data/ch4/user-logs.txt
- jim logout 93.24.237.12
- mike new_tweet 87.124.79.252
- bob new_tweet 58.133.120.100
- mike logout 55.237.104.36
- jim new_tweet 93.24.237.12
- marie view_user 122.158.130.90
首先,必須實現抽象類OptimizedDataJoinMapperBase。這個將在map端被調用。這個類將創建map的輸出鍵和輸出值。同時,它還將提示整個框架,當前處理的文件是不是比較小的那個。
- public class SampleMap extends OptimizedDataJoinMapperBase {
- private boolean smaller;
- @Override
- protected Text generateInputTag(String inputFile) {
- // tag the row with input file name (data source)
- smaller = inputFile.contains("users.txt");
- return new Text(inputFile);
- }
- @Override
- protected String genGroupKey(Object key, OutputValue output) {
- return key.toString();
- }
- @Override
- protected boolean isInputSmaller(String inputFile) {
- return smaller;
- }
- @Override
- protected OutputValue genMapOutputValue(Object o) {
- return new TextTaggedOutputValue((Text) o);
- }
- }
下一步,你需要實現抽象類 OptimizedDataJoinReducerBase。它將在reduce端被調用。在這個類中,將從map端傳入不同數據集的輸出鍵和輸出值,然后返回reduce端的輸出數組。
- public class SampleReduce extends OptimizedDataJoinReducerBase {
- private TextTaggedOutputValue output = new TextTaggedOutputValue();
- private Text textOutput = new Text();
- @Override
- protected OutputValue combine(String key,
- OutputValue smallValue,
- OutputValue largeValue) {
- if(smallValue == null || largeValue == null) {
- return null;
- }
- Object[] values = {
- smallValue.getData(), largeValue.getData()
- };
- textOutput.set(StringUtils.join(values, "\t"));
- output.setData(textOutput);
- return output;
- }
最后,任務的主代碼(driver code)需要指明InputFormat類,并設置次排序(Secondary sort)。
- job.setInputFormat(KeyValueTextInputFormat.class);
- job.setMapOutputKeyClass(CompositeKey.class);
- job.setMapOutputValueClass(TextTaggedOutputValue.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setPartitionerClass(CompositeKeyPartitioner.class);
- job.setOutputKeyComparatorClass(CompositeKeyComparator.class);
- job.setOutputValueGroupingComparator(CompositeKeyOnlyComparator.class);
現在連接的準備工作就做完了,可以開始運行連接:
- $ hadoop fs -put test-data/ch4/users.txt users.txt
- $ hadoop fs -put test-data/ch4/user-logs.txt user-logs.txt
- $ bin/run.sh com.manning.hip.ch4.joins.improved.SampleMain users.txt,user-logs.txt output
- $ hadoop fs -cat output/part*
- bob 71 CA new_tweet 58.133.120.100
- jim 21 OR logout 93.24.237.12
- jim 21 OR new_tweet 93.24.237.12
- jim 21 OR login 198.184.237.49
- marie 27 OR login 58.133.120.100
- marie 27 OR view_user 122.158.130.90
- mike 69 VA new_tweet 87.124.79.252
- mike 69 VA logout 55.237.104.36
如果和連接的源文件相對比,可以看到因為實現了一個內連接,輸出中不包括用戶anne,alison等不存在于日志文件中的記錄。
小結:
這個連接的實現通過只緩存比較小的數據集來提高來Hadoop社區包的效率。但是,當數據從map階段傳輸到reduce階段的時候,仍然產生了很高的網絡成本。
此外,Hadoop社區包支持多路連接,這里的實現只支持二路連接。
如果要更多地減少reduce端連接的內存足跡(memory footprint),一個簡單的機制是在map函數中更多地進行投影操作。投影減少了map階段的輸出中的字段。例如:在分析用戶數據的時候,如果只關注用戶的年齡,那么在map任務中應該只投影(或輸出)年齡字段,不考慮用戶的其他的字段。這樣就減少了map和reduce之間的網絡負擔,也減少了reduce在連接時的內存消耗。
和原始的社區包一樣,這里的重分區的實現也支持過濾和投影。通過允許genMapOutputValue方法返回空值,就可以支持過濾。通過在genMapOutputValue方法中定義輸出值的內容,就可以支持投影。
如果你既想輸出所有的數據到reduce,又想避免排序的損耗,就需要考慮另外兩種連接策略,復制連接和半連接。
附錄D 優化后的MapReduce連接框架
在這個附錄,我們將討論在第4張中使用的兩個連接框架。第一個是重連接框架。它減少了org.apache.hadoop.contrib.utils.join包的實現的Hadoop連接的內存足跡。第二個是復制連接框架。它可以將較小的數據集放在緩存中。
D.1 優化后的重分區框架
Hadoop社區連接包需要將每個鍵的所有值都讀取到內存中。如何才能在reduce端的連接減少內存開銷呢?本文提供的優化中,只需要緩存較小的數據集,然后在連接中遍歷較大數據集中的數據。這個方法中還包括針對map的輸出數據的次排序,那么reducer先接收到較小的數據集,然后接收到較大的數據集。圖D.1是這個過程的流程圖。

圖D.2是實現的類圖。類圖中包含兩個部分,一個通用框架和一些類的實現樣例。
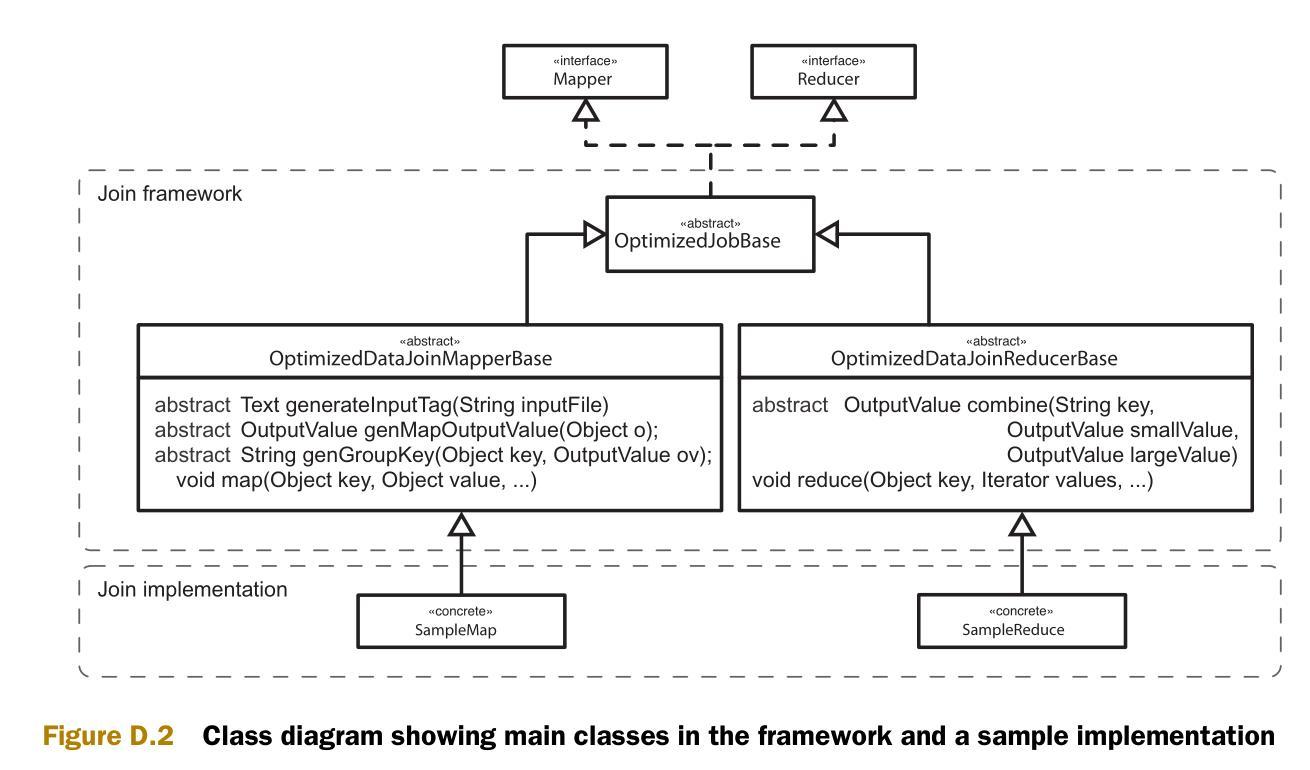
連接框架
我們以和Hadoop社區連接包的近似的風格編寫連接的代碼。目標是創建可以處理任意數據集的通用重分區機制。為簡潔起見,我們重點說明主要部分。
首先是OptimizedDataJoinMapperBase類。這個類的作用是辨認出較小的數據集,并生成輸出鍵和輸出值。Configure方法在mapper創建時被調用。Configure方法的作用之一是標識每一個數據集,讓reducer可以區分數據的源數據集。另一個作用是辨認當前的輸入數據是否是較小的數據集。
- protected abstract Text generateInputTag(String inputFile);
- protected abstract boolean isInputSmaller(String inputFile);
- public void configure(JobConf job) {
- this.inputFile = job.get("map.input.file");
- this.inputTag = generateInputTag(this.inputFile);
- if(isInputSmaller(this.inputFile)) {
- smaller = new BooleanWritable(true);
- outputKey.setOrder(0);
- } else {
- smaller = new BooleanWritable(false);
- outputKey.setOrder(1);
- }
- }
Map方法首先調用自定義的方法 (generateTaggedMapOutput) 來生成OutputValue對象。這個對象包含了在連接中需要使用的值(也可能包含了最終輸出的值),和一個標識較大或較小數據集的布爾值。如果map方法可以調用自定義的方法 (generateGroupKey) 來得到可以在連接中使用的鍵,那么這個鍵就作為map的輸出鍵。
- protected abstract OptimizedTaggedMapOutput generateTaggedMapOutput(Object value);
- protected abstract String generateGroupKey(Object key, OptimizedTaggedMapOutput aRecord);
- public void map(Object key, Object value, OutputCollector output, Reporter reporter)
- throws IOException {
- OptimizedTaggedMapOutput aRecord = generateTaggedMapOutput(value);
- if (aRecord == null) {
- return;
- }
- aRecord.setSmaller(smaller);
- String groupKey = generateGroupKey(aRecord);
- if (groupKey == null) {
- return;
- }
- outputKey.setKey(groupKey);
- output.collect(outputKey, aRecord);
- }
圖D.3 說明了map輸出的組合鍵(composite 可以)和組合值。次排序將會根據連接鍵(join key)進行分區,并用整個組合鍵來進行排序。組合鍵包括一個標識源數據集(較大或較小)的整形值,因此可以根據這個整形值來保證較小源數據集的值先于較大源數據的值被reduce接收。
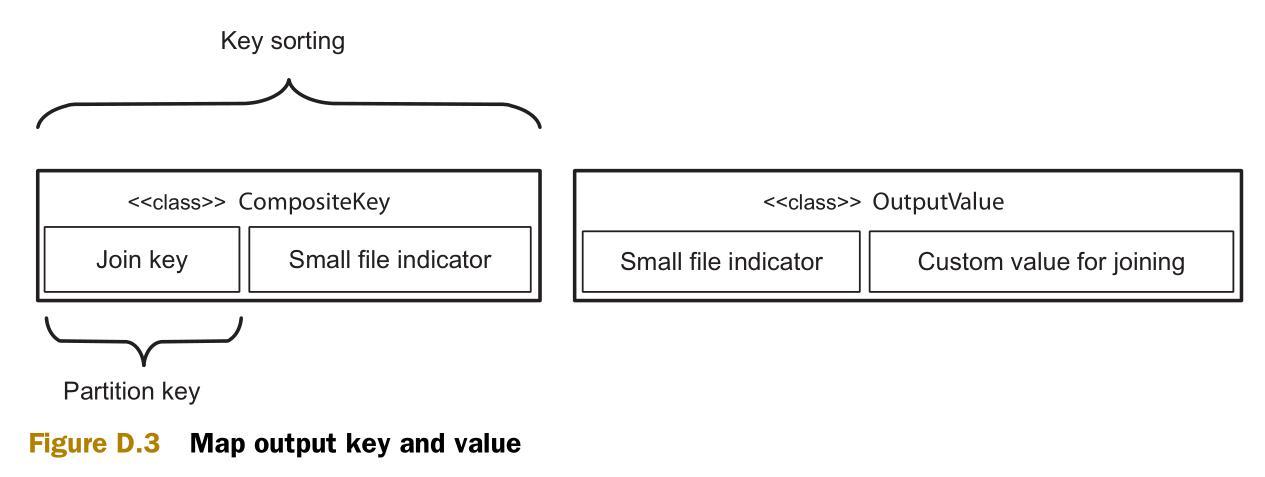
下一步是深入reduce。此前已經可以保證較小源數據集的值將會先于較大源數據集的值被接收。這里就可以將所有的較小源數據集的值放到緩存中。在開始接收較大源數據集的值的時候,就開始和緩存中的值做連接操作。
- public void reduce(Object key, Iterator values, OutputCollector output, Reporter reporter)
- throws IOException {
- CompositeKey k = (CompositeKey) key;
- List<OptimizedTaggedMapOutput> smaller = new ArrayList<OptimizedTaggedMapOutput>();
- while (values.hasNext()) {
- Object value = values.next();
- OptimizedTaggedMapOutput cloned =((OptimizedTaggedMapOutput) value).clone(job);
- if (cloned.isSmaller().get()) {
- smaller.add(cloned);
- } else {
- joinAndCollect(k, smaller, cloned, output, reporter);
- }
- }
- }
方法joinAndCollect包含了兩個數據集的值,并輸出它們。
- protected abstract OptimizedTaggedMapOutput combine(
- String key,
- OptimizedTaggedMapOutput value1,
- OptimizedTaggedMapOutput value2);
- private void joinAndCollect(CompositeKey key,
- List<OptimizedTaggedMapOutput> smaller,
- OptimizedTaggedMapOutput value,
- OutputCollector output,
- Reporter reporter)
- throws IOException {
- if (smaller.size() < 1) {
- OptimizedTaggedMapOutput combined = combine(key.getKey(), null, value);
- collect(key, combined, output, reporter);
- } else {
- for (OptimizedTaggedMapOutput small : smaller) {
- OptimizedTaggedMapOutput combined = combine(key.getKey(), small, value);
- collect(key, combined, output, reporter);
- }
- }
- }
這些就是這個框架的主要內容。
原文鏈接:http://www.cnblogs.com/datacloud/p/3578509.html